
xv6 riscv book chapter 7:Scheduling
xv6 riscv book chapter 7:Scheduling
任何作業系統在執行時,通常會有比電腦實際擁有的 CPU 數量還多的 process,因此必須有一套計劃來讓這些 process 能夠輪流使用 CPU。 理想上,這種共享機制對使用者的 process 來說應該要是透明的。 常見的做法是透過「multiplexing」的方式,把多個 process 映射(multiplex)到實際的硬體 CPU 上,讓每個 process 產生擁有自己虛擬 CPU 的錯覺。 本章會說明 xv6 是如何實現這樣的 multiplexing 的
7.1 Multiplexing
xv6 的 multiplexing 機制會在兩種情況下讓某個 CPU 從一個 process 切換到另一個。 第一種是當 process 呼叫會阻塞(也就是需要等待某些事件才能繼續)的系統呼叫時,例如 read、wait 或 sleep,此時會透過 xv6 的 sleep 與 wakeup 機制來切換; 第二種是為了應對那些長時間運算而不會阻塞的 process,xv6 會定期強制讓 CPU 切換到其他 process。 前者稱為「自願切換(voluntary switches)」,後者則稱為「非自願切換(involuntary switches)」。 透過這些切換,xv6 創造出每個 process 各自擁有一顆 CPU 的錯覺
要實作 multiplexing 有幾個挑戰:
- 第一,該如何從一個 process 切換到另一個?
- 基本的作法是儲存與還原 CPU 的暫存器,不過因為這種行為無法用 C 來表達,所以會比較麻煩
- 第二,該如何讓「強制切換」對 user process 來說是透明的?
- xv6 採用了一個標準技巧,由硬體 timer 所觸發的中斷來驅動 context switch
- 第三,由於所有 CPU 都會在同一組 process 間切換,因此必須設計一套鎖定策略以避免 race condition
- 第四,當一個 process 結束時,它的記憶體與其他資源必須被釋放,但 process 自己無法完成這些釋放動作
- 例如 process 無法在其還在使用 kernel stack 的情況下釋放那塊 stack,需要其他 thread 幫它收尾
- 第五,對於多核機器,每顆 CPU 都必須記住自己目前正在執行哪個 process,這樣系統呼叫才能正確地作用在那個 process 的 kernel 狀態上
- 最後,
sleep和wakeup機制允許 process 放棄 CPU,並等待其他 process 或中斷將它喚醒,而這裡需要特別小心,避免 race condition 導致喚醒通知被遺失
7.2 Code: Context switching
圖 7.1 說明了從一個 user process 切換到另一個時所經歷的步驟:首先是從 user space 發出 trap(可能是 system call 或 interrupt),轉入舊 process 的 kernel thread; 接著切換到目前 CPU 的 scheduler thread; 然後切換到新 process 的 kernel thread; 最後從 trap return 回到新的 user-level process
xv6 為 scheduler 使用了獨立的 thread(各自擁有暫存器與 stack 的保存空間),因為讓 scheduler 在任意 process 的 kernel stack 上執行並不安全:其他 CPU 可能會在這段期間喚醒該 process 並開始執行,若兩個 CPU 共用同一個 stack,會造成災難性的後果。 為了處理多顆 CPU 同時執行、並有 process 要放棄 CPU 的情況,xv6 為每個 CPU 配置了獨立的 scheduler thread。 在這一節中,我們將會詳細探討 kernel thread 與 scheduler thread 之間切換的具體實作方式
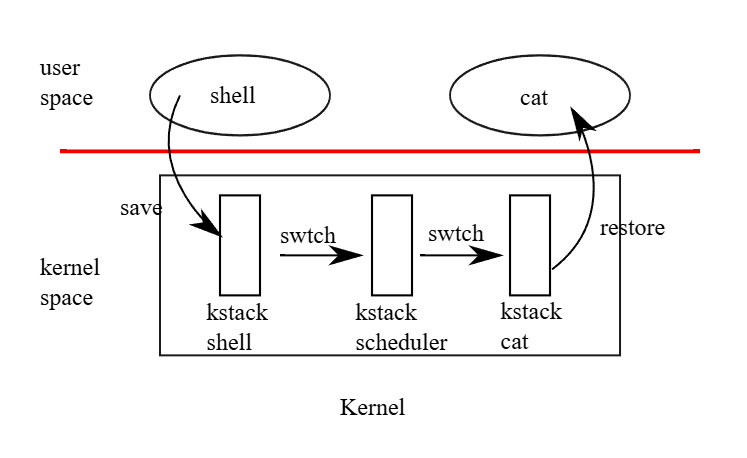
從一個 thread 切換到另一個 thread 的過程,需要將舊 thread 的 CPU 暫存器儲存下來,並還原新 thread 先前儲存的那些暫存器。 由於 stack pointer 和 program counter 都會被儲存與還原,這也表示 CPU 將會切換至新的 stack,並且執行新的程式碼
swtch 函式負責儲存與還原暫存器,實作 kernel thread 間的切換。 swtch 並不直接知道所謂的「thread」是什麼,它只負責儲存與還原一組 RISC-V 的暫存器,這組暫存器的集合被稱作「context」。 當某個 process 要放棄 CPU 時,它的 kernel thread 會呼叫 swtch,把自己的 context 儲存起來,並還原 scheduler 的 context
每個 context 都存在 struct context(kernel/proc.h:2)裡,這個結構會被放在某個 process 的 struct proc 或某個 CPU 的 struct cpu 中。 swtch 會接收 struct context *old 和 struct context *new 這兩個引數,並將目前的暫存器儲存到 old,從 new 中載入先前儲存的暫存器,然後 return
現在讓我們來追蹤一個 process 如何透過 swtch 切換進入 scheduler 的。 在第四章中我們看到,中斷的結束階段中有一種情況是 usertrap 呼叫 yield。 而 yield 接著會呼叫 sched,sched 再呼叫 swtch,把目前的 context 存到 p->context 中,並切換到先前儲存在 cpu->context 的 scheduler context(kernel/proc.c:506)
swtch(kernel/swtch.S:3)只會儲存 callee-saved 暫存器,而 caller-saved 暫存器則會由 C 編譯器在呼叫端負責儲存到 stack 上。 swtch 知道每個暫存器對應到 struct context 中的哪個成員,以及該成員的偏移量。 它不會儲存 program counter,而是儲存 ra 暫存器,這個暫存器中存放的是呼叫 swtch 那一行指令的 return address
接著,swtch 從新的 context 還原暫存器,這些值是先前某次 swtch 儲存的。 當 swtch 呼叫 ret 返回時,它會回到還原後的 ra 所指向的那行指令,也就是新 thread 先前呼叫 swtch 的那個位置。 同時,因為 sp 已被還原為新 thread 的 stack pointer,因此執行也會從新 thread 的 stack 上繼續
在我們這個例子中,sched 會呼叫 swtch,並切換到 cpu->context,也就是這顆 CPU 專屬的 scheduler context。 這份 context 是在先前某個時刻,由 scheduler 呼叫 swtch 並切換到現在這個 process 時所儲存的(kernel/proc.c:466)。 所以當我們目前追蹤的這次 swtch return 時,它實際上不是回到 sched,而是回到 scheduler,而且此時 stack pointer 已經是這顆 CPU 的 scheduler stack 了
Tips
根據 RISC-V Calling Conventions,暫存器口語上會分成兩類:
- caller-saved registers:呼叫者在呼叫 function 前要自己備份,包含
a0–a7,t0–t6,ra等 - callee-saved registers:被呼叫者(像
swtch)必須保存與還原,包含s0–s11,sp等
這可以在點進去一開始的表格中的「Preserved across calls?」欄位看到,為「Yes」的就是文中說的 callee-saved register。 而 ra 雖然不是 callee-saved register,但 swtch 為了做 context switch 所以有存
而 swtch 做的事基本上就是:
- 把被換出的 process 的 context 存到
struct context *old - 把換進來要執行的 process 的 context 用
struct context *new的內容復原 - 利用
ret回到new->ra處執行
而對於文中的例子,由於它是由 sched 去呼叫 swtch,所以 new 填的會是 &mycpu()->context,也就是一個 pre-CPU 的 scheduler context
7.3 Code: Scheduling
上一節我們探討了 swtch 的底層細節; 現在我們把來觀察 process 的 kernel thread 是如何透過 scheduler 切換到另一個 process 的。 scheduler 是每顆 CPU 上的一個特殊的 thread,這個 thread 執行的是 scheduler 函式。 這個函式會負責選出下一個要執行的 process。 當某個 process 想放棄 CPU 時,它必須先取得自己的 process lock p->lock,釋放它持有的其他 lock,更新自己的狀態(p->state),然後呼叫 sched。 你可以在 yield(kernel/proc.c:512)、sleep 和 exit 中看到這個流程
