
TBDR 簡介
TBDR 簡介
Alan Jian 大神實作了一個基於 TBDR 架構,針對 real-time rasterization 的硬體算繪器,簡單來說 Raster I 是一個能在 Arty A7 等 FPGA 平台上運作的簡易 GPU,目前能順暢地畫出 3000 個平面的 Stanford Lucy 模型,且能透過 Phong shading model 計算光影並對頂點資料進行插值。
最近大神正在申請大學,因此很需要星星,如果各位願意順手幫忙按顆星星,分享出去就太感謝了,有興趣的也歡迎點進去看看大神的 README,XD
專案 Github:https://github.com/alanjian85/raster-i
手機上的 GPU 有著功耗的限制,這和手機電池的壽命息息相關。 而記憶體頻寬是影響功耗的一大因素,資料移動的開銷相對於計算來說大很多,因此在手機的 GPU 設計上,往往會採取不同的策略來減少記憶體頻寬。
以傳統的 OpenGL virtual pipeline 來說,其往往需要大量的頻寬,通常對於每個像素,我們都需要讀寫 depth/stencil buffer,之後還需要寫入 color buffer。
假設沒有 overdraw、blending、multipass algorithms、multisampling 等等的附加功能,這還是需要 12 bytes 的 traffic。 若把這些附加功能考慮進來,每個像素將產生超過 100 bytes 的 memory traffic。 雖然現代 PC 的 GPU 使用的 IMR 架構會有 compression tech 來減少頻寬,但對於手機來說這開銷仍然不小。
為了減少這種大量頻寬的需求,現代手機的 GPU 基本上使用的是另一種稱為 Tile-based rendering 的架構,簡稱為 TBR 或 TBDR。
在這種架構上, GPU 將 framebuffer,包括 depth buffer、multisample buffers 等等的緩衝區從主記憶體移到了 hgih-speed on-chip memory 上。 因為 memory 是 on-chip 的,而且靠近計算單元,因此 access 它所需要功耗會小很多。 這樣的 memory 被稱為 Tile memory。
然而可想而知,這類的 memory 就會很小,on-chip framebuffer 的大小因 GPU 而異,但可以小到只有 16x16 個像素。 針對這種這麼小的 framebuffer,我們將其稱為 tile buffer。
所以故事就開始了,大家開始想要如何利用這麼小的 tile buffer 畫出高解析度的圖像。 對於 OpenGL 來說,它將 OpenGL 的 framebuffer 拆成了 16x16 的 tiles,一次針對一個 tile 做 rendering,也因此才會有 tile-based rendering 一詞。
對於每個 tile,所有有效的 primitives 都會被 render 到 tile buffer 中。 當完成了一個 tile,便會將其複製回功耗較高的主記憶體內。 因此主記憶體內就不需要存 depth/stencil 的值、overdrawn 的 pixels,也沒有 multisample buffer 的資料了。 depth/stencil 的 testing 和 blending 全都在 on-chip 的 memory 內完成。
因此 TBDR 的優勢主要在於有效使用 on-chip memory,使常見的像速處理於 GPU 內高速完成,不用 access主記憶體。 針對那些只在 render pass 內需要的資料還可以於 Tile 完成時直接捨棄掉,省下更多的記憶體頻寬。
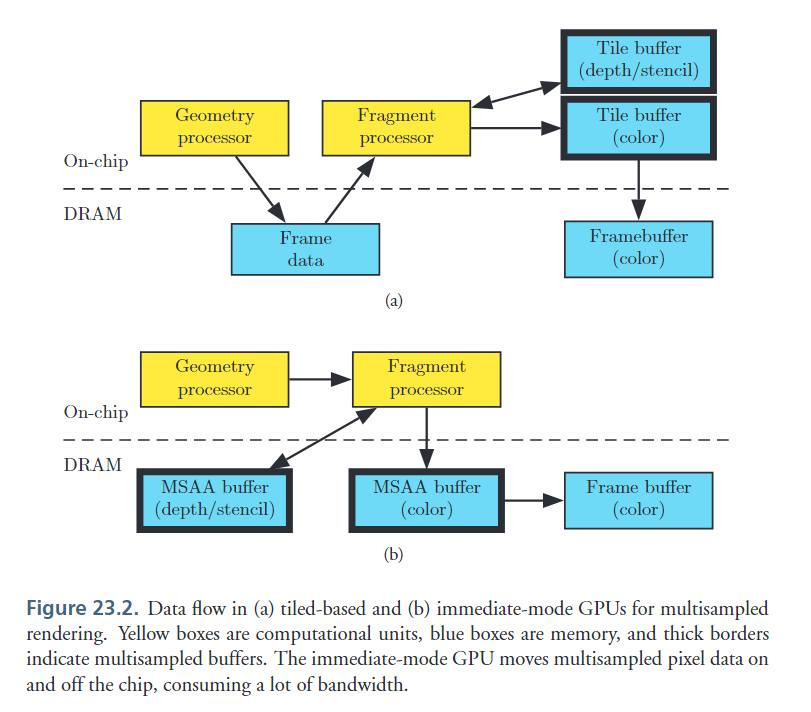
然而缺點就是,因為必須使用主記憶體來存放處理好的幾何資料,因此針對幾何處理的成本會比 IMR 還要高,因為硬體需要額外的記憶體頻寬跟空間來暫時存放幾何處理後的資料,所以對於那些會增加幾何複雜度的功能,像是 geometry shader,都會比較不適合用於 TBDR 中。
本文整理及修改自 OpenGL insights 的第 23 章,想看更多的話可以讀一下原書,或是之前 arm 社群的科普教學: