
ReRAM 與 Smith-Waterman Algorithm 介紹
ReRAM 與 Smith-Waterman Algorithm 介紹
這學期(大四上) 修了一門課叫新興記憶儲存系統元件設計,主要在講一些現代 Non-volatile memory,如 FRAM 和 ReRAM,還有一些較新的 Disk 的設計,如 Open-channel SSD 和 ZNS 等等的
而這門課有專題,也就是需要找個題目研讀一下,雖然老師說不需要實作出來,找個還沒被解過的問題,然後試著提解法就好,但我是個喜歡實作的人,沒有實作出來就覺得哪裡怪怪的,所以就希望能找個實作來做,不過到了期末發現真的沒有空XD
由於當初想要實作,所以要選「還沒被解過的題目」這件事變成了一個困難,首先我只有大概 2 個月的時間,要想出一個解法並實作他比單獨的理解後實作難很多,依照我的經驗,過程中如果遇到一些預期外的問題很容易找不到解法而卡住,之前有看到一篇好文可以供大家參考:因為自動飲料機而延畢的那一年
但我這學期實在是太忙了,所以我的想法很簡單,找一些別人還沒有在 Non-volatile memory 這塊做過的演算法,我用 Non-volatile memory 做一些 in-memory computing 看看,這樣一來演算法不會太難,而且會有在別的地方做過的相關論文可以參考,這大概也勉強算在「還沒被解過」的範疇內
而很剛好的,張家華學長對生物工程這方面有所涉略,真的是太猛了,我不管跑去玩什麼有的沒的,他好像都可以給我建議,真的是大神。總之,學長看了看說可以考慮把 systolic array 加進來,因為 systolic array 上面每個 cell 都是一個 memory unit,而我們又能做 in-memory computing,理論上可以做得到,而且這樣可以讓題目更落在「還沒被解過」的圈圈裡面
因此和老師和學長討論後,選的演算法就是 Smith-Waterman Algorithm 了,演算法不會太 hardcode
整個過程可以被分為兩部分:
- 利用 systolic array 實作 Smith-waterman Algorithm
- 利用 ReRAM 實作 systolic array
雖然我們因為沒有空所以沒有去實作,但經過這一兩個月的 paper survey,覺得我們的想法是可行的,整個過程的主要困難點在於 ReRAM 的 program,說實話 systolic array 的部份並不難,systolic array 可以使用很簡單的結構來做,當然也有看到弄得很漂亮的 systolic array,但內部電路就會複雜起來了
但重點還是在 ReRAM 的 program part 我們完全沒摸過,雖然知道只要能夠 program ReRAM 內的電阻部份,就能實作出基本邏輯閘,整個專案基本上就沒問題了,但礙於時間我們就沒去研究怎麼去 program 這部份了
當初老師的建議是可以使用 gem5 + NVMain 來進行模擬,google 搜了一下感覺這東西光是 build 起來就有一堆點要注意,而且目前還沒看到有哪個教學有寫說該怎麼使用,可能之後有閒再來摸摸吧 XD
Smith-Waterman Algorithm 是一個用在生物工程的演算法,由 Needleman-Wunsch 變化而來,用來做基因序列的比對,所以我們這篇文就從基因序列比對開始介紹起吧~
基因序列比對
這一段介紹轉載自基因序列比對演算法,寫得很好,我只小改了一些用詞,有興趣的可以去看看原文
一般而言,我們會把 DNA 和蛋白質分別看成是由 4 和 20 個英文字母所組成的序列或字串,因為他們分別是由 4 種核苷酸和 20 種胺基酸所組成的。對 DNA 而言,突變是非常平常的事情,也是自然的演化過程。藉由基因的突變,生物可以適應自然環境的改變