接著 sched 會再次確認這些條件是否已被滿足(kernel/proc.c:496-501),並檢查一個隱含的條件:既然有持有鎖,則必須確保中斷已被關閉。 最後,sched 呼叫 swtch,將當前的 context 存入 p->context,並切換到 cpu->context 中的 scheduler context。 swtch 返回時會回到 scheduler 的 stack,就好像當初 scheduler 呼叫的 swtch 返回了一樣(kernel/proc.c:466)。 然後 scheduler 繼續它的 for 迴圈,找下一個 process 來執行,再切換過去,如此反覆循環
Tips
scheduler()是每顆 CPU 的主控 loop,會尋找 runnable process,並執行它- 被執行的 process 如果想釋放 CPU(例如主動呼叫
yield、被sleep阻塞、或是exit),就會開始切換流程 - 這時
sched()函式會做兩件事:確認合法狀態、呼叫swtch並切回 scheduler
此處 swtch 不是隨便 return 的,而是會直接回到當初 scheduler() 呼叫 swtch() 的那一點,這依賴於之前 scheduler() 有正確地保存自己的 context
我們剛剛看到 xv6 在呼叫 swtch 的整個過程中會持續持有 p->lock:呼叫 swtch 的程式碼必須事先持有這把 lock,並且這把 lock 的控制權會一併傳給被切換過去的程式碼。 這樣的安排並不常見:更常見的做法是持有鎖的一方同時負責釋放它。 但 xv6 不能這樣做,因為 p->lock 保護了 p->state 與 p->context 欄位的狀態不變性,而這些不變性在執行 swtch 的時候會被暫時破壞掉
例如,如果在執行 swtch 期間沒有持有 p->lock,那麼另一顆 CPU 可能會在 yield 將 process 狀態設為 RUNNABLE 之後、但 swtch 還沒釋出 stack 之前,就搶先執行這個 process,導致兩個 CPU 同時在用同一個 stack,造成災難
因此,一旦 yield 開始修改 process 的狀態,使它變成 RUNNABLE,那就必須持續持有 p->lock,直到系統恢復狀態一致為止:最早能釋放 lock 的時間點是在 scheduler(它使用自己的 stack 執行)清除 c->proc 之後。 反過來說,當 scheduler 開始把某個 RUNNABLE process 轉換成 RUNNING 時,也不能在 swtch 之前釋放 lock,而是要等到 process 的 kernel thread 真正開始執行(例如在 yield 裡)之後才行
kernel thread 唯一會放棄 CPU 的地方是在 sched,而它總會切換回 scheduler 中的同一段位置,然後 scheduler 幾乎又總會切換到某個先前呼叫過 sched 的 kernel thread。 因此,如果你列印出 xv6 切換執行緒所在的行號,你會看到一個很簡單的模式:466、506、466、506,這樣反覆。 這種透過 thread switch 有意地把控制權交給彼此的程式,有時被稱作 coroutines; 在這個例子中,sched 和 scheduler 就是彼此的 coroutine
Tips
假設 CPU 0 上的 process A 呼叫了 yeild 放棄 CPU,此時在 yeild 內會將 p->lock 上鎖,將 p->state 改成 RUNNABLE,然後呼叫 sched:
// Give up the CPU for one scheduling round.
void
yield(void)
{
struct proc *p = myproc();
acquire(&p->lock);
p->state = RUNNABLE;
sched();
release(&p->lock);
}接著 sched 會呼叫 swtch:
// Switch to scheduler. Must hold only p->lock
// and have changed proc->state. Saves and restores
// intena because intena is a property of this
// kernel thread, not this CPU. It should
// be proc->intena and proc->noff, but that would
// break in the few places where a lock is held but
// there's no process.
