
RISC-V Supervisor-Level ISA
12. Supervisor-Level ISA, Version 1.13
本篇為 RISC-V Supervisor-Level ISA(Version 20241101)的中文翻譯與筆記,原文可於官方 github 的第 12 章中看到。 大部分的情況下我會直接直譯,但有些地方我覺得文件實在寫得很繞,那種地方我就會直接用我自己的話寫了,或是多補一個 Tips Block 做解釋
本篇內的 Info block 為原文中的補充段落,我全部都有翻,但會依照前後文的語境來決定要不要安插 Info block 進來,也就是說雖然本文中有些段落不在藍色的 Info 區塊內,但在原文中其屬於補充段落。 至於綠色的 Tips block 則是我個人的補充筆記
12.1. Supervisor CSRs
S-mode 無法窺探或取得任何來自更高 privilege mode(如 M-mode)的結構或資訊。 許多 supervisor-level 的 CSR 是對應的 M-mode CSR 的子集,因此為了理解 supervisor-level CSR 的描述,應該先閱讀 machine-mode 章節
12.1.1. Supervisor Status (sstatus) Register
sstatus 暫存器是一個 SXLEN-bit read/write 的暫存器,用來追蹤處理器目前的狀態,其為 mstatus 的子集
當 SXLEN 為 32 時,格式如下圖:

當 SXLEN 為 64 時格式如下圖:
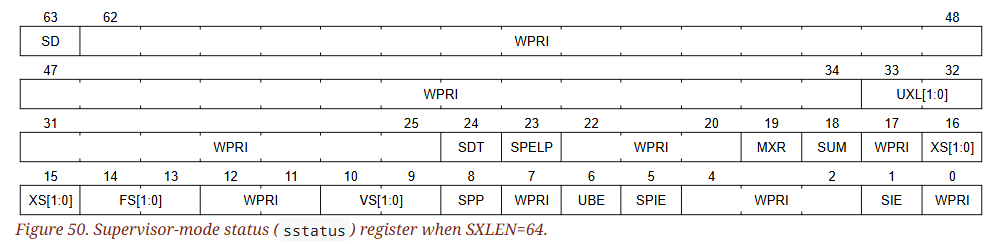
SPPSPP位元表示 hart 在進入 S-mode 之前執行的特權等級- 當 Trap 發生時,如果其源自 U-mode,則
SPP設定為 0,否則為 1 - 當執行
SRET指令從 trap handler 返回時- 如果
SPP為 0,則特權等級會被設為 U-mode - 否則設為 S-mode 並將
SPP設為 0
- 如果
SIE- 用來啟用或禁用 S-mode 下的所有中斷
- 清 0 時 S-mode 下不會產生中斷
- 如果 hart 運行在 U-mode,
SIE的值會被忽略,且會啟用 S-mode 的中斷 - supervisor 可以利用
sieCSR 來停用單一的中斷來源
- 用來啟用或禁用 S-mode 下的所有中斷
SPIE- 用來記錄在進入 S-mode 之前是否啟用了 S-mode 下的中斷
- 當 Trap 進入 S-mode 時,
SPIE被設為SIE,並且SIE被設為 0 - 執行
SRET指令時,SIE被設為SPIE,然後SPIE被設為 1
Info
在較簡單的實作中,讀取或寫入 sstatus 中的任何字段相當於讀取或寫入 mstatus 中的同名字段
12.1.1.1. Base ISA Control in sstatus Register
UXL 欄位控制 U-mode 的 XLEN 值,稱為 UXLEN,其可能與 S-mode 的 XLEN 值不同(稱為 SXLEN)。 簡單來說:
UXLEN表示 U-mode 的位元寬度,決定 U-mode 下的有效位址長度SXLEN表示 S-mode 或 M-mode 下的位元寬度,決定系統支援的完整位址空間
UXL 的編碼與 misa 內的 MXL 相同,MXL 的編碼如下表:
| MXL | XLEN |
|---|---|
| 1 | 32 |
| 2 | 64 |
| 3 | 128 |
當 SXLEN 為 32 時,UXL 欄位不存在,此時 UXLEN 為 32。 當 SXLEN 為 64 時,它是一個 WARL 字段,值為當前 UXLEN 值的編碼。 具體來說,UXL 可能被實作為一個唯讀的字段,其值始終保證 UXLEN = SXLEN
如果 UXLEN ≠ SXLEN,則在 narrower mode 下執行的指令必須忽略配置的 XLEN 以上的來源暫存器運算元,並且必須對結果進行 sign-extend 以填充目標暫存器中最寬的 XLEN
如果 UXLEN < SXLEN,U-mode 下的 instruction-fetch 位址,和 load/store 的有效位址以
舉個例子,當 UXLEN 為 32,SXLEN 為 64 的情況下,U-mode 下的程式無論怎麼操作記憶體,都只能看到低 4GiB 的記憶體範圍,換句話說 U-mode 的記憶體存取是 32 位元位址空間內的操作,而不是完整的 64 位元位址空間
Tips
HINT 相關
HINT 指令是沒有實際運算效果,但可能被用來提供某些優化或調整的指令。 某些 HINT 指令會被編碼為整數計算指令,其會利用當下的值覆蓋目標暫存器值
此時若 XLEN < SXLEN 且目標暫存器 SXLEN .. XLEN 處的位元與 XLEN - 1 處的不一致,則目標暫存器 SXLEN .. XLEN 處的位元會依照 implementation-defined 的方式,將其值保留或以 XLEN - 1 處的位元延展覆蓋
舉個例子,例如 c.addi x8, 0 這個指令,其等同於 addi x8 x8 0,也就是 x8 = x8,這是一個 HINT 指令,對計算沒有影響。 假設 U-mode 運行在 XLEN = 32,但暫存器是 64 位元的(SXLEN = 64),而假設目標暫存器 x8 的內容如下:
64-bit register (SXLEN=64, XLEN=32)
┌──────────────────────────┬────────────────────────┐
│ 高 32 位元 (SXLEN..XLEN) │ 低 32 位元 (XLEN) │
│ 0xF0000000 │ 0x12345678 │
└──────────────────────────┴────────────────────────┘其中低 32 位元(0x12345678) 是有效值,而高 32 位元(0xF0000000) 是超出 XLEN 的部分,內容可能來自之前的運算
當執行 HINT 指令 c.addi x8, 0 時
- 低 32 位元(
XLEN) 會保持不變(0x12345678) - 高 32 位元(
SXLEN..XLEN) 有兩種可能的行為:- 不變,保持
0xF0000000 - 以
XLEN-1位元的值延展覆蓋為0x00000000
- 不變,保持
這允許實作上省略 HINT 指令中目標暫存器的寫回(writeback),其也可以選擇將部分 HINT 指令像一般整數運算指令一樣執行。 這種選擇只會影響到 S-mode 下 SXLEN > UXLEN 的情況,對 U-mode 來說這個行為完全不可見
一般的整數運算指令(如 addi x8, 0) 都會:
- 讀取
x8的值 - 執行計算(這裡是
+0,所以結果不變) - 寫回
x8
但對於 HINT 指令,CPU 可以選擇「完全不寫回 x8」,因為它不影響計算結果
12.1.1.2. Memory Privilege in sstatus Register (MXR 與 SUM)
MXR(Make eXecutable Readable) 位元控制讀取(load) 虛擬記憶體的權限
MXR = 0- 只允許讀取標記為可讀(
R=1)的 page
- 只允許讀取標記為可讀(
MXR = 1- 允許讀取可讀(
R=1) 或可執行(X=1) 的 page
- 允許讀取可讀(
當 page-based 的虛擬記憶體未啟用時(satp.MODE = Bare),MXR 沒有作用
SUM(permit Supervisor User Memory access) 位元控制 S-mode 下存取 U-mode page 的權限
SUM = 0- S-mode 無法存取 「U-mode 可存取(
U=1)」的 page - 如果嘗試存取,會產生錯誤(fault)
- S-mode 無法存取 「U-mode 可存取(
SUM = 1- 允許 S-mode 存取
U=1的 page
- 允許 S-mode 存取
當 paged-based 的虛擬記憶體未啟用,或者運行在 U-mode 時,SUM 沒有作用。 另外無論 SUM 的狀態為何,S-mode 下都無法執行 U-mode page 中的指令
如果 satp.MODE 是唯讀的 0(satp.MODE=0),則 SUM 也是唯讀的 0,這表示在不支援 page 的系統上,S-mode 永遠無法存取 U-mode 記憶體
page table entry 可以參考下圖(Sv32 page table entry)

SUM 的機制可以防止 S-mode 下的軟體意外存取 user memory,作業系統可以在 SUM=0 的情況下執行大部分的程式碼,並在少數需要訪問 user memory 的情況下再暫時設定 SUM
SUM 的機制不允許 S-mode 軟體執行 user code pages 中的指令。 但這在其他場景下通常也是個不合法的操作,在 POSIX 環境中也禁止 S-mode 執行 U-mode memory page 中的指令,因為如果 S-mode 中存在任意代碼執行(Arbitrary Code Execution, ACE) 的漏洞,那麼這類漏洞將變得更容易被利用,特別是當攻擊者能夠將惡意代碼存放在 U-mode 可存取的記憶體(user buffer) 並在攻擊過程中執行它
但是有些 non-POSIX 的單一位址空間(Single Address Space) 作業系統允許部分軟體在 S-mode 下執行 U-mode program,其大部分程式都運行在 U-mode 下,並和 kernel 共用同一個位址空間。 在這種情況下,可以通過映射相同的物理記憶體到不同的虛擬記憶體 page,並設定不同的權限來允許 S-mode 軟體部分執行 U-mode 的程式碼
12.1.1.3. Endianness Control in sstatus Register (UBE)
UBE 為原是個 WARL 的字段,用來控制 U-mode 下記憶體存取的位元組順序(Endianness),其可能與 S-mode 下的位元組順序不同。 實作上可能會把 UBE 設成一個唯讀的字段,使其始終與 S-mode 的位元組順序相同
UBE = 0:使用小端序(little-endian)UBE = 1:使用大端序(big-endian)
另外
- instruction-fetch 不受
UBE的影響- 其屬於隱式(implicit) 記憶體存取,永遠是小端序(little-endian)
UBE不影響 S-mode 相關的隱式記憶體存取- 如 S-mode 讀取 page table 或其他記憶體管理資料結構,這些記憶體存取總是使用 S-mode 的位元組順序
標準的 RISC-V ABI 只能是純小端(Little-Endian, LE) 或純大端(Big-Endian, BE),不允許混合大小端(mixing endianness)。 儘管標準 ABI 只能是純 LE 或純 BE,但 RISC-V 還是允許作業系統支援與自身大小端不同的 U-mode 應用程式
12.1.1.4. Previous Expected Landing Pad (ELP) State in sstatus Register
SPELP 欄位由 Zicflip 擴充指令集引入,用途與控制流完整性(CFI) 有關。 在 S-mode 下存取 SPELP 欄位時,會根據 V 位元的狀態來決定要存取 mstatus.SPELP 還是 vsstatus.SPELP:
V=0(非虛擬化模式):存取mstatus.SPELPV=1(虛擬化模式):存取vsttatus.SPELP
12.1.1.5. Double Trap Control in sstatus Register
SDT(S-mode-disable-trap) 是一個 WARL 的欄位,由 Ssdbltrp 擴充指令集引入,用來解決 S-mode 以下 double trap 的問題
Tips
double trap 指的是,當 Trap handler 正在處理異常(Trap) 且正處於 non-reentrant 的狀態時,發生了另一個異常,導致其無法正常處理
當 SDT 位元透過 CSR write 顯式設為 1 時,無論該操作是否在同一寫入中試圖設定 SIE,SIE 都會被強制清 0,這代表 S-mode 將無法接受中斷。 而執行 SRET 指令 SDT 會被清 0
SIE=1 只能發生在 SDT=0 的情況下,如果 SDT=1,則 SIE 無法手動設為 1,這確保在 SDT=1 時 S-mode 不會收到新的中斷
當系統發生異常(Trap) 時,如果 SDT=0,則 SDT 會被自動設定為 1,之後異常會正常傳遞到 S-mode。 然而如果 SDT 已經是 1(代表 S-mode 已經在處理異常),則這是一個意外異常(unexpected trap),當意外異常發生時,其會產生「Double-Trap Exception」,以將意外異常傳遞給 M-mode 處理
之後會由 M-mode 接管處理該異常,期間 hart 會將該異常的資訊寫入對應的暫存器,但 mcause 和 mtval2 例外,mtval2 會存入「原本應該寫入 mcause 的值」,mcause 會被設為 16,代表這是一個 double-trap exception,好讓 M-mode 可以識別這是一個 S-mode 無法處理的異常
Trap handler 需要在儲存好 scause、sepc、stval 等狀態,並且可重入(reentrant) 後清除 SDT 位元,這表示在 Trap handler 的尾聲,如果在恢復系統狀態時又發生了新的異常,SDT 可以幫助 M-mode 檢測到這種情況
如果 guest OS 發生 page-fault,而這個異常觸發了 double trap,那麼當其被遞交到 M-mode 時,mtval2 暫存器將不會包含 Guest Physical Address(GPA),這代表 Hypervisor 無法直接從 mtval2 取得 guest 的物理位址。 這會發生在 HS-mode 下執行虛擬機內的存取指令(load 或 store),且
SDT=1- 該存取指令導致了 guest page-fault
時,不過這不常發生。 另外,儘管 GPA 不會被記錄,但這沒關係,需要的話仍可以通過走訪 page table 來達成目的
對於源自 VS-mode 的 double trap,M-mode 應該要將該異常重新導向到 HS-mode,具體做法是:
- 將 M-mode 處理該異常時更新的 CSR 的值複製到 HS-mode 中對應的 CSR
- 使用
MRET指令恢復執行,並從stvec指定的位址繼續執行
SSE(Supervisor Software Events) 是 SBI(Supervisor Binary Interface) 的一項擴充,提供一種機制,使監督者軟體(Supervisor Software) 能夠註冊(register) 並處理(service) 來自 SBI 實作的系統事件。 這些事件可能來自 SBI 內部,例如韌體或 Hypervisor
當發生 double trap 時,HS-mode 和 M-mode 可以使用 SSE 機制來啟動 critical-error handler 以處理對應的 VS-mode 或 S/HS-mode 中發生的異常。 此外,實作 SSE protocol 也可以做為一個選項,幫助系統從這類 critical errors 中恢復
12.1.2. Supervisor Trap Vector Base Address (stvec) Register
stvec 是一個 SXLEN-bit 的可讀寫暫存器,用來存 trap vector 的設定,包含:
- vector base address (
BASE) - vetor mode (
MODE)
決定進入 S-mode 下的異常(Exception) 和中斷(Interrupt) 後 PC 該跳轉到哪裡,配置方式如下圖:

BASE 欄位可以存放任何有效的虛擬位址或實體位址,但需符合以下對齊限制:
- 該位址必須以 4-byte 對齊(最低兩個位元為 0)
- 若
MODE不是 Direct,可能還會有更嚴格的對齊限制作用在BASE的值上- 在 VECTORED 模式下,因為 trap vector 會根據中斷號(cause) 來做位址計算(例如
BASE + 4×cause),因此位址可能要符合更高的要求
- 在 VECTORED 模式下,因為 trap vector 會根據中斷號(cause) 來做位址計算(例如
下表為 stvec.MODE 的編碼方式:
| Value | Name | Description |
|---|---|---|
| 0 | Direct | All exceptions set pc to BASE. |
| 1 | Vectored | Asynchronous interrupts set pc to BASE+4×cause. |
| ≥2 | Reserved |
當 MODE=Direct 時,所有 traps 進入 S-mode 都會將 pc 設為 BASE 欄位中的位址
而當 MODE=Vectored 時,所有同步異常(synchronous exceptions) 在進入 S-mode 後,pc 依舊會設為 BASE; 但如果是中斷 ,則 pc 會設為 BASE + 4×cause
例如 Supervisor-mode 計時器中斷在 RISC-V 中通常是 cause = 5(參考具體標準),所以 pc = BASE + (4×5) = BASE + 0x14
為了讓 pc = BASE + 4×cause 不越界或錯亂,一般會要求 BASE 有更高的對齊要求,比如 16-byte 或 128-byte 對齊,具體要看實作和規範版本
12.1.3. Supervisor Interrupt (sip and sie) Registers
sip 暫存器是一個 SXLEN-bit 的可讀寫暫存器,其內容代表當前等待處理(pending) 的中斷資訊
sie 暫存器則是對應的 SXLEN-bit 的可讀寫暫存器,其中記錄啟用中斷的位元
其中在 scause CSR 裏面所報告的中斷原因編號 i(參考第 12.1.8 節)對應到 sip 與 sie 的第 i 個位元
位元 0~15(bits 15:0) 保留給標準中斷原因(例如軟體中斷、計時器中斷等),16 以上的位元則留給平台自行使用

一個編號為 i 的中斷,只有在以下兩個條件都成立時,才會陷入到 S-mode 進行處理:
- (a)
- 當前特權模式是 S-mode,並且
sstatus暫存器裡的SIE位元為 1 - 或是當前特權模式低於 S-mode(也就是 U-mode 等更低特權模式)
- 當前特權模式是 S-mode,並且
- (b)
sip[i]與sie[i]都為 1,也就是該中斷i已被啟用且正在等待處理
硬體(或實作) 在偵測到 sip[i] 發生變化(例如 0→1)時,應該在合理且有限的時間內檢查是否要觸發中斷,不能無限制地拖延,否則中斷就失去意義了
同時,也必須在執行 SRET 指令之後,以及對任何會影響中斷陷阱條件的 CSR(例如 sip, sie, sstatus)進行「顯式寫入(explicit write)」後,立即重新評估這些條件
對 S-mode 的中斷優先於對任何更低特權模式(例如 U-mode)的中斷
在 sip 暫存器中,每個位元都可能是可寫,也可能是唯讀的,當第 i 位元是可寫的時,如果中斷 i 處於 pending 狀態,可以透過寫入 0 到此位元的方式來清除該中斷
如果一個中斷 i 可能處於等待狀態,但是 sip 中該位元是唯讀的,那麼必須由實作提供其他機制來清除該 pending 中斷(可能需要透過呼叫執行環境(execution environment) 的某種方法)
在 sie 暫存器中,如果對應的中斷可能變成 pending 的,那麼該位元就必須是可寫的。 若某些位元是不可寫的,那它們就會是唯讀的,且永遠為 0(該中斷永遠不會發生)
sip 與 sie 的 標準部分(bits 15:0),格式如下圖所示:
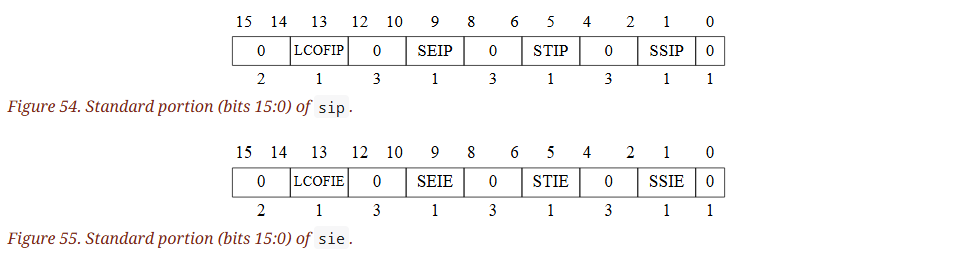
sip.SEIP 與 sie.SEIE 對應到 S-mode 外部中斷(supervisor-level external interrupts) 的「等待(pending)」與「啟用(enable)」位。 若實作了此功能,則 sip 中的 SEIP 是唯讀的,它的設置和清除由執行環境(通常透過平台特定的中斷控制器)來完成
sip.STIP 與 sie.STIE 對應到 S-mode 計時器中斷(timer interrupt) 的「等待」與「啟用」位。 若實作了此功能,則 sip 中的 STIP 是 唯讀,由執行環境來設置或清除
sip.SSIP 與 sie.SSIE 對應到 S-mode 軟體中斷(software interrupt) 的「等待」與「啟用」位。 若系統實作該功能,sip 中的 SSIP 是 可寫的,也可能由平台特定的中斷控制器設置為 1
Tips
外部中斷往往是由硬體控制器(PIC, PLIC, etc.) 來管理,S-mode 只能透過平台特定的方法去清除 pending。 計時器中斷通常也是由硬體或韌體自動管理,軟體無法直接清除 pending,故 STIP 是唯讀的
若系統實作了 Sscofpmf 擴充,則 sip.LCOFIP 與 sie.LCOFIE 這些位元對應到 local counter-overflow interrupt 的等待與啟用。 sip.LCOFIP 在 sip 中是可讀寫(read-write),當 mhpmeventn.OF 中任何一個位元被設置(表示計數器溢出)時,就會反映成一個 local counter-overflow interrupt。 如果 Sscofpmf 未實作,那麼 sip.LCOFIP 與 sie.LCOFIE 是唯讀的且永遠為 0
Tips
Sscofpmf(Supervisor Software Counter Overflow Performance Monitoring):一種專門的擴充,用於監測計數器溢出事件
Info
跨處理器中斷(Interprocessor interrupts) 是透過特定的實作方式發送到其他 hart,最終會使接收端 hart 的 sip 暫存器中的 SSIP 位元被設為 1
每一種標準中斷類型(SEI、STI、SSI、或 LCOFI)都可能不被實作;如果沒有實作,對應的等待與啟用位就會是唯讀且為 0 的
sip 與 sie 中的所有位元都是 WARL 欄位,可透過在 sie 暫存器的每個位元都寫入 1,然後再讀回來檢查哪個位元真的保持在 1,就能得知系統實際實作了哪些中斷
Info
sip 與 sie 是 mip 與 mie 的子集,讀取或寫入 sip/sie 的任何已實作欄位,同時也會對應到 mip/mie 裡的相同欄位,也就是說當你寫 sip.SSIP=1,實際硬體也會把 mip.SSIP 做相應設定
在 sip 與 sie 中的第 3、7 和 11 個 bit,分別對應 M-mode 的軟體、計時器與外部中斷。 由於大多數平台都選擇不將這些中斷從 M-mode 委派(delegate) 到 S-mode,所以在圖 54 與圖 55 中,這些位元顯示為 0
當同時有多個要進入 S-mode 的中斷發生時,其處理順序(由高至低優先權)如下:
- SEI (Supervisor External Interrupt)
- SSI (Supervisor Software Interrupt)
- STI (Supervisor Timer Interrupt)
- LCOFI (Local Counter Overflow Interrupt)
12.1.4. Supervisor Timers and Performance Counters
S-mode 和 U-mode 使用相同的硬體效能監控機制(hardware performance monitoring facility),其中包含 time、cycle 和 instret 這些 CSR,實作應提供機制來修改這些計數器的值
另外,實作必須提供一種機制,讓系統能夠依據真實時間計數器來 schedule 計時器中斷
12.1.5. Counter-Enable (scounteren) Register

scounteren 是一個 32 位元 的 CSR,控制 U-mode 是否能存取硬體效能監控計數器(hardware performance monitoring counters)
如果在 scounteren 暫存器中,CY、TM、IR 或 HPMn 其中任意一個位元被清為 0,那麼當 U-mode 嘗試讀取對應的 cycle、time、instret 或 hpmcountern 暫存器時,將會觸發非法指令(illegal-instruction) 異常。 若當中有位元為 1,則允許 U-mode 讀取對應的計數器
對應關係:
CYbit:控制 cycle 暫存器(CPU 週期計數器)TMbit:控制 time 暫存器(實時計數器)IRbit:控制 instret 暫存器(指令完成數計數器)HPMnbits:控制 hpmcountern(高階性能計數器)
系統必須實作 scounteren 暫存器,但其內的任何位元都可以為唯讀的 0,表示在 U-mode 下讀取對應計數器時會產生異常。 因此,這些位元等同於 WARL 欄位
Info
在 mcounteren(M-mode 的 counter-enable)中某一個位元的設定,並不會影響對應的 scounteren 位元是否可寫
不過,若 U-mode 想要讀取某個計數器,scounteren 與 mcounteren 中的對應位元都必須為 1
12.1.7. Supervisor Exception Program Counter (sepc) Register
sepc 是一個 SXLEN 位元的可讀寫 CSR,其格式如下圖所示:

sepc 的最低位元(sepc[0]) 永遠為 0。 如果某個處理器實作只支援 IALIGN=32 (指令對齊為 32 位元),那麼 sepc 的最低兩個位元(sepc[1:0]) 都會是 0
如果某個處理器支援 IALIGN=16 或 IALIGN=32(例如透過修改 misa CSR 來切換),那麼在 IALIGN=32 的狀態下讀取 sepc 時,sepc[1] 會被遮罩(mask) 為 0,因此看起來總會為 0。 這種遮罩行為也會在 SRET 指令內對 sepc 的隱式讀取時發生。 另外,即便在 IALIGN=32 模式下被遮罩,sepc[1] 仍然是可寫的
sepc 是一個 WARL 類型的暫存器,必須能夠存放所有合法虛擬位址,但不需要能存放「所有可能的無效位址」。 在寫入 sepc 之前,處理器實作可能會把某個無效位址轉換成另一個它可以容納的無效位址,然後再存進 sepc
當透過 trap 進入 S-mode 時,硬體會把被中斷的指令(或遇到異常的指令) 的虛擬位址寫入 sepc。 除此之外,硬體不會自行寫入 sepc,但軟體可以顯式地對它寫入
12.1.8. Supervisor Cause (scause) Register
scause(Supervisor Cause) 是一個 SXLEN 位元的可讀寫 CSR,其格式如下圖所示:

當透過 trap 進入 S-mode 時,硬體會將造成 trap 的事件代碼(code) 寫入 scause。 除此之外,硬體不會自行改寫 scause,但軟體可以顯式地對它寫入
在 scause 暫存器中,有一個稱作 Interrupt bit 的位元,如果 trap 是由中斷(interrupt) 造成,這個位元就會被設為 1。 scause 中還有一個 Exception Code(異常碼) 的欄位,用來標示最後一次異常或中斷的代碼
異常碼是一個 WLRL 欄位,它至少需要支援 0~31 的取值(也就是位元 4-0 必須實作),超過 31 的值,硬體可自行決定是否支援,或以其他方式處理
下表列出了目前標準定義的 S-mode 指令集中可能出現的異常碼
Supervisor cause (scause) register values after trap:
| Interrupt | Exception Code | Description |
|---|---|---|
| 1 | 0 | Reserved |
| 1 | 1 | Supervisor software interrupt |
| 1 | 2-4 | Reserved |
| 1 | 5 | Supervisor timer interrupt |
| 1 | 6-8 | Reserved |
| 1 | 9 | Supervisor external interrupt |
| 1 | 10-12 | Reserved |
| 1 | 13 | Counter-overflow interrupt |
| 1 | 14-15 | Reserved |
| 1 | ≥16 | Designated for platform use |
| 0 | 0 | Instruction address misaligned |
| 0 | 1 | Instruction access fault |
| 0 | 2 | Illegal instruction |
| 0 | 3 | Breakpoint |
| 0 | 4 | Load address misaligned |
| 0 | 5 | Load access fault |
| 0 | 6 | Store/AMO address misaligned |
| 0 | 7 | Store/AMO access fault |
| 0 | 8 | Environment call from U-mode |
| 0 | 9 | Environment call from S-mode |
| 0 | 10-11 | Reserved |
| 0 | 12 | Instruction page fault |
| 0 | 13 | Load page fault |
| 0 | 14 | Reserved |
| 0 | 15 | Store/AMO page fault |
| 0 | 16-17 | Reserved |
| 0 | 18 | Software check |
| 0 | 19 | Hardware error |
| 0 | 20-23 | Reserved |
| 0 | 24-31 | Designated for custom use |
| 0 | 32-47 | Reserved |
| 0 | 48-63 | Designated for custom use |
| 0 | ≥64 | Reserved |
Synchronous Exception Priority:
| Priority | Exc. Code | Description |
|---|---|---|
| Highest | 3 | Instruction address breakpoint |
| 12, 1 | During instruction address translation: First encountered page fault or access fault | |
| 1 | With physical address for instruction: Instruction access fault | |
| 2 | Illegal instruction | |
| 0 | Instruction address misaligned | |
| 8, 9, 11 | Environment call | |
| 3 | Environment break | |
| 3 | Load/store/AMO address breakpoint | |
| 4, 6 | Optionally: Load/store/AMO address misaligned | |
| 13, 15, 5, 7 | During address translation for an explicit memory access: First encountered page fault or access fault | |
| 5, 7 | With physical address for an explicit memory access: Load/store/AMO access fault | |
| Lowest | 4, 6 | If not higher priority: Load/store/AMO address misaligned |
Tips
Synchronous exception 是指那些由當前指令本身引起的例外狀況,與中斷不同,它是執行這條指令時就立刻可知的錯誤
當一條指令導致多個 synchronous exceptions 時,因為同一時間只能 trap 一次,此時就會依照此表決定哪一個例外應該優先被送進 trap handler,並寫入 scause
12.1.9. Supervisor Trap Value (stval) Register
stval 是一個 SXLEN 位元的可讀寫 CSR,其格式如下圖所示:

當透過 trap 進入 S-mode 時,硬體會將與該異常(exception) 相關的特定資訊寫入 stval,以協助軟體處理該 trap。 在其他情況下,硬體不會對 stval 做任何寫入,不過軟體可以顯式地寫入它
硬體平台會規定有哪些異常需要在 stval 中填入具體資訊、哪些異常會一律將其清為 0、以及哪些異常需要視實際導致異常的底層事件而定
若在指令擷取(instruction fetch)、讀取(load) 或寫入(store) 時,發生 breakpoint、位址未對齊(address-misaligned)、存取錯誤(access-fault) 或 page-fault,而且 stval 被寫入的值不為 0,則該 stval 內會存放導致錯誤的虛擬位址(faulting virtual address)
假設未對齊(misaligned) 的讀取或寫入觸發了 access-fault 或 page-fault 異常,而且此時 stval 被寫入的值不為 0,則 stval 會包含造成故障的那一部份存取(access) 的虛擬位址。 例如一次讀取 4 word,卻對齊在奇數位址,其可能會拆分成兩次記憶體操作(部分對齊於第一個 page,部分對齊於第二個 page)。 假設其中某個 page 發生訪問錯誤,硬體可能只在 stval 中記錄真正發生錯誤的那個分段位址
若系統支援可變長度(variable-length) 指令,並且在 instruction access-fault 或 page-fault 時 stval 被寫入的值不為 0,則:
stval會存放導致錯誤的那個指令片段(portion) 所在的虛擬位址- 而
sepc會指向該指令的起始位址
硬體實作可以選擇是否要在發生 illegal-instruction 異常時,讓 stval 用來返回造成錯誤的那條指令的位元內容,同時 sepc 會指向該指令在記憶體中的位址
如果在 illegal-instruction 異常發生時,stval 被寫入的值不為 0,則 stval 的內容會是以下三者中最短的那個:
- 實際錯誤指令(完整指令位元)
- 該錯誤指令的前
ILEN位元 - 該錯誤指令的前
SXLEN位元
取最小者能確保 stval 的內容不會超過自己能表示的位寬,而寫入到 stval 中的位元會右對齊(right-justified),而未用到的高位元則清為 0,換句話說若實際指令不足 SXLEN 位元,則 stval 的低位元保存指令位元,高位填 0
如果 trap 由 software check exception 所引起,則 stval 暫存器會保存觸發該異常的原因(cause)。 下面列出了一些定義好的編碼:
- 0:無額外資訊
- 2:Landing Pad Fault(由 Zicfilp 擴充定義,見第 22.1 節)
- 3:Shadow Stack Fault(由 Zicfiss 擴充定義,見第 22.2 節)
對於其他陷阱而言,預設將 stval 設為 0,但未來標準可能會擴充某些陷阱對 stval 的使用方式
stval 是一個 WARL 型態的暫存器,必須能夠存放所有合法虛擬位址與 0,但不需要能夠表示所有「無效」位址。 在寫入 stval 之前,硬體實作可能會把一個無效位址轉換成另一個 stval 可以表示的無效位址
如果實作支援「將錯誤指令位元載入 stval」的功能,那麼 stval 還必須能夠存下所有小於 SXLEN 與 ILEN 中較小的值
12.1.10. Supervisor Environment Configuration (senvcfg) Register
senvcfg 是一個 SXLEN 位元的可讀寫 CSR,用來控制 U-mode 執行環境的某些特性,它的格式如下圖所示:

如果在 senvcfg 中的 FIOM(Fence of I/O implies Memory) 位元被設為 1,則在 U-mode 執行的 FENCE 指令會被修改,原先只在對裝置 I/O 要求順序(order) 保證的地方,現在也同時要求主記憶體的順序保證
同樣地,當 FIOM=1 且在 U-mode 下時,如果某個原子指令(atomic instruction) 存取到被標記為 device I/O 的區域,而且該指令帶有 aq(acquire) 和/或 rl(release) 位元,那麼該指令會被視為同時存取了 device I/O 與主記憶體,因此需要對二者都進行順序保證
下表說明了在 U-mode 下 FIOM=1 時,FENCE 指令中 PI、PO、SI、SO 這些位元的修改:
| Instruction bit | Meaning when set |
|---|---|
| PI PO | Predecessor device input and memory reads (PR implied) Predecessor device output and memory writes (PW implied) |
| SI SO | Successor device input and memory reads (SR implied) Successor device output and memory writes (SW implied) |
Tips
當 FIOM=1,在 U-mode 下:
PI=1→ 表示 fence 要確保「之前(predecessor) 的裝置輸入以及記憶體讀取」都已完成(PR:predecessor reads)PO=1→ 確保「之前的裝置輸出以及記憶體寫入」都已完成(PW:predecessor writes)SI=1→ 確保「之後(successor) 的裝置輸入以及記憶體讀取」的順序(SR:successor reads)SO=1→ 確保「之後的裝置輸出以及記憶體寫入」的順序(SW:successor writes)
由於 FIOM=1,因此 I/O fence 同時會涵蓋 memory fence
如果 satp.MODE 唯讀且永遠是 0(表示系統處於 Bare 模式,無 page 功能),那麼硬體可以讓 FIOM 位元也成為唯讀的,且永遠 0(無法啟用 FIOM)
Tips
換句話說在沒有 page 的情況下,若實作者覺得不需要對 I/O 或 memory 做額外的順序處理,可將其鎖死成 0
Info
FIOM 位元是為了特定情況而設計的:
- 環境正在 U-mode 中「模擬(emulate) 一個 I/O 裝置」
- 該裝置有記憶體緩衝區,理論上應該屬於 I/O 空間(不在一般主記憶體中),但由於位址轉換(address translation) 的關係,實際上映射到主記憶體
- 多個實體 hart 同時在 U-mode 下存取這個模擬裝置
在一般情況下,「I/O fence」只保證對 I/O 動作(例如對 I/O port 或 MMIO) 的順序,不一定包含對主記憶體的同步。 但若「I/O 區」實際上是主記憶體的一塊,就有可能造成同步問題,所以需要讓「I/O fence」也涵蓋主記憶體存取
spec 的第 21 章為「Hypervisor extension(H-extension)」,當環境中沒有使用這套 H-extension(也就是沒有硬體級別的虛擬化支援),且如果無法使用「半虛擬化(paravirtualization)」,它就可能需要在 U-mode 中模擬目標裝置
換句話說那種環境下只能用 S-mode 的方式實作 “hypervisor-like” 功能,而在這種情況下,要在 U-mode 模擬裝置時,通常不能使用一些現有的硬體輔助(e.g. 2-level page table、虛擬化功能),因此需更複雜的軟體方案
一個 Hypervisor 可以提供數個虛擬 hart(vCPU),各自對應到實體 hart,此時可能會有多個實體 hart 同時存取該被模擬的裝置
例如:
- Guest OS 在 VM 內將裝置的中斷處理指派給某個 hart,但是在中斷處理以外,別的 hart 也去存取了這個裝置
- 裝置的控制權(或部分控制)在多個 hart 之間移轉,例如為了平衡 VM 內的中斷負載,把裝置從一個 hart 移交給另一個 hart
在這種情況下,guest software 需要使用 mutex 或 IPI(interprocessor interrupt) 等機制來協調多個 hart 對該模擬裝置的存取,並且經常會執行 I/O fence 以保證裝置存取的順序
然而,如果這個裝置的 I/O 其實部分是主記憶體(guest 不知道這件事),那麼原本只針對 I/O 的 fence 就有可能不足。 把 FIOM=1 設成 1 可以改變這些 fence(包括 U-mode 中執行的所有 I/O fence),使它們也涵蓋對「主記憶體」的順序保證
軟體其實可以不啟用 FIOM,前提是它絕對不會使用主記憶體來模擬原本屬於 I/O 空間的記憶體緩衝區,但這麼做通常會需要攔截(trap) 所有 U-mode 對該模擬緩衝區的存取,這可能對效能產生明顯影響,相較之下,FIOM 提供的替代方案在實作難度和開銷上都相對低,因此即使它不常被使用,我們仍認為值得支援
接下來是一些敘述較少的欄位,所以我用列點的方式表達:
CBZE欄位由 Zicboz extension 定義:這可能與 cache-block zero 指令相關CBCFE與CBIE欄位由 Zicbom extension 定義:這些則與 cache-block manage 指令(block fill,block invalidate) 相關PMM欄位由 Ssnpm extension 定義:可能與「page modification monitor」或「nested paging」之類功能相關- Zicfilp 擴充在
senvcfg中新增了名為LPE與SSE的欄位:- 當
LPE欄位被設定為 1 時,Zicfilp 擴充會在 VU/U-mode 下啟用 - 當
LPE欄位為 0 時,Zicfilp 擴充不會在 VU/U-mode 下啟用,並且在 VU/U-mode 中會套用以下規則:- 這個 hart 不會更新 ELP state(它會一直維持在
NO_LP_EXPECTED狀態) LPAD指令的行為相當於 no-op
- 這個 hart 不會更新 ELP state(它會一直維持在
- 當
SSE欄位設定為 1 時,Zicfiss 擴充在 VU/U-mode 下被啟用 - 當
SSE欄位為 0 時,Zicfiss 擴充在 VU/U-mode 下維持停用狀態,並且以下規則將生效:- 32-bit 的 Zicfiss 指令會回退(revert) 到 Zimop 擴充所定義的行為
- 16-bit 的 Zicfiss 指令會回退到 Zcmop 擴充所定義的行為
- 此外,當
menvcfg.SSE被設為 1 時,SSAMOSWAP.W/D指令在 U-mode 會產生 illegal-instruction 異常,而在 VU-mode 會產生 virtual instruction 異常
- 當
12.1.11. Supervisor Address Translation and Protection (satp) Register
satp 是一個 SXLEN 位元的可讀寫 CSR,根據 SXLEN 的不同有不同格式,如下圖:
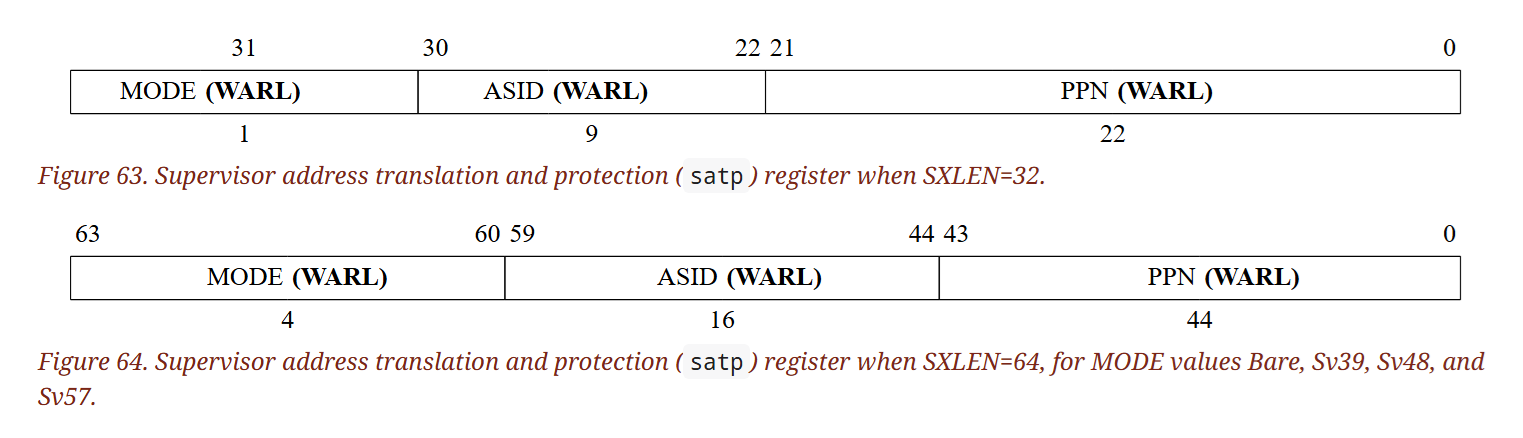
satp 用來控制 S-mode 的位址轉換與保護(address translation and protection),當中存著
- root page table 的 PPN(Physical Page Number)
- 值為 S-mode 的實體位址除以 4 KiB
- ASID (address space identifier)
- 用於在每個位址空間的基礎上輔助 address-translation fences
- MODE
- 用來選擇當前的位址轉換方式,如
Bare、Sv32 或 Sv39 等
- 用來選擇當前的位址轉換方式,如
更多關於此暫存器的存取方式請參見第 3.1.6.6 節
Info
在 satp 中儲存 PPN,而不是完整「實體位址」的好處是,能夠在 RV32 的環境下使物理位址空間超過 4 GiB
satp 中的 PPN 欄位可能無法存放所有 PPN。 有些平台標準可能會對 satp.PPN 的值施加額外限制,例如要求能夠表示所有對應到主記憶體的 PPN
將 ASID 與 page table base address 都儲存在同一個 CSR 內,是為了在進行上下文切換(context switch) 時能夠原子(atomically) 地同時更換這兩者
如果兩者不是原子更新,可能會讓舊的虛擬位址空間混入新的位址轉換資料(或反之),過程中的幾個時鐘週期內可能會出現不一致。 同時,一次性地更新 ASID 與 PPN 也能夠稍微降低上下文切換的成本(減少寫入 CSR 的次數)
下表顯示了 MODE 欄位在 SXLEN=32 以及 SXLEN=64 時的編碼方式:
SXLEN=32:
| Value | Name | Description |
|---|---|---|
| 0 | Bare | No translation or protection. |
| 1 | Sv32 | Page-based 32-bit virtual addressing (see Section 12.3). |
SXLEN=64:
| Value | Name | Description |
|---|---|---|
| 0 | Bare | No translation or protection. |
| 1–7 | - | Reserved for standard use |
| 8 | Sv39 | Page-based 39-bit virtual addressing (see Section 12.4). |
| 9 | Sv48 | Page-based 48-bit virtual addressing (see Section 12.5). |
| 10 | Sv57 | Page-based 57-bit virtual addressing (see Section 12.6). |
| 11 | Sv64 | Reserved for page-based 64-bit virtual addressing. |
| 12–13 | - | Reserved for standard use |
| 14–15 | - | Designated for custom use |
當 MODE=Bare 時,S-mode 的虛擬位址等同於 S-mode 實體位址,除了第 3.7 節描述的實體記憶體保護機制外,沒有額外的記憶體保護
如果 MODE=Bare,軟體必須將 satp 中剩餘的欄位都清 0,在 SXLEN=32 時為 bits 30–0,在 SXLEN=64 時為 bits 59–0。 如果嘗試在 MODE=Bare 的情況下於剩餘欄位填入非零值,其為未定義行為(UNSPECIFIED),不保證對剩餘欄位與位址轉換/保護的結果
在 SXLEN=32 的情況下,若 MODE=Bare 且 ASID[8:7] = 3,則 satp 被用為自訂用途(custom use);若 MODE=Bare 但 ASID[8:7] ≠ 3,或是當 SXLEN=64 時,所有對應 MODE=Bare 的 satp 編碼都被保留給未來標準使用
Info
在標準的 1.11 版中,曾聲明「在 MODE=Bare 時,satp 的其他欄位沒有任何影響」,現在把這些欄位設為保留位是為了將來能在 RV32 上定義更多位址轉換與保護模式,尤其對於已經用完現有 MODE 編碼的 RV32 來說,此舉更顯必要
在 SXLEN=32 的情況下,除了 Bare 之外,唯一有效的 MODE 設定為 Sv32,詳細說明見第 12.3 節。 當 SXLEN=64 時,標準定義了三種 page-base 的虛擬記憶體機制:Sv39、Sv48 與 Sv57,分別在第 12.4、12.5、12.6 節有詳細描述。 未來標準還會定義 Sv64。 至於其他 MODE 設定都被保留給未來使用,且可能對 satp 內的其他欄位有不同的解釋方式
硬體實作不需要支援所有 MODE,如果軟體寫入了某個硬體不支援的 MODE,則整個寫入動作無效,satp 中的任何欄位都不會被改變
ASID 的 bit 數並沒有被指定(UNSPECIFIED),其有可能是 0。 為了知道硬體實際實作了多少個 ASID 位元(稱為 ASIDLEN),可以嘗試在 ASID 欄位的每一個位元都寫入 1,然後讀回 satp 看哪些位元仍維持為 1。
ASID 需要從最低位元開始實作,也就是說如果 ASIDLEN = N > 0,那麼 ASID[N-1 : 0] 是可寫的。 ASIDLEN 的最大值(ASIDMAX) 在 Sv32 下是 9,在 Sv39/Sv48/Sv57 下是 16
Info
對許多應用程式而言,page size 會對效能產生顯著影響。 較大的 page 可以增加 TLB 的涵蓋範圍(TLB reach),並且能減少對 VIPT 快取的組合度(associativity) 限制。 然而較大的 page 會加劇了內部碎片化(internal fragmentation) 的問題,浪費了實體記憶體,甚至可能浪費快取
委員會最後決定在 RV32 與 RV64 上都使用傳統的 4 KiB page size,預期使低層級的軟體與裝置驅動更容易移植
現代作業系統中透明的 superpage 支援已經能緩解 TLB 覆蓋範圍的問題(Navarro et al., 2002)。 另外,相較於多層級的快取(multi-level cache),多層級的 TLB(multi-level TLB) 的成本相對便宜,而且它們只需要映射同一個位址空間
當特權模式為 S-mode 或 U-mode 時,satp CSR 被視為是「活動(active)」的。 在 satp 處於活動狀態時,負責轉換位址的演算法才會使用 satp 的值
如果在 satp 活動期間開始了一次位址轉換,若此時 satp 變為非活動狀態(例如切回了 M-mode),那些已經開始的轉換不需要馬上完成或終止,除非執行了與對應到該位址與 ASID 的 SFENCE.VMA 指令
系統必須利用 SFENCE.VMA 來確保該 hart 之後的「隱式讀取(implicit read)」能看到更新後的位址轉換的資料結構
寫入 satp 不代表 page table 的更新與後續的地址轉換之間有任何順序限制(ordering constraints),也不代表地址轉換的快取會失效。 假如新的地址空間的 page table 已被修改,或者重用了某個 ASID,其通常需要在寫入 satp 前/後執行 SFENCE.VMA 指令(參見第 12.2.1 節)
Info
RISC-V 設計上把寫入 satp 與 TLB flush / page table fence 分離,讓軟體可更彈性控制失效時機,因此需要先在 page table 中做好更新,然後執行 SFENCE.VMA,再寫入 satp;或者先寫入 satp,然後再執行 SFENCE.VMA —— 依具體應用情況而定
不要求在寫入 satp 時使強制讓地址轉換的快取失效,可以降低上下文切換的成本,不過前提是擁有足夠大的 ASID 空間
12.2. Supervisor Instructions
除了 3.3.2 節中定義的 SRET 指令外,還提供了另一條新的 S-mode 指令
12.2.1. Supervisor Memory-Management Fence Instruction