DNA突變的類型
常見的DNA突變有3種,分別是取代、插入及刪除
| DNA突變行為 | 意義 |
|---|---|
| 取代(配錯) | 把一個字母用另一個字母取代 |
| 插入 | 在 DNA 序列的某一個位置插入一個字母 |
| 刪除 | 在 DNA 序列的某一個位置刪除一個字母 |
編輯距離
通常生物學家會利用所謂的編輯距離,來衡量兩條 DNA 序列之間的相異程度。生命總是朝著最短路徑進行演化,所以兩條序列之間的編輯距離被定義為:把其中一條序列編輯轉成另外一條序列,所需最少的編輯運算個數。兩條 DNA 序列之間的編輯距離越小,代表它們之間的相似程度越高。從演化的觀點來說,這意味著它們演化自同一個祖先(即所謂的同源),所以彼此間應該會有相似的結構及功能
生物學家喜歡利用比對來衡量兩條序列之間的相似程度。拿 GACGGATAG 和 GATCGGAATAG 這兩條 DNA 序列來說,乍看之下這兩條長度不同的DNA序列似乎不太相似。但當我們如下表一般,把它們重疊在一起,並在第 1 條序列的第 2 個和第 3 個字母間,與第 6 個和第 7 個字母之間分別插入一個空白字,就可發現其實這兩條 DNA 序列還蠻相像的
| 重疊前 | 重疊後 |
|---|---|
| GACGGATAG | GA_CGGA_TAG |
| GATCGGAATAG | GATCGGAATAG |
這種將序列重疊在一起的方式,就稱為序列的比對
我們可以在兩條序列的任意位置上插入一個或多個空白字,這樣做的目的是讓相同或相似的字母能夠儘量對齊。但要特別注意的是,不能讓兩個插入的空白字對齊在一起,因為這樣對衡量序列之間的相似程度並無幫助
因此字母之間對齊的方式其實就只有2種:
- 字母與字母的對齊
- 字母與空白字的對齊
對齊(Alignment)
我們可以把 Alignment 的演算法分為 Global 與 Local 兩種
Global Alignment(全局比對):
- 目標:在整個序列的整體範圍內找到最佳的對應,強調整個序列的相似性
- 特點:將整個序列進行比對,並試圖找到一個最佳的比對方案,即最大相似性得分。這種比對通常用於比較兩個相對較相似的序列,如同一基因在不同物種中的同源基因
- 應用:常見的全局比對算法包括 Needleman-Wunsch 算法
Local Alignment(局部比對):
- 目標:在序列的某個區域內找到最佳的對應,強調局部相似性
- 特點:局部比對專注於找到序列中的局部相似區域,而不要求整個序列的相似性。這種比對通常用於比較兩個相對較不相似的序列,以尋找局部相似的區域,如同源基因的某一片段
- 應用:常見的局部比對算法包括 Smith-Waterman 算法
Needleman-Wunsch
步驟
Needleman-Wunsch 的步驟如下
初始化得分矩陣(Initialization):
給予兩個序列接下來初始化第一行和第一列的值,使第一列的每個元素等於
計算得分(Matrix Filling):
遍歷得分矩陣的每個元素
來自左上方的對角線的元素,表示匹配或不匹配的得分
來自上方的元素,表示插入的得分
來自左方的元素,表示刪除的得分
回溯(Traceback):
從右下角開始回溯,如果寫出回溯路徑
最後我們就根據回溯路徑,寫出匹配的序列了,假設輸出的序列為- 如果回溯到左上角的格子,將
- 如果回溯到上面的格子,將
_添加到 - 如果回溯到左邊的格子,將空格
_添加到
- 如果回溯到左上角的格子,將
例子
這邊給一個例子,我們考慮兩個 sequence:
N: ATGCT
M: AGCT然後設定匹配得分(Match) 為 +1,不匹配懲罰分數(Mismatch) 為 -1,插入/刪除的懲罰分數(GAP) 為 -2,因此得分矩陣(Score Matrix)初始化的樣子如下:
- A T G C T -- 序列 N