void
sched(void)
{
int intena;
struct proc *p = myproc();
if(!holding(&p->lock))
panic("sched p->lock");
if(mycpu()->noff != 1)
panic("sched locks");
if(p->state == RUNNING)
panic("sched RUNNING");
if(intr_get())
panic("sched interruptible");
intena = mycpu()->intena;
swtch(&p->context, &mycpu()->context);
mycpu()->intena = intena;
}而如前面所述,swtch 本身只做 context 的儲存與還原,然後 return,這裡 ret 會回到 scheduler context:
swtch:
sd ra, 0(a0)
sd sp, 8(a0)
sd s0, 16(a0)
sd s1, 24(a0)
sd s2, 32(a0)
sd s3, 40(a0)
sd s4, 48(a0)
sd s5, 56(a0)
sd s6, 64(a0)
sd s7, 72(a0)
sd s8, 80(a0)
sd s9, 88(a0)
sd s10, 96(a0)
sd s11, 104(a0)
ld ra, 0(a1)
ld sp, 8(a1)
ld s0, 16(a1)
ld s1, 24(a1)
ld s2, 32(a1)
ld s3, 40(a1)
ld s4, 48(a1)
ld s5, 56(a1)
ld s6, 64(a1)
ld s7, 72(a1)
ld s8, 80(a1)
ld s9, 88(a1)
ld s10, 96(a1)
ld s11, 104(a1)
ret但在執行 swtch 的期間,context 還沒搬完,到目前整個流程都還跟一般的 function call 一樣,所以 CPU 0 還處在 process A 的 stack 上。 此時如果 CPU 1 正在執行 scheduler,看到 process A 的 p->state 為 RUNNABLE,就有可能嘗試呼叫 acquire(p->lock) 並把它抓進去執行,成功的話兩個 CPU 就會同時執行 process A 且共用了它的 stack,因此才要上鎖,讓 acquire(p->lock) 失敗
下面為 scheduler 的實作:
// Per-CPU process scheduler.
// Each CPU calls scheduler() after setting itself up.
// Scheduler never returns. It loops, doing:
// - choose a process to run.
// - swtch to start running that process.
// - eventually that process transfers control
// via swtch back to the scheduler.
void
scheduler(void)
{
struct proc *p;
struct cpu *c = mycpu();
c->proc = 0;
for(;;){
// The most recent process to run may have had interrupts
// turned off; enable them to avoid a deadlock if all
// processes are waiting. Then turn them back off
// to avoid a possible race between an interrupt
// and wfi.
intr_on();
intr_off();
int found = 0;
for(p = proc; p < &proc[NPROC]; p++) {
acquire(&p->lock);
if(p->state == RUNNABLE) {
// Switch to chosen process. It is the process's job
// to release its lock and then reacquire it
// before jumping back to us.
p->state = RUNNING;
c->proc = p;
swtch(&c->context, &p->context);
// Process is done running for now.
// It should have changed its p->state before coming back.
c->proc = 0;
found = 1;
}
release(&p->lock);
}
if(found == 0) {
// nothing to run; stop running on this core until an interrupt.
asm volatile("wfi");
}
}
}可以看到在內層的 for loop 中會先呼叫 acquire,然後才會確認 p->state 是不是 RUNNABLE 的。 這邊雖然會依序對 process array 中的每個 process 做 acquire,但這其實並沒有關係,不會有卡住的問題,因為大部分的時候 p->lock 是空閒的,process 在 user space 跑的時候不會上鎖,只有在向上面 swtch 這種期間才會持鎖
再來你會看到 yield 裡面在 sched 之後還呼叫了 release(&p->lock),而其對應的 sched 內,在 swtch(&p->context, &mycpu()->context) 之後做了 mycpu()->intena = intena; 這件事
這是因為當 process A 被換出 CPU 0 時,其儲存的位置是在 swtch(&p->context, &mycpu()->context) 這行,因此之後 process A 被換回來的時候,它會依序再由原路徑返回,下面是一個示意用的流程(我畫好久):
Process A
├─ ...
└─ yield()
├─ acquire(A.lock) ← A 上鎖
├─ A.state = RUNNABLE
└─ sched()
└─ swtch(&p->context, &cpu->scheduler) ← 鎖仍在 A 手上
└─► 進入 scheduler() (CPU 專屬 stack)
├─ c->proc = 0;
├─ found = 1;
├─ release(A.lock) ← 第一次釋放 A 的鎖
├─ for 迴圈掃表,找到 Process B
├─ acquire(B.lock)
├─ B.state = RUNNING
└─ swtch(&cpu->scheduler, &B.context)
└─► 進入 Process B(執行一段時間…)
… B 透過 yield()/sleep() 等放棄 CPU …
◄─ 回到 scheduler()
├─ c->proc = 0
├─ found = 1;
├─ release(B.lock)
├─ 找到 Process A (再次 acquire(A.lock)) ← A 再度上鎖
├─ p->state = RUNNING
└─ swtch(&cpu->scheduler, &p->context)
└─► 回到 Process A 的 sched()
◄─ 回到 sched() (A 的 kernel stack)
├─ mycpu()->intena = intena
└─ return 回到 yield()
◄─ yield() 尾端
└─ release(A.lock) ← 第二次釋放 A 的鎖有一種情況下,scheduler 呼叫 swtch 後不會進入 sched。 allocproc 會把新 process 的 context 中的 ra 設為 forkret(kernel/proc.c:524),這樣這個 process 第一次被切入時,swtch 就會「return」到那個函式的開頭。 forkret 的存在是為了釋放 p->lock; 否則,因為這個新 process 需要回到 user space(就像從 fork return 一樣),它本來可以直接從 usertrapret 開始執行
Tips
這是 fork 新 process 的特殊處理:
- 新 process 還沒有執行過,所以它沒有先前的
swtchreturn 點 allocproc人為設一個context.ra = forkret,讓第一次執行時swtch能跳進去forkret的任務是先完成 kernel 端的收尾(例如釋放鎖),然後才進入usertrapret,跳回 user space
這樣做可讓新建 process 也能使用與其他 process 相同的切換邏輯
scheduler(kernel/proc.c:445)會跑一個無限迴圈:找出一個可執行的 process,執行它直到它釋放 CPU,再重複這個流程。 scheduler 會遍歷整個 process table,尋找狀態為 RUNNABLE 的 process。 一旦找到,它會設置這顆 CPU 的 c->proc 指標,將該 process 的狀態設為 RUNNING,然後呼叫 swtch 開始執行它(kernel/proc.c:461-466)
7.4 Code: mycpu and myproc
xv6 經常需要取得目前正在執行的 process 所對應的 proc 結構的指標。 在單核系統中,可以使用一個全域變數來指向當前的 proc。 但這在多核機器上就行不通了,因為每個 CPU 都可能在執行不同的 process。 我們可以透過「每顆 CPU 都擁有自己獨立的一組暫存器」這件事來解決這個問題
當某顆 CPU 正在執行 kernel code 時,xv6 保證這顆 CPU 的 tp 暫存器會儲存它的 hartid。 RISC-V 為每顆 CPU 指派了一個唯一的 hartid。 mycpu 函式(kernel/proc.c:74)會使用 tp 來索引 struct cpu 的陣列,並回傳指向目前這顆 CPU 的 struct cpu 的指標。 struct cpu(kernel/proc.h:22)中包含了一個指向當前正在這顆 CPU 上執行的 struct proc 的指標(若有的話)、這顆 CPU 所對應的 scheduler thread 的暫存器快照、以及用來管理中斷關閉的 spinlock 巢狀層數
要讓每顆 CPU 的 tp 保持對應的 hartid,其實需要一點額外處理,因為使用者程式是可以隨意修改 tp 的。 start 函式會在 CPU 的開機過程早期、仍處於 machine mode 時設置 tp(kernel/start.c:45)。 usertrapret 會把 tp 儲存在 trampoline page 中,以防使用者程式改動了它。 最後,uservec 在從 user space 進入 kernel 時會還原之前儲存的 tp(kernel/trampoline.S:78)。 編譯器保證在 kernel code 中永遠不會去修改 tp。 如果 xv6 可以直接向 RISC-V 硬體查詢目前的 hartid 會更方便,但 RISC-V 規範中只有 machine mode 才能這麼做,supervisor mode 不行