Tips
這邊翻的有點難懂,主要記得這兩個專有名詞:
- 記憶體管理資料結構(memory-management data structure):如 page table
- 地址轉換快取(address-translation cache):如 TLB
- 地址轉換快取項目:如 TLB entry
SFENCE.VMA(supervisor memory-management fence)是一條指令,用來將記憶體中的「記憶體管理資料結構(memory-management data structures)」的更新與「當前執行」同步
一般的指令在執行過程中會隱式地讀寫這些資料結構,但這些隱式引用(implicit references) 通常不會與顯式的 load/store 指令有任何順序保證
Tips
在 RISC-V(以及許多其他架構)中,「隱式引用」指的是 CPU 在執行某些行為時,在硬體層面主動對記憶體管理資料結構進行的讀寫,而這些讀寫並不直接對應程式碼中的顯式指令
例如在讀 page table 的時候,CPU 需要將虛擬位址轉換為實體位址,因此會在硬體層面讀取或查詢 page table,又或是 TLB 之類的快取裡面的資訊
這個行為對軟體來說是不可見的,程式碼中並沒有 load/store page table 的指令,但硬體卻完成了對 page table 的存取,因此稱為隱式引用
SFENCE.VMA 指令可以確保對該 hart,可見的所有寫入(store)都會先於之後指令中對這些記憶體管理資料結構的某些隱式參考
SFENCE.VMA 所影響的特定操作集合,會由 rs1 和 rs2 來決定。 同時,SFENCE.VMA 也被用來讓與該 hart 相關的位址轉換快取失效(詳見第 12.3.2 節)
關於該指令的進一步細節可參見第 3.1.6.6 與第 3.7.2 節
Info
SFENCE.VMA 用來清空與地址轉換相關的硬體快取。 其被定義為一條「fence」指令,而非「TLB flush 指令」,是為了提供更清晰的語意,說明哪些指令會受到 flush 影響,也同時支援更多種動態快取架構與記憶體管理方案
此外,SFENCE.VMA 也會被更高特權層(例如 M-mode 或 HS-mode)用來將「page table 的寫入」與「地址轉換硬體」做同步處理
總而言之,SFENCE.VMA 會做兩件事:
- 確保虛擬位址翻譯的同步
- Flush TLB
SFENCE.VMA 只會排序(order) 該指令所在的 hart 上,針對「記憶體管理資料結構」的隱式參考,不會影響其他 hart 上的地址轉換快取,也不會為它們提供同步或失效機制
因此,若記憶體管理資料結構已被修改,其他 hart 必須另行通知,其中一種做法是:
- 在本地先執行一個 data fence(確保本地對 page table 的寫入可在全域中看得見)
- 然後透過 IPI 通知另一個 hart
- 接著在遠端 hart 的中斷處理程式中執行本地的
SFENCE.VMA - 最後再告知原本的發送者,這個操作已完成
此流程在 RISC-V 中對應了「TLB shootdown」的做法
Tips
TLB shootdown 的一個簡單例子是
- 系統中有個所有 hart 共享的記憶體
- 其中一個 hart 限制了對該共享記憶體 page 的存取
- 因此所有的 hart 都必須刷新其 TLB,以便禁止那些原先被允許訪問該 page 的 hart 去存取該 page
一個 hart 的操作導致其他 hart 上的 TLB 被刷新,這就是所謂的 TLB shootdown
在多 CPU 系統中,傳統的方式是「IPI + flush TLB + ack」的過程,RISC-V 中則用 SFENCE.VMA 來 flush TLB
針對只修改了一個地址映射(例如只有一個 page 或 superpage)的常見情況,可透過 rs1 指定一個在映射範圍內的虛擬位址,從而只針對該映射進行 translation fence。 另外若只修改了一個 ASID,則可透過 rs2 指定該地址空間
Tips
Translation fence(SFENCE.VMA)用來清除或同步處理器快取中的翻譯結果(如 TLB, page walk cache)與主記憶體中 page table entry(PTE)的內容,以確保當 page table 被軟體修改後,接下來的虛擬位址轉譯會根據新的 PTE 的內容執行
在大多數情況下,OS 可能只更新了特定的一個 page 或 superpage,因此這可以避免整個 TLB 失效;同樣地如果只改了對應的某個 ASID(比如只修改了一個 Process 的 page table),則只要失效與該 ASID 相關的 TLB 項目即可
另外,Data fence(FENCE/FENCE.I)用來確保不同記憶體操作之間的執行順序,以滿足一致性模型與 I/O 記憶體順序的需求
SFENCE.VMA 的行為依賴於 rs1 與 rs2,具體說明如下:
rs1 = x0且rs2 = x0(全域失效):
該 fence 會對「所有地址空間」內,「所有層級的 page table」的所有讀寫進行排序;同時,也會使所有地址空間的所有地址轉換快取項目失效rs1 = x0且rs2 ≠ x0(所有虛擬位址,特定 ASID):
該 fence 只會對由rs2「指定的位址空間」內,「所有層級的 page table」的讀寫進行排序;同時,對全域映射的存取則不納入此排序(詳見第 12.3.1 節)此外,該 fence 只會無效化與
rs2所「指定的地址空間」相符的地址轉換快取項目,但擁有全域映射的項目則不會被無效化rs1 ≠ x0且rs2 = x0(特定虛擬位址,所有 ASID):
該 fence 會對「所有地址空間」內,由rs1「指定的虛擬位址」所對應的 leaf PTE 進行排序此外,該 fence 只會無效化「所有地址空間」內,「指定的虛擬位址」所對應的 leaf PTE 的快取項目
rs1 ≠ x0且rs2 ≠ x0(特定虛擬位址,特定 ASID) :
則 fence 只會對rs2「指定的地址空間」內,由rs1「指定的虛擬位址」所對應的 leaf PTE 進行排序;同樣地,對全域映射則不包含在此範圍此外,該 fence 只會無效化,包含與
rs1「指定的虛擬位址」所對應的 leaf PTE,且與rs2所「指定的地址空間」相符的地址轉換快取項目,但擁有全域映射的項目不會受影響
若 rs1 內的數值不是一個有效的虛擬位址,則 SFENCE.VMA 指令沒有任何作用,而且不會拋出異常
Info
over-fence 在任何時候都合法,例如,只使用 rs1 與/或 rs2 中一部分的位元進行失效,或者乾脆把任何 SFENCE.VMA 都當成 rs1 = x0、rs2 = x0 來執行
舉例來說,較簡單的實作方式可以忽略 rs1 的虛擬位址及 rs2 的 ASID,一律都做 global fence。 之所以選擇在 rs1 持有無效虛擬位址時不拋出異常,正是為了方便這種簡化實作
對記憶體管理資料結構的隱式讀取,可能會返回任何「從上一次涵蓋該位址的 SFENCE.VMA」之後,曾經有效過的地址轉譯結果
SFENCE.VMA 所做的順序保證並沒有將「對記憶體管理資料結構的隱式讀寫」納入全域記憶體排序中,和標準 RVWMO(RISC-V Weak Memory Ordering)規則並不完美對應
具體來說,雖然 SFENCE.VMA 保證了先發生的顯式訪問一定先於後續的隱式訪問,而這些隱式訪問又先於它們所對應的顯式訪問,但 SFENCE.VMA 不一定能在全域記憶體排序中,把「先前的顯式訪問」明確地排在「後續顯式訪問」之前
此外,對這些記憶體管理資料結構的「隱式讀取(implicit load)」,也不必遵守正常的 program order 與之前針對同位址的 load/store 之間的關係
Tips
這代表在執行 SFENCE.VMA 之前,若你改了 page table,而又沒有對應的 SFENCE.VMA,此時 TLB 仍持有舊的轉換結果,此時不管 TLB 繼續使用舊的轉換結果,或重新讀 page table 來拿到新的轉換結果,都是有可能的行為,換句話說行為不可預測,但符合規範
SFENCE.VMA 雖然可以保證「先前對 page table 的 explicit store」在「後續對 page table 的 implicit load」前可見,但它不自動保證「先前所有 explicit store」會在「後續所有 explicit store」前出現在全域順序中
由於這項規範,實作可以使用自上次對該位址執行(並涵蓋該位址的)SFENCE.VMA 以來,任何時刻曾經有效過的位址轉譯結果。 也就是說,如果修改了一個 leaf PTE 但沒有執行對應的 SFENCE.VMA,舊轉換結果或新轉換結果都有可能被硬體拿來使用,系統無法預測會用哪一個。 不過,除「可能隨機選擇舊/新轉換結果」之外的行為,都有被明確定義
在傳統 TLB 設計中,可能會出現多個可以對應到同一個位址的 TLB 項目。 舉個例子,如果把一個普通的 page 升級成 superpage,但沒有把原本 non-leaf PTE 的 valid bit 清除,並用 rs1=x0 執行一個 SFENCE.VMA,那麼
在這種情況下,同樣地,硬體無法預測會用到「舊的 non-leaf PTE」還是「新的 leaf PTE」,但行為依照規範也是符合定義的(well defined)
Tips
假設 OS 把原本多個 4 KiB page 合成一個更大的 superpage(例如 2 MiB),則中間需要更新 page table 結構(non-leaf → leaf) 並讓舊的轉換結果失效
如果沒有做正確的失效(像是忘了先關 valid bit、再做 SFENCE.VMA),TLB 內就有可能同時保留舊 non-leaf PTE 和新 leaf PTE
此時依 RISC-V 規範來說,這不會導致未定義行為(undefined),但行為是沒保證的(unpredictable),OS 看起來可能會有不一致現象(有時舊、有時新)
這個規範的另一種後果是,多次利用寬度小於 PTE 寬度的 store 指令來更新 PTE 通常是不安全的,因為對硬體來說,它可以在任意時間讀取該 PTE,包括在只有部分 store 指令被完成、生效,但整個 PTE 尚未被完整更新的時候
Tips
換句話說,假設 PTE 是 64 位,但程式只用 2 個 32 位 store 來改它;在兩次 store 之間,硬體可能會讀到更新到一半的 PTE
本規範允許在 V(Valid) 位元為 0 時,依然快取該 PTE。 作業系統在實作時,必須面對這種情況;但同時也要提醒硬體實作者,如果過度地快取這些無效 PTE,將導致更多的 page fault 發生,從而拖累效能
硬體實作只能對下列範圍進行隱式讀取(如 TLB 查詢 page table):
- 由目前
satp暫存器所指向的地址轉譯資料結構 - 或者從該 page table 中向下遞迴時出現的、有效(V=1)的 PTE
同時,硬體只允許對「來自指令實際執行」所導致的隱式訪問產生異常,對於「推測執行(speculative execution)」所造成的隱式訪問不能產生例外(exception)
Tips
推測執行(speculative execution)是指 CPU 預先執行可能會用到的指令,即使當下還無法確定它們是否真的會被執行,以提升效能與吞吐量,一個常見的例子是 branch prediction,但其他像是 Memory disambiguation 或 Indirect Jumps 等地方也會用到
對 sstatus 中的 SUM 和 MXR 欄位所做的更動會立即生效,不需要執行 SFENCE.VMA。 將 satp.MODE 從 Bare 切換到其他模式(或反之)時也會立即生效,無需執行 SFENCE.VMA。 同樣,變更 satp.ASID 的值也會立即生效。
以下幾種常見情境通常都需要執行 SFENCE.VMA 指令:
當軟體回收一個 ASID(即將其重新關聯到不同的 page table)時,應先把
satp設定到「新 page table + 該 ASID」,然後執行SFENCE.VMA(rs1 = x0,rs2為該回收 ASID)來失效這個 ASID 相關的 TLB 項目。 也允許提前執行SFENCE.VMA,只要之後載入 ASID 時確實對應新 page table 即可在實作不支援 ASID,或軟體根本不用(只用 ASID 0)的情況下,所有 Process 都會共用同一份 TLB cache,那在每次寫入
satp後(如切換 page table),軟體應要執行SFENCE.VMA(rs1=x0)來 flush 整個 TLB。 如果沒有改到全域映射,可透過將rs2設為一個非x0但值為零的暫存器,來避免不必要的 flush(不刷新全域映射)若軟體修改了一個 non-leaf PTE,則應該執行
SFENCE.VMA(rs1 = x0)。 如果走訪路徑上的任何 PTE 有將 G bit 設為 1,代表改到了全域映射,因此rs2必須被設為x0(flush ALL ASID),否則rs2應被設為被修改的 non-leaf PTE 所屬的 ASID若軟體修改了一個 leaf PTE,則應該執行
SFENCE.VMA(rs1被設為該 page 內的任一虛擬位址),以針對該 page 的 TLB 項目進行失效。 如果遍歷路徑上的任何 PTE 有將 G bit 設為 1,則rs2必須被設為x0(flush ALL ASID),否則rs2應被設為被修改的 leaf PTE 所屬的 ASID在提升 leaf PTE 的權限,或將一個無效 PTE 改為有效的 leaf PTE 時,軟體可以選擇延遲執行
SFENCE.VMA。 在修改 PTE 後,但尚未執行SFENCE.VMA前,可能會使用新的權限,也可能會使用舊的權限。 若是後者,則可能會產生 page fault exception,此時軟體應依照上一點來執行SFENCE.VMA這主要是因為有些情況下(如只增加權限,或把 page 從 invalid 變 valid),允許先執行程式碼,等真的觸發 page fault 再補做 flush,可以減少不必要的 TLB flush,提高效能。 在這段期間,硬體可能會用到新的或舊的權限,因此最多只會多一次 page fault,並不會導致未定義行為
地址轉譯快取是 hart-locol 的,每個 hart 都有自己的 TLB/ASID 解釋,並不要求全系統一致,軟體可以選擇在不同的 hart 上使用相同的 ASID 來代表不同的地址空間
未來的擴充可能會將 ASID 重新定義為在整個 Supervisor Execution Environment(SEE)中是全域的,從而實現像是共用地址轉譯快取與硬體支援的廣播式 TLB shootdown 等選項。 然而現今作業系統已經有各種先進技巧(如 lazy shootdown、分群 flush 等)來減少 TLB shootdown 的頻率與範圍,所以我們預期 hart-locol ASID 依然因其簡潔性與可擴展性而仍具吸引力
對於那些將 satp.MODE 設為唯讀且固定為零(始終為 Bare 模式)的實作,嘗試執行 SFENCE.VMA 指令可能會觸發非法指令例外(illegal-instruction exception)
12.3. Sv32: Page-Based 32-bit Virtual-Memory Systems
Sv32 是 RISC-V 定義的 32-bit page-base 的虛擬記憶體架構,僅在 32 位元平台(SXLEN=32)可用,設計時已納入足以支援現代 Unix 系統所需的各種機制。 當 Sv32 被寫入 satp 暫存器中的 MODE 欄位時(參見第 12.1.11 節),supervisor 將會運作於 32-bit page-base 的虛擬記憶體系統中。 在這個模式下,supervisor 與 user 的虛擬位址會透過走訪一棵 radix-tree 結構的 page table,轉換為 supervisor 的實體位址
RISC-V 初期的 page-base 虛擬記憶體架構是以簡單直接的方式設計,目的是為了支援既有的作業系統。 我們針對 page table 的結構進行了設計,使其能夠支援硬體層面的 page-table walker。 對於高效能系統來說,使用軟體方式進行 TLB refill 是一個效能瓶頸,對於那些與主處理器解耦的專用 coprocessor 而言更是麻煩。 如果要使用軟體的 TLB refill,可以選擇以 M-mode trap handler 來實作,作為 M-mode 的擴充
某些指令集架構在架構層級上暴露了 VITP 的快取機制,如果經由不同的虛擬位址存取同一個實體位址,在快取中可能不具一致性,除非這些虛擬位址剛好落在同一個 cache set 中。 而本規範隱含地禁止這類行為在架構層級上被暴露
Tips
某些架構使用的 cache 設計是 VIPT(Virtually Indexed, Physically Tagged):
- index 用 VA 的部分位元來決定哪一個 cache set
- tag 用 PA 的部分位元來做比對(避免 alias)
如果不同的 VA 映射到同一個 PA,而它們 index 落在不同 cache set,就會導致同一筆資料會在兩個 cache block 中出現,導致 cache incoherence issue
而 RISC-V 的規範禁止了這種行為,換句話說,RISC-V 保證對相同 PA 的訪問行為不會受 VA 差異影響,這讓 OS 設計更簡單,也避免奇怪的 cache bug
12.3.1. Addressing and Memory Protection
Sv32 的實作支援一個 32-bit 的虛擬位址空間,並以 page 進行劃分。 一個 Sv32 的虛擬位址會被分割為一個 virtual page number(VPN)與 page offset,如下圖所示:

當 satp 暫存器中的 MODE 欄位被設為 Sv32 時,supervisor 的虛擬位址會透過一個兩層的 page table 轉換為 supervisor 的實體位址。 這個 20-bit 的 VPN 會轉換為一個 22-bit 的 physical page number(PPN),而 12-bit 的 page offset 則不參與轉換
最終所得到的 supervisor-level physical address 會先經過任意已實作的 physical memory protection 結構(見第 3.7 節)檢查,然後才被直接轉換為 machine-level physical address。 如有需要,supervisor-level physical address 會以 zero-extension 擴展至實作所支援的實體位址寬度
Info
例如,考慮一個支援 34-bit 實體位址的 RV32 系統。 當 satp.MODE 設為 Sv32 時,會直接產生一個 34-bit 的 physical address,因此不需要進行 zero-extension。 而當 satp.MODE 設為 Bare 時,32-bit 的虛擬位址會直接作為 32-bit 的 physical address,然後這個 physical address 會以 zero-extension 方式延展為一個 34-bit 的 machine-level physical address
Tips
在 RISC-V 中,經過 page walk 後查出來的 physical address 被稱為 Supervisor-level physical address,換句話說 leaf-PTE 內存的 PPN 只是 Supervisor-level physical address。 而真正 memory bus 看到的位址被稱為 Machine-level physical address
spec 上是允許平台在 Supervisor PA ➝ Machine PA 間進行轉換的,而這個轉換取決於實體平台的實作:
- 有些平台:Supervisor PA = Machine PA(直接用)
- 有些平台:
- 使用 Zero-extension(常見於 32-bit 虛擬空間 → 36/40-bit PA)
- 使用 bus remapping 或 MMU(Memory Management Unit)機制
- 使用 PMA(Physical Memory Attribute)或 PMP 進行範圍限制與調整
Sv32 的 page table 包含 satp 暫存器中
Sv32 的 PTE 格式如下圖所示:

V bit 表示此 PTE 是否為有效,若為 0,則 PTE 中的所有其他位元均可被忽略,並可供軟體自由使用。 權限位元 R、W 與 X 分別表示此 page 是否可讀、可寫、可執行,當這三個位元皆為 0 時,表示該 PTE 指向下一層 page table 的指標;若有任一位元為 1,則該 PTE 為一個 leaf PTE。 可寫的 page 必須同時標記為可讀(W 被設為 1 時 R 也一定要被設為 1),相反的組合保留做未來用途
下表概述了權限位元的編碼方式:
| X | W | R | Meaning |
|---|---|---|---|
| 0 | 0 | 0 | Pointer to next level of page table. |
| 0 | 0 | 1 | Read-only page. |
| 0 | 1 | 0 | Reserved for future use. |
| 0 | 1 | 1 | Read-write page. |
| 1 | 0 | 0 | Execute-only page. |
| 1 | 0 | 1 | Read-execute page. |
| 1 | 1 | 0 | Reserved for future use. |
| 1 | 1 | 1 | Read-write-execute page. |
若試圖從一個沒有執行權限的 page 中 fetch instruction,會觸發 fetch page-fault exception。 若執行一條 load 或 load-reserved 指令,其有效位址(effective address)落在一個沒有讀取權限的 page 上,則會觸發 load page-fault exception。 若執行 store、store-conditional 或 AMO 指令,其有效位址落在一個沒有寫入權限的 page 上,則會觸發 store page-fault exception
Tips
- X 權限缺失 → 擷取指令時觸發 fetch page-fault
- R 權限缺失 → 執行 load(或 LR)時觸發 load page-fault
- W 權限缺失 → 執行 store / SC / AMO 時觸發 store page-fault
每種類型的 page-fault 對應不同的 trap 處理流程與 scause 編碼
AMO 指令永遠不會引發 load page-fault exception,因為一個不可讀的 page 必定也是不可寫的,若試圖在一個不可讀的 page 上執行 AMO,將一律觸發 store page-fault exception
U bit 用來指示該 page 是否可供 U-mode 存取,U-mode 軟體僅可存取 U=1 的 page。 若 sstatus 暫存器中的 SUM 欄位被設為 1,S-mode 的軟體也可存取 U=1 的 page。 然而,S-mode 通常會在 SUM=0 的情況下運作,此時若試圖存取 U-mode 的 page,將會觸發 fault。 無論 SUM 的狀態為何,supervisor 都不得執行來自 U=1 的 page 中的指令
另一種替代的 PTE 格式支援為 supervisor 與 user 分別設計不同的權限。 我們省略了這項設計,因為它與 SUM 機制(見第 12.1.1.2 節)大致重複,且會額外佔用 PTE 的編碼空間
Tips
某些架構(如 x86)允許 page 使用者與核心擁有不同的權限組。 RISC-V 選擇不在 PTE 中獨立加入 U/S 的權限控制,而是交由 sstatus 的 SUM 來控制 supervisor 能否碰 user page
G bit 用來標示此為 global mapping,global mapping 是指存在於所有 address space 中的 mapping。 對於 non-leaf PTE 而言,若其被設為 global,則其下一層 page table 中的所有 mapping 也都是 global 的
要注意的是,若忘了把 global mapping 標記為 global,只會導致效能下降; 但若錯誤地將 non-global mapping 標為 global,則在切換 address space 且該位址範圍有不同 non-global mapping 的情況下,可能會不可預測地使用其中之一,屬於軟體錯誤
Info
global mapping 不需要為多個 ASID 在地址轉譯快取中重複儲存。 此外,執行 SFENCE.VMA 且 rs2 ≠ x0 時,也不需將 global mapping 自本地地址轉譯快取中清除
RSW 欄位保留給 supervisor 軟體使用,實作(硬體)應忽略此欄位
每個 leaf PTE 都包含一個 accessed(A)bit 與 dirty(D)bit。 A bit 表示該 virtual page 自從上一次 A bit 被清除後,是否曾經被讀取、寫入,或 fetch。 D bit 則表示該 virtual page 自從上一次 D bit 被清除後,是否曾經被寫入過
針對 A 與 D bit 的管理,規範定義了兩種機制:
第一種是 Svade extension:
當 virtual page 被存取且 A bit 為清除狀態,或被寫入且 D bit 為清除狀態時,將會觸發一個 page-fault exception
Tips
Svade 是一個 optional 的 RISC-V extension
它的策略是由軟體來管理 A/D bit:
- 硬體不會自動 set A/D bit
- 如果未設而觸發使用,會故意讓 trap 發生(page-fault)
- OS 可以透過 trap handler 來動態設置 A 或 D bit
因此可想而知下方的另一種就是由硬體來管理的方式
第二種,當未實作 Svade extension 時,則會套用以下機制:
當 virtual page 被存取且 A bit 為清除狀態時,PTE 將會被更新以設置 A bit。 當 virtual page 被寫入且 D bit 為清除狀態時,PTE 將會被更新以設置 D bit。 若 G-stage address translation 已啟用且其模式不是 Bare,則這些 G-stage virtual pages 可能會因為對 VS-level 記憶體管理結構的隱式存取而被讀取或寫入
當系統使用 two-stage address translation 時,一次顯式的存取可能同時造成 VS-stage 與 G-stage 的 PTE 被更新
Tips
在虛擬機系統中,會有兩層 page translation:
- 第一層(VS-stage):guest OS 自己的 VA → GPA
- 第二層(G-stage):hypervisor 將 GPA → MPA
以下規則適用於所有由顯式或隱式 memory access 所引發的 PTE 更新操作:
PTE 的更新必須對其他對該 PTE 的存取操作具有原子性,並且必須以原子方式執行對該 leaf PTE 所需的所有 page walk 檢查,且這些檢查應該是 PTE 更新的一部分,並且要在「條件式更新 PTE 值」之前完成
Tips
這邊主要是在講當硬體(例如 MMU)在修改某個 PTE(特別是 A/D bit)時:
- 不得與其他對該 PTE 的讀/寫操作交錯
- 必須確保整個「讀 + 檢查 + 更新」整組是不可被中斷的操作(atomic)
MMU 在決定要不要更新 A/D bit 時,不能只看那一個 bit,而是必須「完成所有 page walk 要求的檢查條件」,比如:
- 該 PTE 是否有效(V=1)
- 權限是否合法(R/W/X)
- 對應地址是否對齊
- PPN 合法性
而且這整個檢查加更新的動作必須是一個「原子的動作」。 更新 A/D bit 的動作,是有條件的(conditionally),並非一定會做
假設在
A=1的情況下我們就需要更新。 但此時只有在「先做完上述所有檢查,且都通過」的情況下,才能去條件式更新 PTE 的值所以「檢查 + 決定是否更新 + 更新」這整組動作是不可中斷的
A bit 的更新可以作為推測執行的結果進行,即使該次存取最終未實際發生。 然而,D bit 的更新必須是精確的(也就是不可推測執行),並且需由 local hart 以程式順序觀察
當 two-stage address translation 被啟用時,若 G-stage PTE 允許寫入,則在任意推測性地存取 VS-stage PTE 之前,對 G-stage PTE 的 D bit 更新可以由隱式 VS-stage 存取觸發
Tips
two-stage address translation(雙階段地址轉譯)是在像 RISC-V 這種支援虛擬化(virtualization)的架構中,為了讓虛擬機(guest OS)也能使用虛擬記憶體機制而引入的一個關鍵設計,目的很簡單:讓 guest OS 看到的虛擬地址,也能經過兩層轉換後,對應到實體記憶體中的真正位置
在支援虛擬化的架構(例如你開啟了 RISC-V 的 Hypervisor extension),會有:
- Guest OS:跑在虛擬機中的作業系統,它也會認為自己有虛擬記憶體空間
- Hypervisor(Hypervisor-level OS):真正管理整體實體記憶體的人
這時候就需要兩階段的地址轉譯,步驟如下:
第 1 階段(VS-stage translation):
- 轉換 Guest OS 的虛擬地址(GVA:Guest Virtual Address)
- 使用 vsatp 中定義的 guest page table
- 轉換 GVA ➝ GPA(Guest Physical Address)
第 2 階段(G-stage translation):
- 轉換 GPA ➝ MPA(Machine Physical Address)
- 使用 hypervisor 的 hgatp 中定義的 G-stage page table
PTE 的更新在全域記憶體順序中,必須出現在造成該 PTE 更新的那次記憶體存取之前,且也必須出現在該 hart 隨後對該 virtual page 的任何顯式記憶體存取之前
由 FENCE 指令或原子指令上的 acquire/release 位元所提供的 load/store 順序,也會對其他 hart 可見地順序化這些與 PTE 更新相關的 load/store 操作
PTE 的更新不需要與觸發該更新的那筆記憶體存取操作之間具有原子性,換句話說,在 PTE 被更新(例如設置 A/D bit)之後、真正去執行那次記憶體存取之前,可能會有 trap 發生,如果真的發生 trap,那麼 A/D bit 可能已經被寫入 PTE 中,但記憶體本身的訪問卻尚未執行。 在 PTE 的更新還沒在「全域可見」(globally visible)之前,hart 不能提早去執行那次記憶體存取
Tips
這邊主要想講的是設置 A/D bit 這件事不一定要跟真正的「load/store/fetch」同一時間發生
它們可以拆成兩個動作:
- 先更新 A/D bit
- 再訪問那個 page
中間如果發生了 page fault,A bit 可能已經設了(表示這個 page「曾被嘗試存取過」),但你還沒真的去讀資料,這在 RISC-V 中是合法的
但是不能先訪問該 page 再更新 A/D bit,如果硬體提早去讀資料,而這時其他 hart、或甚至是 OS 都還沒看到 PTE 的變動(例如還沒寫入 memory),就會導致不可預期的 race
page table 必須被放置在具有硬體 page-table 寫入權限,並且具備 RsrvEventual PMA 的記憶體區段中
Tips
- PMA = Physical Memory Attribute(硬體定義哪些 memory 區段可怎麼被存取)
- RsrvEventual:一種允許最終一致性與延遲更新的 PMA 模式
另外,無論是哪種方法:
- 一個系統中的所有 hart 必須使用相同的 PTE 更新機制
- 記憶體存取(位於某個
FENCE指令之後)所引起的 PTE 更新,本身不會被該FENCE指令所排序
Tips
FENCE 只針對顯式記憶體存取有效,對於那些間接觸發的 A/D bit 寫入,並不適用
Info
較簡單的實作方式可以將 PTE 的更新設計為發生在所有後續顯式記憶體存取之前,而不需要特別保證該 PTE 的更新恰好在與其關聯的 virtual page 的後續存取之前發生
在早期版本的規格中,要求 PTE 的 A bit 必須精確更新。 但現在允許 A bit 在推測執行時被更新,這有助於簡化 address translation prefetcher 的實作。 通常系統軟體將 A bit 作為 page replacement 的提示,因而不需要嚴格要求功能的正確性
但相對地,D bit 的更新仍必須精確,且必須依程式順序執行,因為 D bit 會影響剔除 page 的功能正確性。 當然,實作仍然允許將 A bit 與 D bit 的更新都以精確方式來執行
在兩種情況下,都要求 PTE 的更新具有原子性,以確保更新不會被其他對 page table 的寫入操作所打斷。 因為如果中間被打斷,可能會造成 A/D bit 被設在已被重新使用或回收的 PTE 上。 較簡單的實作可以改用觸發 page-fault exception 來避免這類問題
A bit 與 D bit 不會被硬體主動清除。 若 supervisor 軟體不依賴 A/D bit(例如不需要 swap 到硬碟,或該 page 被用來映射 I/O 空間),則應該直接在 PTE 中將其設為 1,以提升效能
任何層級的 PTE 都可以是 leaf PTE,因此除了 4 KiB 的 page,Sv32 也支援 4 MiB 的 megapage。 一個 megapage 必須在虛擬與實體位址上都對齊至 4 MiB 邊界,若實體位址未對齊,將會觸發 page-fault exception
對於非 leaf PTE,D、A 與 U 這些位元目前是保留給未來標準使用的。 在其用途尚未被標準 extension 定義之前,軟體必須將這些位元全都清 0,以維持向前相容性
對於同時支援 page-based 虛擬記憶體與「A」標準指令集擴充(即原子指令集)的實作來說,LR/SC(Load-Reserved / Store-Conditional)所使用的 reservation set 必須完全落在同一個 base physical page 中(也就是自然對齊的 4 KiB 實體記憶體區域內)
在某些實作中,未對齊的 load、store 以及 fetch 可能會被拆解成多個記憶體存取動作,其中的部分動作可能會在 page-fault 發生之前就成功完成,特別是對一個未對齊的 store 操作來說,即使該 store 的其他部分最終因例外而失敗,某一部分也可能會通過例外檢查並實際寫入
即使是位址已自然對齊的情況下,若 store 操作的寬度超過 XLEN(例如 RV32D 中的 FSD 指令),也可能出現類似行為
12.3.2. Virtual Address Translation Process
虛擬位址 va 轉換為實體位址 pa 時遵循以下步驟:
令
a = satp.ppn × PAGESIZE,並令i = LEVELS - 1(對於 Sv32,PAGESIZE =satp暫存器必須處於活動狀態,也就是說當前有效的特權模式必須是 S-mode 或 U-mode令
pte為在地址a + va.vpn[i] × PTESIZE處所儲存的 PTE 值(對於 Sv32,PTESIZE = 4)。 若在存取此pte時違反 PMA 或 PMP 檢查,則會觸發與原始存取類型對應的 access-fault若
pte.v = 0,或pte.r = 0且pte.w = 1,或pte中設置了保留給未來標準使用的位元或編碼,則停止並觸發與原始存取類型對應的 page-fault否則,該
pte為有效項目。若pte.r = 1或pte.x = 1,則跳至第 5 步(表示已是 leaf PTE)。 否則,該pte是下一層 page table 的指標令
i = i - 1,若i < 0,則停止並觸發 page-fault;否則,令a = pte.ppn × PAGESIZE並回到步驟 2當前已到達一個 leaf PTE。 若
i > 0且pte.ppn[i-1:0] ≠ 0,表示這是一個未對齊的 superpage,停止並觸發 page-fault根據當前特權模式及
mstatus中SUM與MXR欄位的值,檢查該次記憶體存取是否被pte.u位元所允許。 若不被允許,則停止並觸發 page-fault確認對於 Shadow Stack 記憶體保護規則,該次記憶體存取是否被
pte.r、pte.w與pte.x所允許。 若不被允許,則停止並觸發 access-fault檢查該次記憶體存取是否被
pte.r、pte.w、pte.x所允許。 若不被允許,則停止並觸發 page-fault若
pte.a = 0,或原始存取為 store 且pte.d = 0:- 若實作了 Svade extension,則停止並觸發 page-fault
- 若對 pte 的寫入違反 PMA 或 PMP 檢查,則觸發 access-fault
- 以原子方式執行以下操作:
- 比較目前的 pte 與在
a + va.vpn[i] × PTESIZE處的記憶體值是否一致 - 若一致,則將
pte.a設為 1;若原始存取為 store,也將pte.d設為 1 - 若比較失敗,則返回步驟 2(重試 table walk)
- 比較目前的 pte 與在
轉譯成功後,對應的實體位址
pa為:pa.pgoff = va.pgoff- 若
i > 0(代表使用 superpage),則pa.ppn[i-1:0] = va.vpn[i-1:0] pa.ppn[LEVELS-1:i] = pte.ppn[LEVELS-1:i]
- 若
此轉譯演算法中,對地址轉譯資料結構的所有隱式存取都使用 PTESIZE 的寬度進行。 這代表讀取 PTE 時都是以一個完整的 PTE 為單位(Sv32 為 4B,Sv48/Sv57 為 8B),不能用小單位拆開處理
例如在 Sv48 實作中,不能使用兩次 4B 的讀取來非原子性地存取單一 8B 的 PTE; 而當實作更新 A/D bit 時,也必須視為原子性地更新整個 PTE,不能只更新 A/D bit,而忽略其他欄位的原子性,即使除了 A/D bit 外的位元都沒變
在步驟 2 中隱式地址轉譯所得到的結果,可以暫存於一個唯讀、非一致性的地址轉譯快取中,但不得與其他 hart 共用。 該 cache 可以包含任意數量的 entry,甚至可包含同一個位址與 ASID 的多個 entry
若某個快取的 entry 所對應的 ASID 與第 0 步所載入的 ASID 相符,或該 entry 是 global mapping,則該快取 entry 可用來滿足之後第 2 步的讀取。 為了確保隱式讀取能觀察到對相同記憶體位置的寫入,必須在寫入後執行一條 SFENCE.VMA 指令來清除相關的快取轉譯資料
在第 7 步中不可使用地址轉譯快取,只能直接在記憶體中更新 A/D bit,也就是說不能只改 cache 中的 shadow copy,必須真正改寫到 page table 對應的 PTE 記憶體區段中
Info
RISC-V 允許多個地址轉譯快取映射到同一個地址上。 在傳統的 TLB 階層中,如果某個 page 被升級為 superpage,但沒有先清除原先 non-leaf PTE 的 valid 位元,並執行了 SFENCE.VMA(rs1 = x0),或者在某個 TLB 階層中存在多個平行的 TLB,那就可能會有多個項目映射到同一個地址
在這種情況下,如同在對 memory-management table 寫入後未執行 SFENCE.VMA 而接著進行相同地址的隱式讀取時一樣,我們無法預測究竟會使用舊的 non-leaf PTE 還是新的 leaf PTE,但其他行為仍是有良好定義的
只要 satp 處於活動狀態(如第 12.1.11 節所定義),實作可以在任意時間,對任意虛擬位址,推測執行地址轉譯演算法,此類推測執行會預先填入地址轉譯快取
推測執行地址轉譯演算法時,其行為應與非推測執行相同,除了以下例外:
它們不得設置 PTE 的 D bit、不得觸發例外,也不得建立那些在該推測執行開始後、被該 hart 執行過的 SFENCE.VMA 指令所應無效化的地址轉譯快取項目
Tips
推測執行與一般的地址轉譯一樣,都是走 page table、更新 A/D bit、快取結果。 但這裡明確限制了推測執行不能做的幾件事:
- 不能設 D bit(dirty)
- D bit 代表有寫入操作,但推測性執行的 store 不一定會真的 commit,所以不准提早記錄。
- 不能產生例外(trap)
- 推測性執行只是預先查詢,不能導致如 page-fault、access-fault。
- 不能建立已被
SFENCE.VMA清除的快取項目- 比如你早在某個 page 建立快取後執行
SFENCE.VMA,該 page 就應失效,你不可以推測地又偷偷加回去
- 比如你早在某個 page 建立快取後執行
Info
例如,對於非推測性與推測性地址轉譯演算法來說,以下行為是非法的:
開始執行後讀取 level 2 page table,然後在 hart 執行 SFENCE.VMA(rs1 = rs2 = x0)時暫停,接著再繼續使用這個已經過時的 level 2 PTE,因為接下來的隱式讀取可能會使用過時的 PTE 來填入地址轉譯快取(失效的 PTE 被當成有效的快取資料重新加回 cache,導致不一致行為)
因此,在許多實作中,執行 SFENCE.VMA(rs1 = x0)時,會終止所有正在進行的推測性地址轉譯(針對指定的 ASID,如適用),或是等待它們完成,再清除所產生的快取項目(在這種情況下,該 SFENCE.VMA 將適當地使其建立的地址轉譯快取項目無效化)
同樣地,執行 SFENCE.VMA(rs1 ≠ x0)時,這只清除了部分虛擬地址範圍,通常必須保證正在進行的推測性地址轉譯(針對指定 ASID,如適用)無法再建立新的 leaf PTE 的地址轉譯快項目,或是等待它們完成再清除快取項目。 總之你還是要保證過去 launch 的 speculative walk 不能偷偷建立新快取,不然就等它們跑完再把快取清掉
由於規格允許實作在任意時間、以推測方式讀取地址轉譯資料結構,因此任何時候只要透過此演算法可達的所有 PTE,皆有可能被載入地址轉譯快取中。 換句話說,因為允許 speculative execution,所以任一時間,只要能走到的 PTE,都有可能被預抓(prefetch)到 cache 裡。這不是 bug,是明確被允許的設計
一般 page table 都會放在冪等(idempotent)記憶體中,表示重複存取結果一致,但規格中並未明確禁止你把它放在 I/O 或非冪等的記憶體裡。 由於演算法只會存取由 satp 指定的那棵 root page table 所可達的 page table,因此實作的 page table walker 所會觸及的地址範圍完全受 supervisor 控制
此演算法不允許在物理地址寬度較窄的實作中忽略 PPN 的高位元,換句話說,如果你是 RV32,只支援 34-bit 實體位址,不代表你可以無視 PTE.ppn[19:34],你還是要照樣使用完整的 ppn bits 來做轉譯,即使你平台上的 memory 寬度根本沒用到
12.4. Sv39: Page-Based 39-bit Virtual-Memory System
本節描述一個簡單的 page-based 虛擬記憶體系統,適用於 SXLEN=64(即 64-bit 架構),此系統支援 39-bit 的虛擬位址空間。 Sv39 的設計遵循 Sv32 的整體架構,這一節僅詳細說明兩者之間的差異
我們為 RV64 指定了多種虛擬記憶體系統,以緩解「提供更大位址空間」與「減少位址轉譯成本」之間的衝突。 對於許多系統來說,39-bit 的虛擬位址空間已經足夠,因此 Sv39 就已經足以應對。 Sv48 將虛擬位址空間增加至 48 bits,但這也提高了專門用來存放 page table 的實體記憶體容量需求、走訪 page table 的延遲,以及儲存虛擬位址所需的硬體結構的大小。Sv57 則再進一步提升了虛擬位址空間、page table 容量需求與轉譯延遲
12.4.1. Addressing and Memory Protection
Sv39 的實作支援一個被劃分為多個 pages 的 39-bit 虛擬位址空間。 一個 Sv39 的位址如下圖所示地被劃分:

指令擷取位址與 load/store 的有效位址都是 64-bit,但其 bit 63~39 的值必須與 bit 38 相等,否則就會觸發 page-fault 例外。 這個 27-bit 的 VPN 會經由三層 page table 被轉譯為 44-bit 的 PPN,而 12-bit 的 page offset 則不參與轉譯
Info
在不同位元寬度的位址之間進行映射時,RISC-V 對較窄的實體位址採用 zero-extension 以適應較寬的位元長度
但在 Sv39 中,從 64-bit 虛擬位址對映到 39-bit 的使用空間時,不是使用 zero-extension,而是採用了某種既定慣例,允許作業系統利用 64-bit 虛擬位址中的一或幾個最高位元來快速區分 user 與 supervisor 的位址區域
Sv39 的 page table 包含 512(satp 暫存器的 PPN 欄位中
Sv39 的 PTE 格式如下圖所示:

bit 9 到 0 的意義與 Sv32 相同。 bit 63 保留給第 13 章的 Svnapot extension 使用。 如果未實作 Svnapot,bit 63 必須保留並由軟體清為 0,以確保未來相容性,否則會觸發 page-fault 例外
bit 62-61 保留給第 14 章的 Svpbmt extension 使用。 如果未實作 Svpbmt,bit 62-61 也必須保留並清為 0,否則會觸發 page-fault
bit 60 到 54 保留給未來的標準用途,除非某個標準 extension 定義了這些位元的用途,否則軟體必須將其清為 0,以維持向前相容性。 如果這些位元有任一被設為 1,則會觸發 page-fault 例外
Info
我們保留了數個 PTE 位元,以供未來可能的 extension 使用,這些 extension 能夠透過允許跳過某些 page-table 層級來增進對 sparse address space(稀疏位址空間)的支援,從而減少記憶體使用量與 TLB refill 的延遲
這些保留位元也可能被用於學術研究的實驗用途。 這樣做的代價是會減少實體位址空間的可用位數,但目前仍有足夠的空間。 當這樣的位元數不足時,那些尚未分配的保留位元仍可以被拿來擴展實體位址空間
Sv39 中任何層級的 PTE 都可以是 leaf PTE,因此除了 4 KiB 的 page 之外,Sv39 還支援 2 MiB 的 megapage 和 1 GiB 的 gigapage,這些 page 必須在虛擬與實體位址空間上都對齊到與其大小相等的邊界。 如果實體位址的對齊不足,則會觸發 page-fault 例外
虛擬位址轉換為實體位址的演算法與第 12.3.2 節中所述的相同,唯一的差異是這裡的 LEVELS = 3 且 PTESIZE = 8
12.5. Sv48: Page-Based 48-bit Virtual-Memory System
本節描述一種針對 SXLEN=64(即 64-bit 架構)設計的簡單 page-based 虛擬記憶體系統,此系統支援 48-bit 的虛擬位址空間。 Sv48 是為了那些 39-bit 虛擬位址空間不敷使用的系統所設計的,它的設計與 Sv39 十分接近,僅是多增加了一層 page table,因此本章節僅說明這兩種機制之間的差異
支援 Sv48 的實作也必須支援 Sv39。 支援 Sv48 的系統基本上可以以零成本同時支援 Sv39,因此應當這麼做,以維持對那些假設系統使用 Sv39 的 supervisor 軟體的相容性
12.5.1. Addressing and Memory Protection
Sv48 的實作支援一個 48-bit 的虛擬位址空間,並將其劃分為多個 pages。 Sv48 的位址分割如下圖所示:

用於指令擷取以及載入與儲存(load 與 store)的有效位址是 64-bit,但其 bit 63 至 48 必須全部等於 bit 47,否則會觸發 page-fault 例外。 這個 36-bit 的 VPN 會透過四層 page table 轉譯為 44-bit 的 PPN,而 12-bit 的 page offset 則不參與轉譯
Sv48 的 PTE 格式如下圖所示:
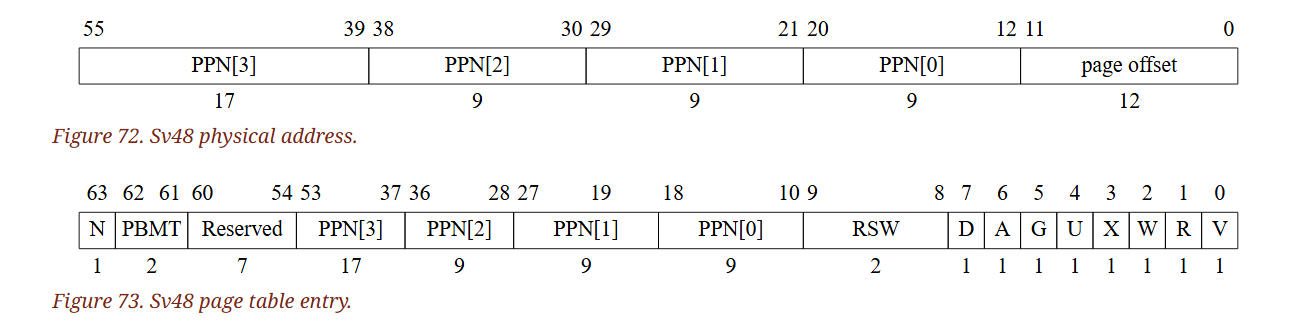
位元 63–54 與 9–0 的意義與 Sv39 相同。 Sv48 中的任意層級的 PTE 都可以是 leaf PTE,因此除了標準的 pages 外,Sv48 還支援 megapages、gigapages 與 terapages。 每一種大小的 page 都必須在虛擬與實體位址空間上對齊至與其大小相等的邊界,如果實體位址的對齊不足,將會觸發 page-fault 例外
虛擬位址轉譯為實體位址的演算法與第 12.3.2 節所述的相同,唯二的差異在於 LEVELS = 4 且 PTESIZE = 8
12.6. Sv57: Page-Based 57-bit Virtual-Memory System
本節描述一個針對 RV64 系統設計的簡單 page-based 虛擬記憶體系統,此系統支援 57-bit 的虛擬位址空間。 Sv57 是為了那些 48-bit 虛擬位址空間已經不足的系統而設計的。 它的設計與 Sv48 十分相似,只是再多增加一層 page table,因此本章節僅說明這兩種機制之間的差異
支援 Sv57 的實作也必須支援 Sv48。 支援 Sv57 的系統基本上可以以零成本同時支援 Sv48,因此應當這麼做,以維持對那些假設系統使用 Sv48 的 supervisor 軟體的相容性
12.6.1. Addressing and Memory Protection
Sv57 的實作支援一個 57-bit 的虛擬位址空間,並將其劃分為多個 pages。 Sv57 的位址分割如下圖所示:

用於指令擷取(instruction fetch)以及載入與儲存(load 與 store)的有效位址是 64-bit,但其位元 63–57 必須全部等於位元 56,否則將觸發 page-fault 例外。 這個 45-bit 的 VPN 會透過五層 page table 轉譯為 44-bit 的 PPN,而 12-bit 的 page offset 則不參與轉譯
Sv57 的 PTE 格式如下圖所示:

位元 63–54 與 9–0 的意義與 Sv39 相同。 Sv57 中的任意層級的 PTE 都可以是 leaf PTE,因此除了 pages 外,Sv57 還支援 megapages、gigapages、terapages 與 petapages。 每種大小的 page 都必須在虛擬與實體位址空間上對齊至與其大小相等的邊界,如果實體位址的對齊不足,將觸發 page-fault 例外
虛擬位址轉譯為實體位址的演算法與第 12.3.2 節所述的相同,唯二的差異是 LEVELS = 5 且 PTESIZE = 8