- 0 -2 -4 -6 -8 -10 -- 初始化為 0 - (-2) * i-th column
A -2
G -4
C -6
T -8
| |--初始化為 0 - (-2) * j-th row
|--序列 M然後填充,我們以
- A
- 0 -2
A -2 ?因此三個來源數值為:
- 左上方:
這邊是 - 上方:
- 左方:
三個數值中最大的數值為
- A
- 0 -2
A -2 1接下來我們往右一個元素繼續執行這個過程,
- A T
- 0 -2 -4
A -2 1 ?三個來源數值為:
- 左上方:
這邊是 - 上方:
- 左方:
三個數值中最大的為
- A T
- 0 -2 -4
A -2 1 -1對每一層持續進行這個過程,第一次完成後矩陣的樣子為:
- A T G C T
- 0 -2 -4 -6 -8 -10
A -2 1
G -4
C -6
T -8第二次迭代:
- A T G C T
- 0 -2 -4 -6 -8 -10
A -2 1 -1
G -4 -1
C -6
T -8整個流程完成後,矩陣的樣子為:
- A T G C T
- 0 -2 -4 -6 -8 -10
A -2 1 -1 -3 -5 -7
G -4 -1 0 0 -2 -4
C -6 -3 -2 -1 1 -1
T -8 -5 -2 -3 -1 2Score Matrix 填充完畢後,開始從右下角回溯,找到最佳路徑
由
因此整體路徑為:
方向的話為:
N': ATGCT
M': A-GCTSmith-Waterman
與全局比對算法(如 Needleman-Wunsch)不同,Smith-Waterman 專注於找到序列中的局部相似區域,並計算這些區域的最大得分
步驟
Smith-Waterman 的步驟如下:
初始化得分矩陣(Initialization):
給予兩個序列接下來初始化第一行和第一列的值初始化為
計算得分(Matrix Filling):
遍歷得分矩陣的每個元素- 如果這三個數值的最大值小於
來自左上方的對角線的元素,表示匹配或不匹配的得分
來自上方的元素,表示插入的得分
來自左方的元素,表示刪除的得分
- 如果這三個數值的最大值小於
找到最大得分
在填充矩陣的過程中將最大值的值與位置記錄起來回溯(Traceback):
從最大值的位置開始回溯,如果寫出回溯路徑
最後我們就根據回溯路徑,寫出匹配的序列了,假設輸出的序列為- 如果回溯到左上角的格子,將
- 如果回溯到上面的格子,將
_添加到 - 如果回溯到左邊的格子,將空格
_添加到
- 如果回溯到左上角的格子,將
例子
這邊我使用一篇 CSDN 裡面的例子,我們考慮兩個 sequence:
N: TGTTACGG
M: GGTTGACTA然後設定匹配得分(Match) 為 +3,不匹配懲罰分數(Mismatch) 為 -3,插入/刪除的懲罰分數(GAP) 為 -2
首先將得分矩陣(Score Matrix)初始化:
- T G T T A C G G -- 序列 N
- 0 0 0 0 0 0 0 0 0
G 0
G 0
T 0
T 0
G 0
A 0
C 0
T 0
A 0
|--序列 M然後填充,我們以
- T
- 0 0
G 0 ?因此三個來源數值為:
- 左上方:
- 上方:
- 左方:
由於三個數值中最大的為
- T
- 0 0
G 0 0接下來我們往右一個元素繼續執行這個過程,
- T G
- 0 0 0
G 0 0 ?三個來源數值為:
- 左上方:
- 上方:
- 左方:
由於三個數值中最大的為
- A T
- 0 0 0
A 0 0 3對每一層持續進行這個過程,第一次完成後矩陣的樣子為:
- T G T T A C G G
- 0 0 0 0 0 0 0 0 0
G 0 0
G 0
T 0
T 0
G 0
A 0
C 0
T 0
A 0第二次迭代:
- T G T T A C G G
- 0 0 0 0 0 0 0 0 0
G 0 0 3
G 0 0
T 0
T 0
G 0
A 0
C 0
T 0
A 0整個流程完成後,矩陣的樣子為:
- T G T T A C G G
- 0 0 0 0 0 0 0 0 0
G 0 0 3 1 0 0 0 3 3
G 0 0 3 1 0 0 0 3 6
T 0 3 1 6 4 2 0 1 4
T 0 3 1 4 9 7 5 3 2
G 0 1 6 4 7 6 4 8 6
A 0 0 4 3 5 10 8 6 5
C 0 0 2 1 3 8 13 11 9
T 0 3 1 5 4 6 11 10 8
A 0 1 0 3 2 7 9 8 7Score Matrix 填充完畢後,開始從最大值的位置回溯,找到最佳路徑
最大值為 13,其位於
回溯路徑如下圖:
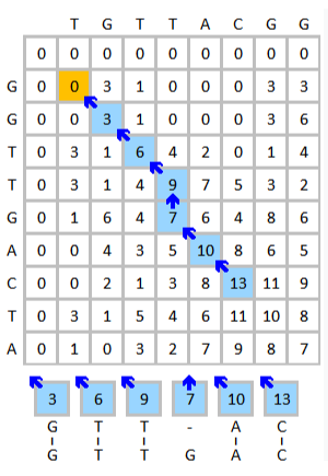
因此最終得到的序列為
N': GTT_AC
M': GTTGACSystolic Array
這邊使用一下清大林永隆教授數邏的上課內容來介紹 Systolic Array,建議大家也可以去看看上課影片:
Systolic Array 是由孔祥重院士提出的,問題的起因是把東西從 cache 搬到 register 的開銷其實是實際進行運算的開銷的好幾倍,若我們搬完一筆數據後只拿去運算一次就移走他,之後用到他的時候才又把它搬回來,就會造成另一筆額外且相對大的開銷
所以核心的思想就是讓資料搬進 register 後要好好的被利用,做很多很多的運算,做完後才把數據移走,實作的方式有 pipeline 的味道在裡面
下圖中的「PE」是運算單元,可以看見其將數據一次性地經過了多個 PE:
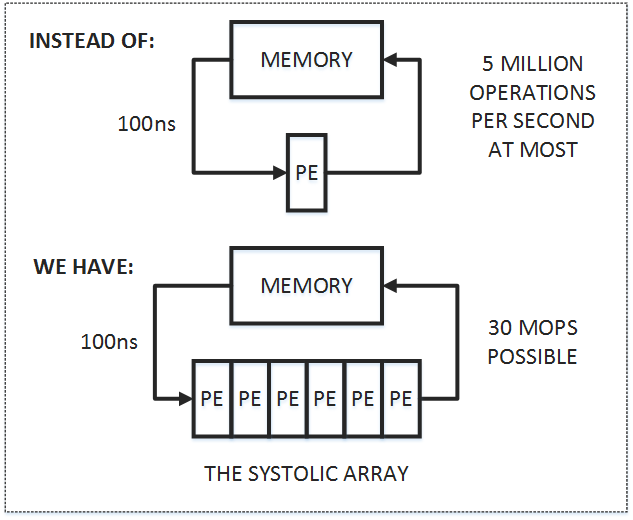
所以你可以猜到並不是所有的運算都適合利用 systolic array 來運算,因為數據並不一定符合「能一次性地做很多很多的運算」的這個特性
例子 1
那麼有什麼樣的運算符合呢? 在孔祥重院士的論文中舉了一個例子:捲積(Convolution)
我們先從一維的開始下手,Convolution 是現代很常使用到的計算方法,在 Convolution 的運算中會有兩個輸入序列,這邊假設輸入為
並且 Convolution 會有一個輸出序列,這邊假設輸出為 3 為
因此
按照這個方式計算過後,
此時孔院士就發現這可以有很多種算法,首先我們可以讓
假設一個開始 t = 0,則當 t = 3 時整個架構會長得像這樣:
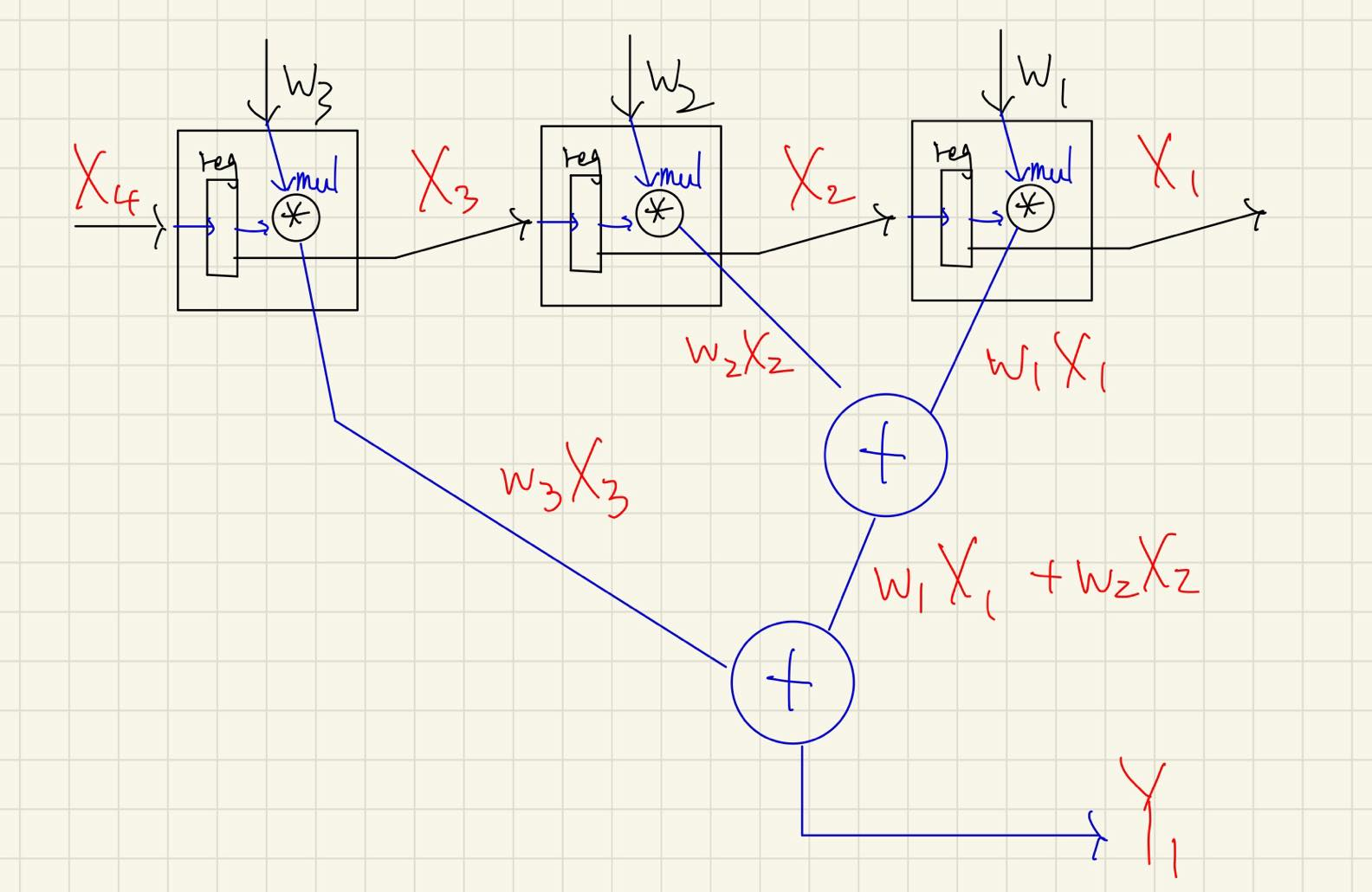
上圖中有三個 PE,每個 PE 內有一個 register 用來存進來的
可以再多看一個
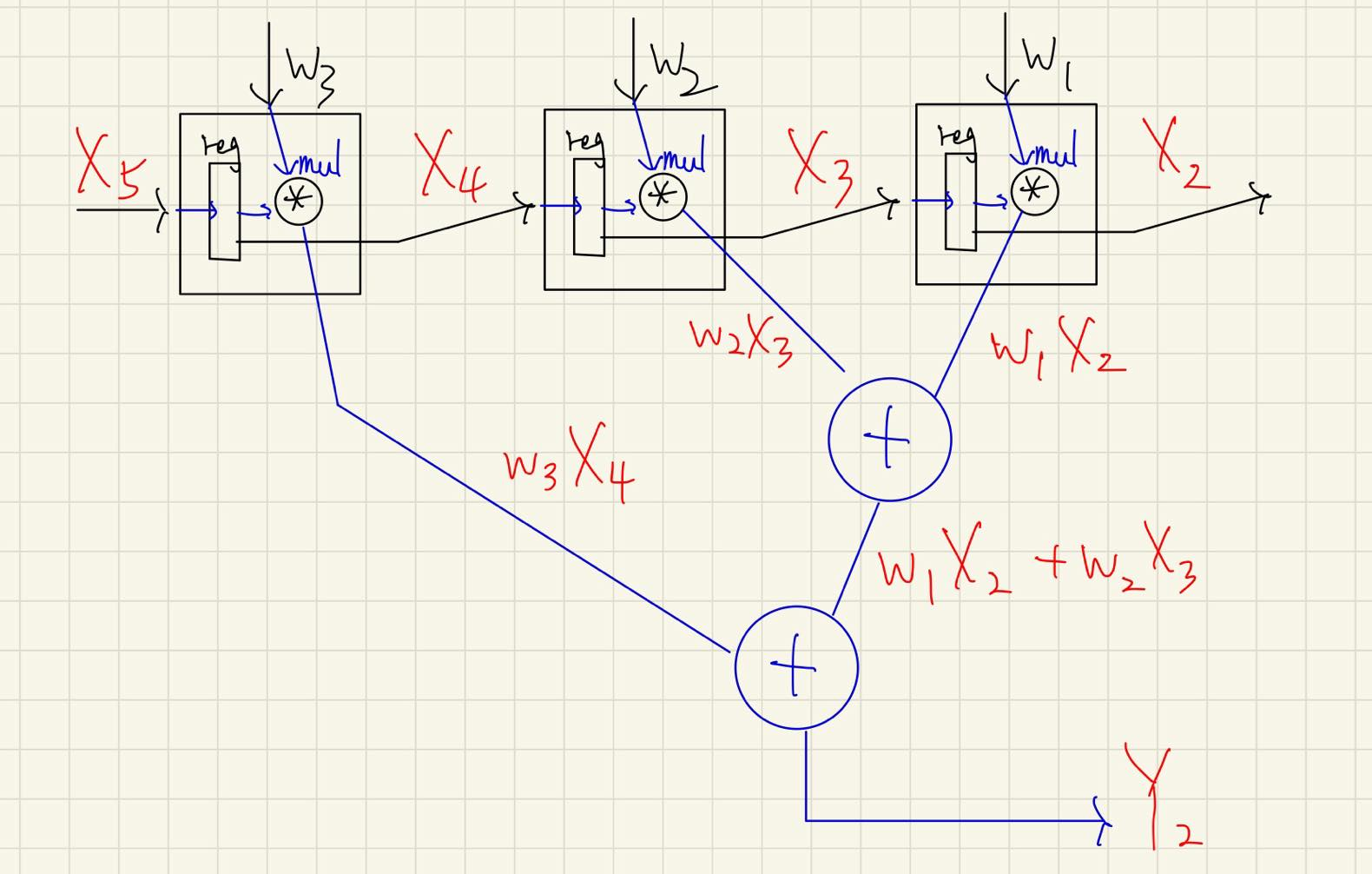
而還有其他的方法,如孔院士提出的 broadcast inputs, move results, weights stay:
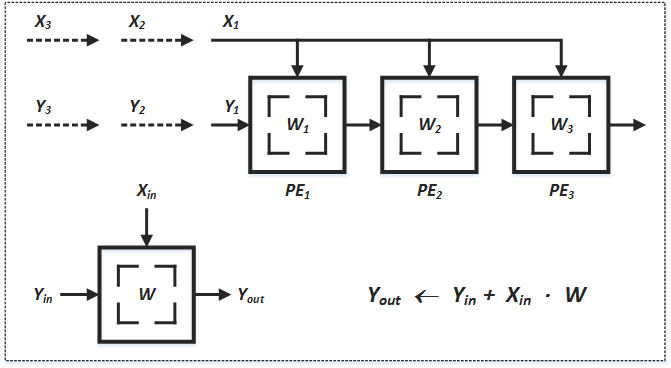
在上例中,
從上例你也可以很簡單的看出到 t = 3 的時候,
這樣的電路架構我們稱它為 Systolic Array,你可以看見它的結構非常的簡單且 Regular,每個 PE 做的操作都一樣,操作也不複雜,然而也因此導致其 Systolic Array 泛用性不高,很難同一組 Systolic Array 拿去做不同場合的運算,需要針對不同的場合設計不同的 Systolic Array
例子 2
接下來我們看一下二維的例子:矩陣運算
這也是 Google TPU 的應用,拿來做 ML 加速
假設我們現在有兩個 Array 做相乘,寫作
則
這個的 Systolic Array 會有四個 PE,整體步驟如下圖所示:
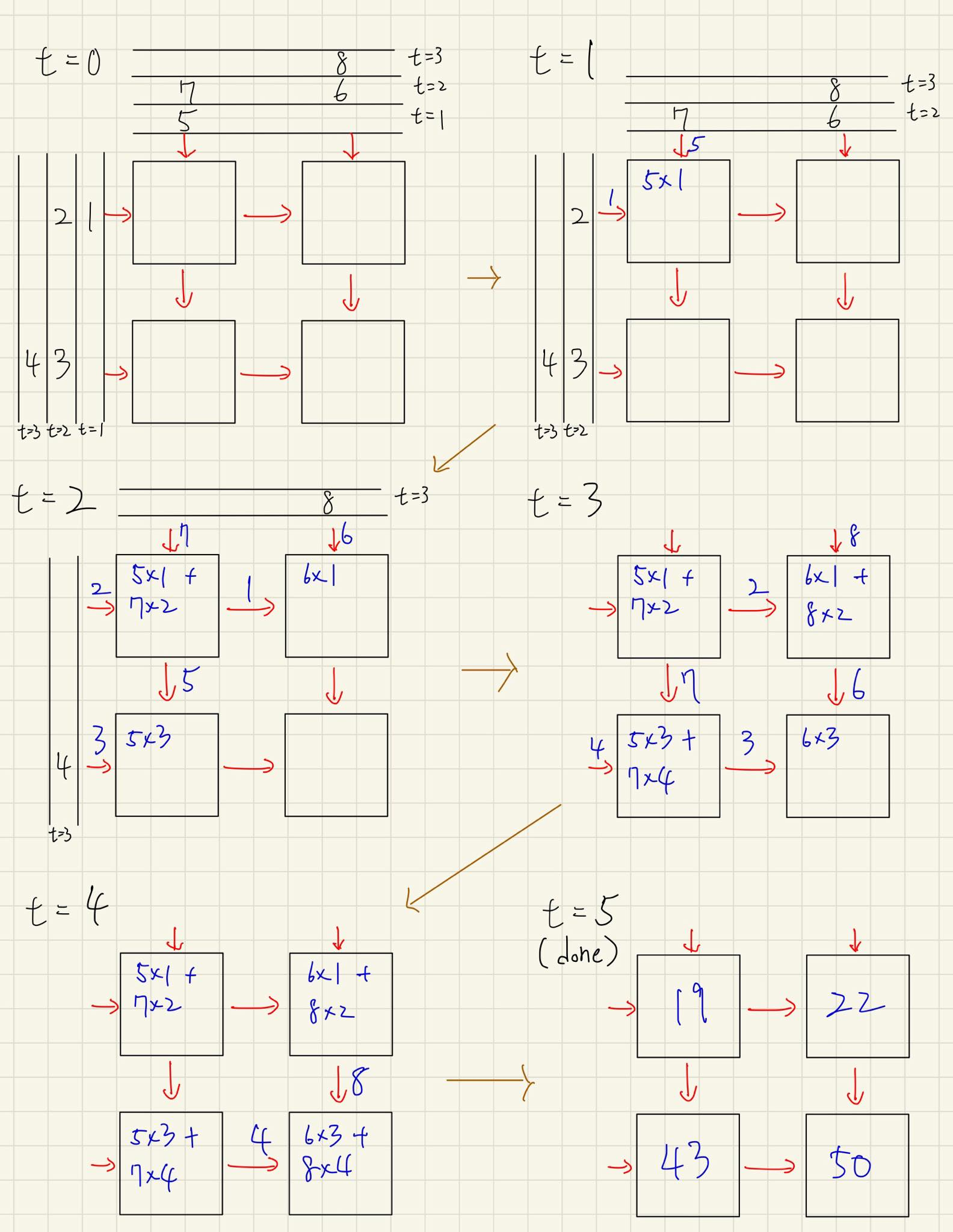
原先的矩陣乘法,一個
註:t = 0 還沒開始運算,所以不算在 cycle 內,以這個例子來說 t = 1 到 t = 5
ReRAM (RRAM)
ReRAM 是一種新型的非揮發性記憶體,所謂的「非揮發性」表示斷電後 memory 內的數據並不會消失,會被保存下來,跟目前主流的 DRAM、SRAM 不一樣
具我所知目前 ReRAM 還沒有終端產品,ReRAM 基於內部的可變電阻,可以通過改變 memory cell 內的的電阻來實現 in-memory computing,而至於內部的物理長怎樣我也不會,所以這邊就不多闡述,但有一部影片講得還不錯,有興趣的可以看看:EE Research Talk—Next generation memory technology: a Resistive Random-Access (ReRAM) Memor
這邊簡單寫一下 ReRAM 裡面的架構,ReRAM 的基本單元是由兩個電極之間的一層絕緣材料構成,稱為 ReRAM cell。這兩個電極通常被稱為「頂電極(Top Electrode)」和「底電極(Bottom Electrode)」。兩個電極之間的絕緣材料通常是一種氧化物,像是氧化鋯(Zirconium Oxide)
比較特別的地方在於中間那個絕緣材料有可變電阻的特性。當電流通過 ReRAM cell 時,這會導致絕緣材料中的一部分變成導體,改變電阻值。這個改變是可逆的,可以通過反向電流(負極->正極)或其他方法將它恢復
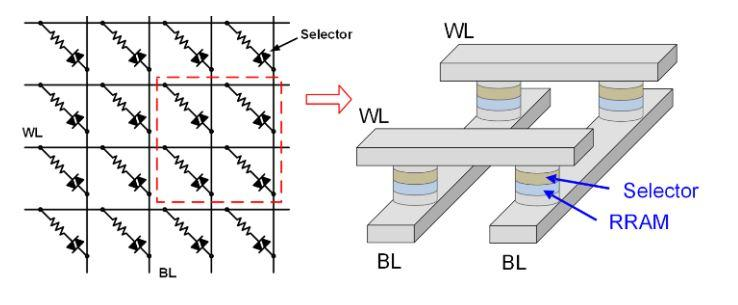
當 ReRAM 單元處於高阻態(HRS)時,表示存儲的是數據位「0」;當處於低阻態(LRS)時,表示存儲的是數據位「1」。通過對 ReRAM cell 施加適當的電壓,可以在兩種狀態之間切換
ReRAM 也可以有 Multi-level 的型態,在這種情況寫一個 ReRAM cell 就可以表示多個 bits,做法是將電壓的區間切分的更細,如切成四等分,那麼便可以表示四種狀態:00、01、10、11,這樣的 memory cell 我們稱為 Multi-level cell
有一篇知乎寫得也不錯,但因為他禁止轉載,所以連結放這邊建議大家可以點進去看看:閱讀筆記一:RRAM (ReRAM)
而 In-Memory Computing 是一種將計算操作直接執行在儲存設備中的計算模型,像是這邊的儲存設備就是 ReRAM,另外還有 DRAM In-memory computing 等等的。這種模型消除了傳統計算模型中從需要把數據搬移到處理器造成的傳輸瓶頸,提供了更高效的計算方式
至於該如何計算,這邊舉個例子,假設我們現在有四個 ReRAM cell:
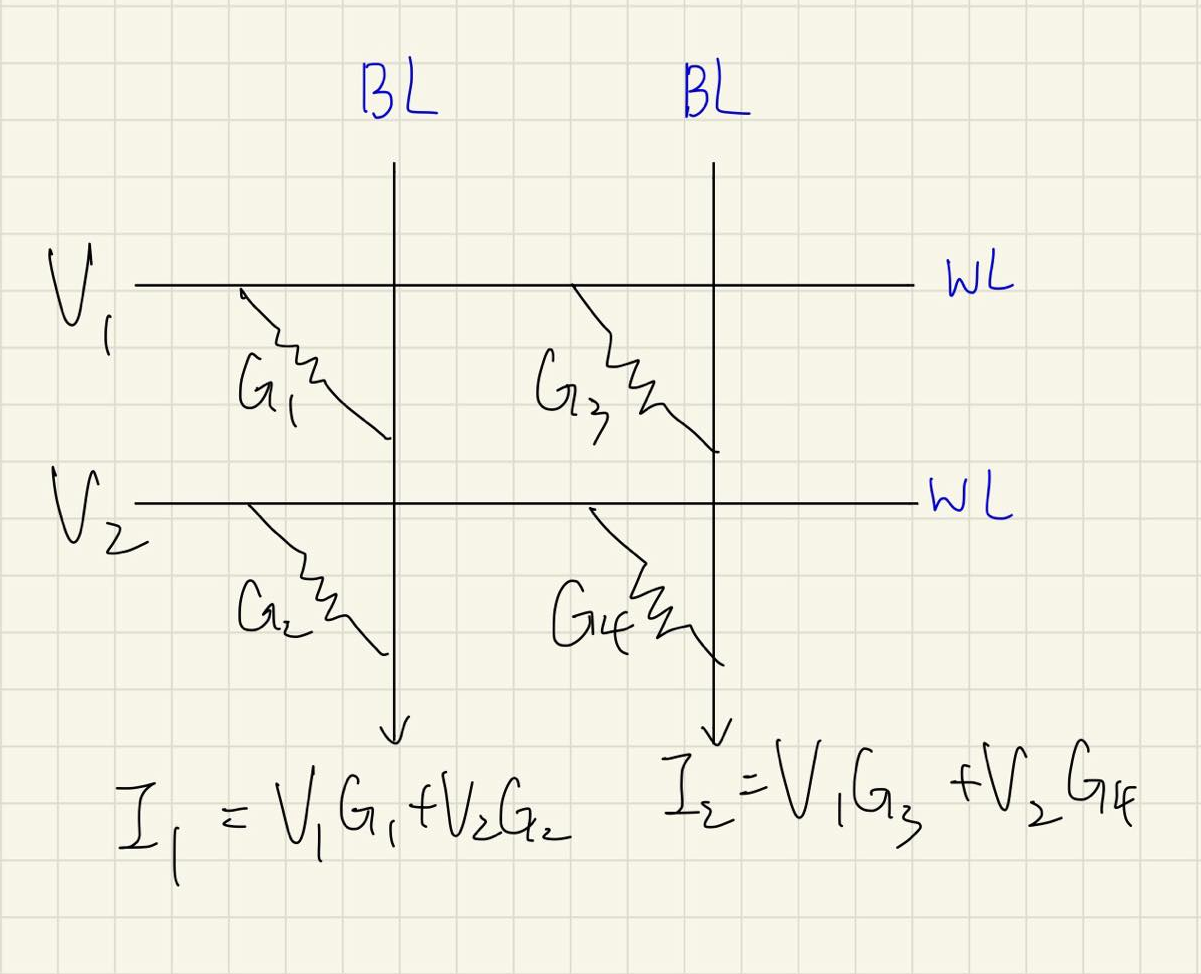
當我們設定 WL 上的電壓
這個就可以拿來做矩陣運算,假設我們今天想要算的運算為
我們就可以將電壓與電阻設為特殊的數值來計算出我們要的結果:
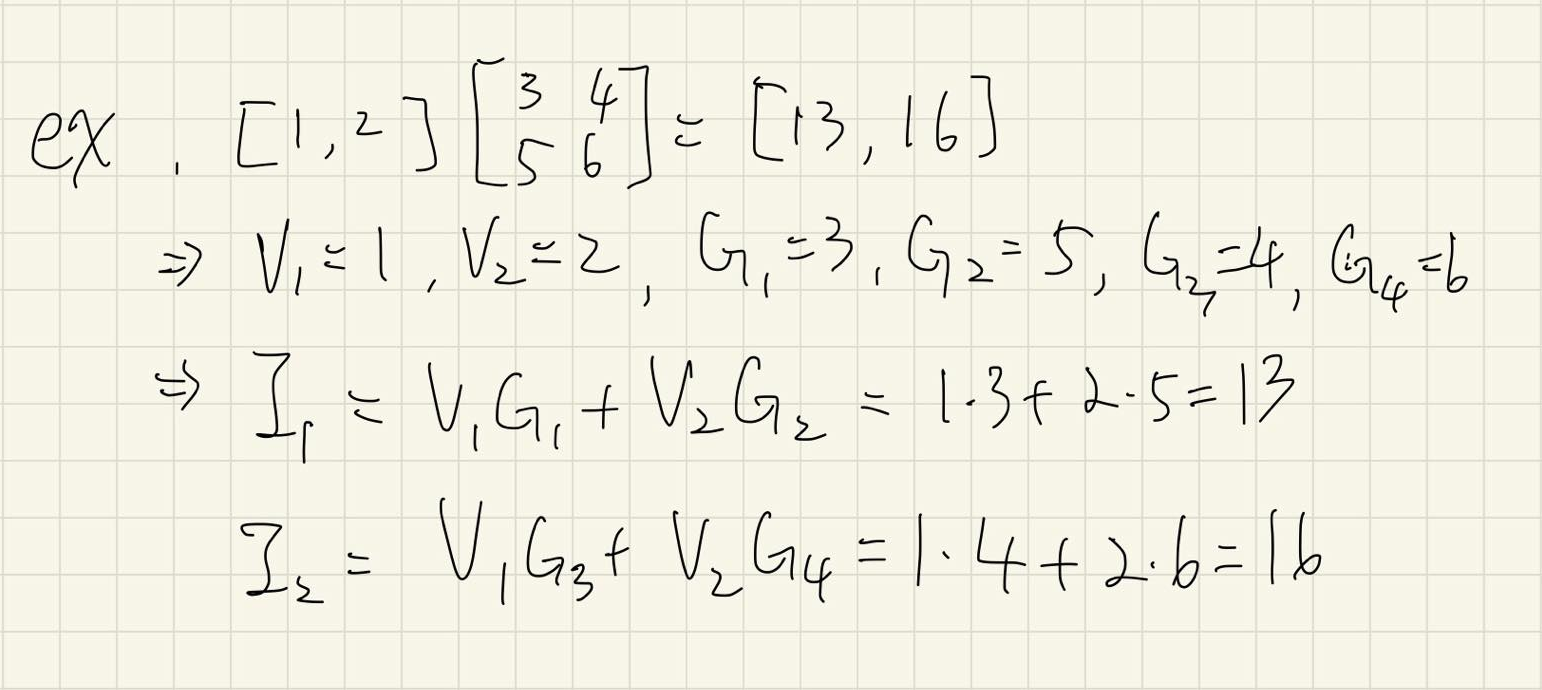
如此一來就完成了一個矩陣運算,另外,這種一個 Vector 與 Matrix 的乘法操作有個名字稱為 matrix-vector-multiplication,簡寫為 MVM,常出現在論文裡面
實作思路
我們的思路主要如下:
- 設計出 SW 演算法的 Systolic Array
- 確認 Systolic Array 內部的 PE 樣貌
- 確認使用到的 gate 是否可以在 ReRAM 上實現
- 如果可以,那理論上就可以在 ReRAM 上實作出 SW 演算法的 Systolic Array
設計出 SW 演算法的 Systolic Array
這邊以「A Systolic Array Architecture for the Smith-Waterman Algorithm with High Performance Cell Design」這篇論文內的設計為主,這篇論文使用的是比較直觀的設計方法,因此非常簡單易懂
這裡主要做的是 SW 填充步驟的平行化,以下面這個矩陣為例:
- A T G C T
- 0 -2 -4 -6 -8 -10
A -2 1 -1 -3 -5 -7
G -4 -1 0 0 -2 -4
C -6 -3 -2 -1 1 -1
T -8 -5 -2 -3 -1 2他的 Systolic Array 應該要是以下形式:
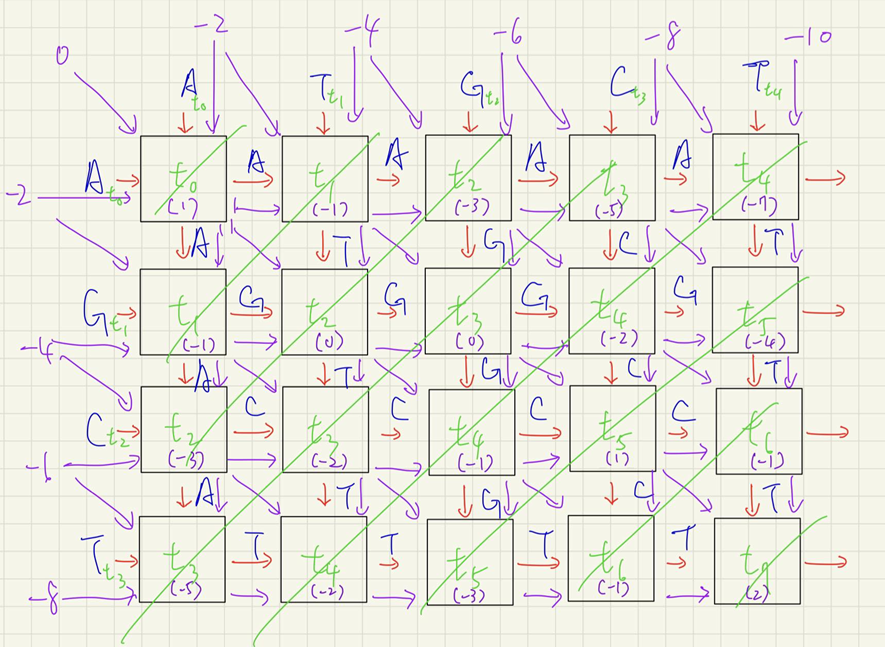
可以看見他將整個矩陣的運算優化到了 7 個 cycle
Systolic Array 內部的 PE 樣貌
而每個 PE 的設計也很簡單:
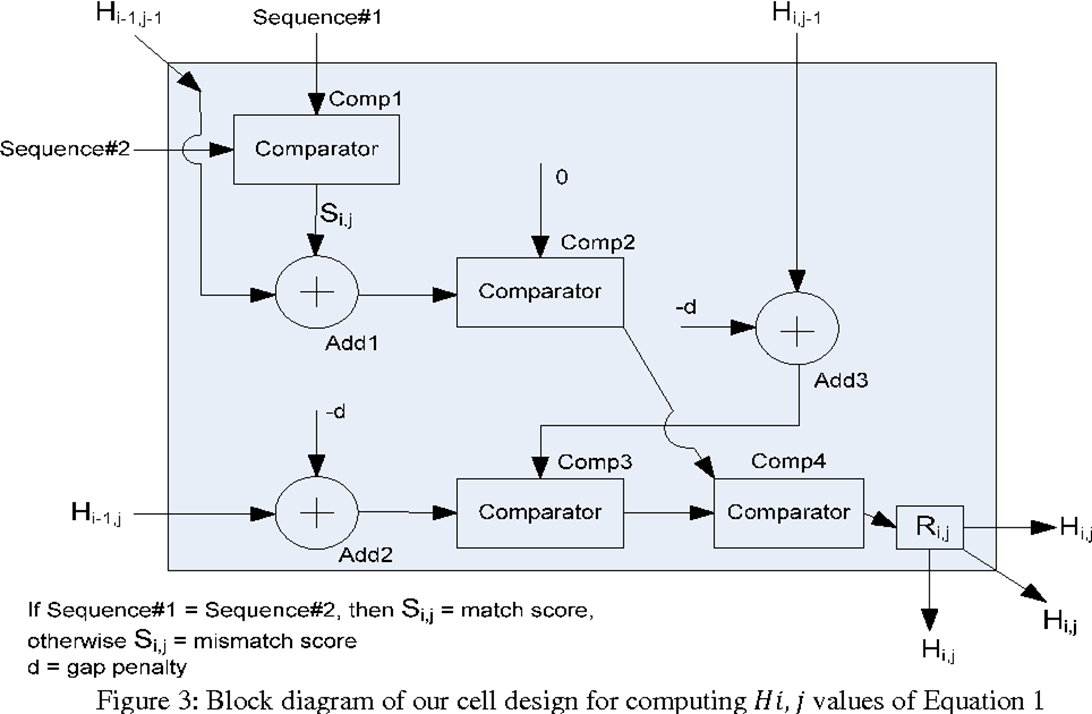
其中,當 Sequence\#1 等於 Sequence\#2 時,
而 Comparator 的本體也不難,由於是比較等於,網路上一找馬上就有簡單的實作出來了:
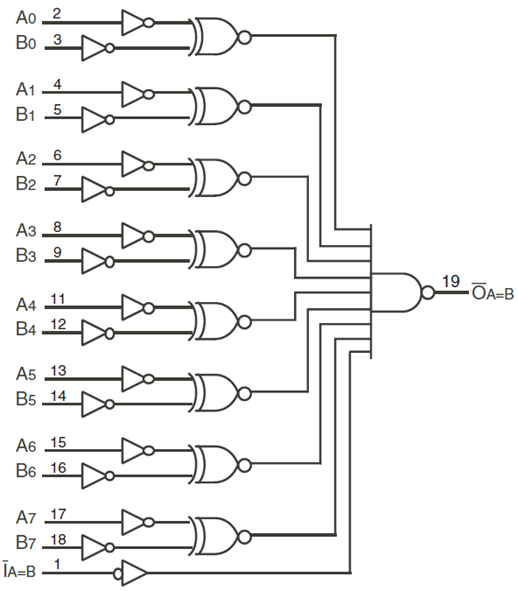
其中的 XOR 可以用 NOR 實作出來:
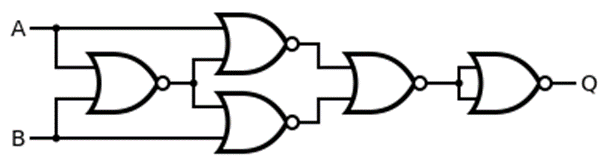
NOR gate on ReRAM
所以我們接下來需要確認 ReRAM 上是否能實作出 NOR gate 的功能,這邊有兩篇我覺得寫得蠻清楚的論文,各提了一種方法來實作,這邊就把兩篇論文的想法都很簡化的講解一下
OR gate + NOT gate
這個是「Nonvolatile Logic and In Situ Data Transfer Demonstrated in Crossbar Resistive RAM Array」這篇論文提出來的方法
主要有幾個重點:
- 用「電阻」儲存變數
- LRS 對應到 1,HRS 對應到 0;LRS 代表低電阻,HRS 代表高電阻
- cell 會被初始化為 0,RESET 操作也是將 cell 設為 0
- 當目標電流大於限制電流(CC) 時,會進行 SET 操作,將 OUTPUT 設為 1
論文中給出的範例如下,首先有三個 cell:
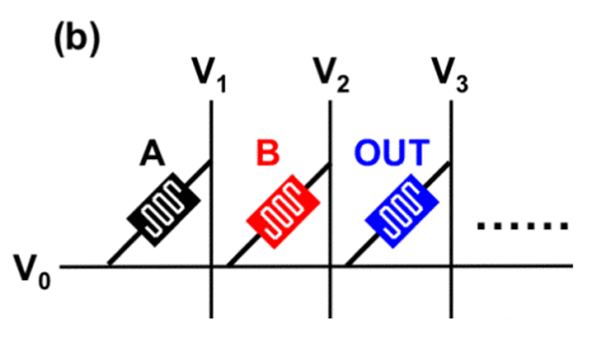
A、B 是我們輸入的兩個變數,而 OUT 是對應的輸出,當我們給定電壓,讓電流從左邊通過時,其電流如下:
首先假設 CC 電流為 1mA:
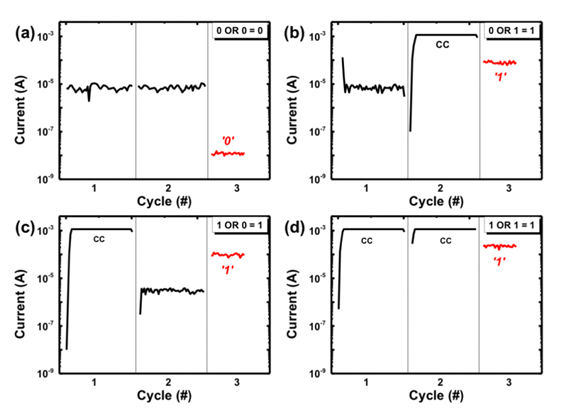
- 當 A、B 都為 0 時,由於都是高電阻,因此流過兩個 cell 的電流都不會大於 CC 電流
- 當 A、B 為 0、1 時,由於 B 被設為低電阻了,因此經過此 cell 時電流大於 CC 電流,進行 SET 操作,將 OUT 設為 1,也因此會輸出 1
- 當 A、B 為 1、0 時,由於 A 被設為低電阻了,接下來同上
- 當 A、B 為 1、1 時同理
如此一來便完成了 OR gate,接下來的 NOT gate 更簡單了:
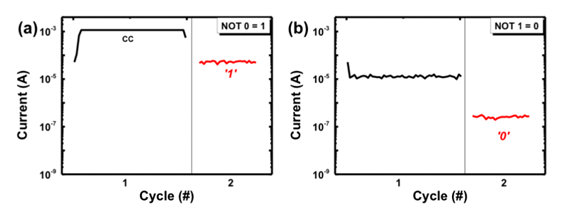
Truth table
這個是「Efficient in-memory computing architecture based on crossbar arrays」這篇論文提出的方法
重點為:
- 以電壓傳遞變數
- 事先利用可變電阻將目標 gate 的真值表存起來
- 偵測輸入電壓後的目標電流對應的電阻值
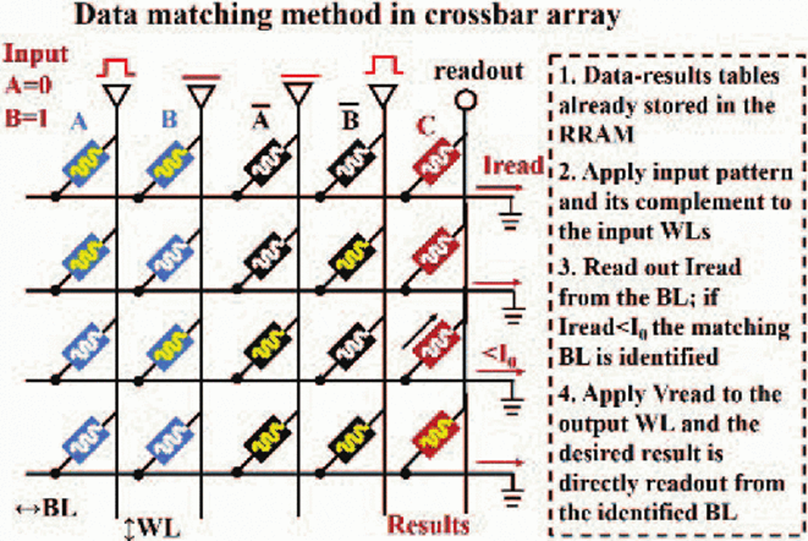
上圖是 NOR gate 的例子,電阻塗黃表示 1,塗白則為 0
我們會將變數的 0、1 分別以低、高電壓表示,至於多低、多高則自己定義,論文內舉了 2V 與 4V 為例子
因此當 2V 與 4V 傳入圖中對應的 WL(直行) 時,等我們傳入 readout 電壓,便只有第三列的電流會小於我們所設定的限制電流,我們就可以讀取對應的電阻值,得到的輸出了
結論
透過簡單閱讀上面這兩篇論文,我們已經確認了 NOR gate 可以在 ReRAM 上被實作出來,而 NOR gate 是 functional complete 的,因此基本上想組什麼出來都是沒問題的,但 performance 怎麼樣就不好說了XD
因為時間關係把整個過程簡化了許多,但已經確認這個想法確實是可行的,接下來就是等有閒的時候來嘗試實作看看了
實際實作下去會冒出很多我們現在沒想到的問題,如果有人看到這篇文,有興趣也歡迎去玩玩看,和我分享結果XD
另外「Protein Alignment Systolic Array Throughput Optimization」這篇論文對 SW 的 Systolic Array 進行了改良,Systolic Array 變得很小,而且使用率變得更好了,但 PE 的內部電路相對就變得複雜了起來,有興趣的也可以看看
Survey of related paper
「對齊」的演算法的加速仍受到現有的硬體架構限制,因其資料量大,register 容量相對來說有限,因此需要頻繁的移動資料,導致計算成本高昂,另外對齊演算法並不是單純的矩陣運算,這也會導致難以優化
- AligneR: A Process-in-Memory Architecture for Short Read Alignment in ReRAMs
- 提出了一種使用 RRAM 設計的 Hamming Distance Unit,用來加速計算基因序列片段的漢名距離,並透過這個 RHU(ReRAMbased HD unit) 構建了一個完整的 AligneR 管道來最大化讀取對齊的 throughput
- DNA Pattern Matching Acceleration with Analog Resistive CAM
- Enabling Highly-Efficient DNA Sequence Mapping via ReRAM-based TCAM
- FindeR: Accelerating FM-Index-Based Exact Pattern Matching in Genomic Sequences through ReRAM Technology
- RASSA: Resistive Prealignment Accelerator for Approximate DNA Long Read Mapping
- Seed-and-vote based in-memory accelerator for DNA read mapping
- RePAIR: A ReRAM-based Processing-in-Memory Accelerator for Indel Realignment
- PSB-RNN: A Processing-in-Memory Systolic Array Architecture using Block Circulant Matrices for Recurrent Neural Networks
- 提出了一種基於 ReRAM crossbar based PIM 架構,結合了 block circulant compression for RNNs,設計了一種 Systolic Array 來加速運算
- 註:block circulant compression for RNNs 是一種用來減少 RNN 模型的參數數量的方法
- MAX
- 提出了一種在 ReRAM 上實作的 Systolic Array,用來加速 CNN 的運算
- Protein Alignment Systolic Array Throughput Optimization
- 提出了一種改良過的 Systolic Array 來實作 Smith-Waterman
- 改良的點著重在於當 RNA 有 Internal loop 時,一般直觀的 Systolic Array 設計會有效能劇減的問題
- A survey on processing-in-memory techniques: Advances and challenges
- A Survey of ReRAM-Based Architectures for Processing-In-Memory and Neural Networks
- RAPIDx: High-performance ReRAM Processing in-Memory Accelerator for Sequence Alignment
- Resistive-RAM-Based In-Memory Computing for Neural Network: A Review
- Why systolic architectures?
- A Systolic Array Architecture for the Smith-Waterman Algorithm with High Performance Cell Design.
- 設計了給 SW 用的 Systolic Array
- Accelerated Addition in Resistive RAM Array Using Parallel-Friendly Majority Gates
- 在 ReRAM 上實作了 majority gate
- Efficient in-memory computing architecture based on crossbar arrays
- 在 ReRAM 上實作了 NOR gate,並進一步實作了全加器和乘法器
- Efficient Implementation of Boolean and Full-Adder Functions With 1T1R RRAMs for Beyond Von Neumann In-Memory Computing
- Nonvolatile Logic and In Situ Data Transfer Demonstrated in Crossbar Resistive RAM Array
- 在 ReRAM 實作了 NOR gate
論文外的參考資料
- 基因序列比對演算法
- Global alignment vs. Local alignment vs. Semi-global alignment
- Global Sequence Alignment & Needleman-Wunsch || Algorithm and Example
- Smith-Waterman算法、Needleman-Wunsch算法的算法原理及算法比较
- 閱讀筆記一:RRAM (ReRAM)
- 脈動陣列- 因Google TPU獲得新生
- 應用於神經網路之電阻式記憶體內運算
- What is In-Memory Computing?
- Systolic Array for Smith-Waterman
- EE Research Talk—Next generation memory technology: a Resistive Random-Access (ReRAM) Memory