cpuid 和 mycpu 的回傳值比較脆弱(fragile),如果在這之後發生 timer 中斷,導致目前這條 thread 放棄 CPU,然後稍後被排到另一顆 CPU 上執行,那麼原先回傳的值就會失效。 為了避免這個問題,xv6 要求呼叫這些函式的程式碼在使用期間必須先關閉中斷,等到使用完畢後再重新開啟
函式 myproc(kernel/proc.c:83)會回傳目前正在當前 CPU 上執行的 process 的 struct proc 指標。 myproc 在執行過程中會先關閉中斷,接著呼叫 mycpu,從 struct cpu 中取得目前的 c->proc,最後再重新開啟中斷。 myproc 的回傳值在中斷開啟的情況下也可以安全使用:即使 timer 中斷將目前的 process 移動到另一顆 CPU,指向這個 process 的 struct proc 指標仍然是同一個
7.5 Sleep and wakeup
排程與鎖有助於把一個執行緒的行為對其他執行緒隱藏起來,但我們也需要一些抽象工具來讓執行緒之間可以有意識地互動。 舉例來說,xv6 中 pipe 的讀取端可能需要等待寫入端產生資料; 父 process 呼叫 wait 時可能要等子 process 結束; 而一個讀硬碟的 process 則需要等待硬碟裝置完成資料讀取
xv6 kernel 在這些(以及其他許多)情境中會使用名為 sleep 與 wakeup 的機制。 sleep 讓 kernel 執行緒可以等待特定事件; 而另一個執行緒則可以呼叫 wakeup 來通知等待某個事件的執行緒可以繼續執行了。 sleep 和 wakeup 常被稱為「順序協調(sequence coordination)」或「條件同步(conditional synchronization)」機制
sleep 和 wakeup 提供的是一種相對底層的同步介面。 為了說明它們在 xv6 中的運作方式,我們將使用它們來構建一個較高層級的同步機制,稱為 semaphore(但 xv6 並未實際使用 semaphore)。 一個 semaphore 會維護一個計數器,並提供兩種操作:V 操作(由生產者使用)會將計數器加一; P 操作(由消費者使用)會等計數器變為非零值,然後將其減一並返回。 假設只有一個生產者執行緒與一個消費者執行緒,其分別在不同的 CPU 上執行,並且編譯器沒有做過度最佳化,那麼以下的實作將是正確的:
struct semaphore {
struct spinlock lock;
int count;
};
void
V(struct semaphore *s)
{
acquire(&s->lock);
s->count += 1;
release(&s->lock);
}
void
P(struct semaphore *s)
{
while(s->count == 0)
;
acquire(&s->lock);
s->count -= 1;
release(&s->lock);
}但上述的實作非常低效。 若生產者很少會被執行,消費者就會把大部分的時間花在 while 迴圈中自旋,等待 count 變成非零值。 消費者所佔用的 CPU 應該可以用來做更有生產力的事,而不是透過不斷輪詢 s->count 來忙等。 若要避免這種忙等,我們就需要讓消費者能夠讓出 CPU,等到 V 把 count 加一後才再回來繼續執行
儘管這樣還不夠完善,但這正是往前的第一步。 設想有一對名為 sleep 和 wakeup 的函式,其行為如下:sleep(chan) 會等待一個由 chan 的值所指定的事件,這個值被稱為「等待通道(wait channel)」。 sleep 會讓呼叫它的 process 進入睡眠狀態,並釋放 CPU 讓其他工作可以執行。 wakeup(chan) 則會喚醒所有正在對相同 chan 呼叫 sleep 的 process(如果有的話),讓那些 sleep 函式返回。 如果沒有 process 正在等待該 chan,則 wakeup 不會有任何效果
現在我們可以利用 sleep 與 wakeup 來修改 semaphore 的實作:
void
V(struct semaphore *s)
{
acquire(&s->lock);
s->count += 1;
wakeup(s); // added line
release(&s->lock);
}
void
P(struct semaphore *s)
{
while(s->count == 0)
sleep(s); // added line
acquire(&s->lock);
s->count -= 1;
release(&s->lock);
}現在 P 不再自旋了,其會讓出 CPU,這是個好改進。 不過要用這種介面正確實作 sleep 和 wakeup 並不容易,因為我們會遇到一種稱為「喚醒遺失(lost wake-up)」的問題。 假設 P 在 while(s->count == 0) 處發現 s->count == 0,但就在 P 執行完第 13 行,準備執行第 14 行時,V 在另一個 CPU 上被執行了,此時 V 將 s->count 改為了非零值,並呼叫了 wakeup,但此時尚未有任何 process 在睡眠中,因此 wakeup 就沒有做任何事
接著 P 繼續執行到第 14 行,呼叫了 sleep 並進入了睡眠狀態。 這就造成了一個問題:P 此時正在等待一個已經由 V 發完的 wakeup 呼叫。 除非我們運氣很好,生產者再次呼叫了 V,否則消費者將會被永遠卡住,即使 count 已經是非零值了
這個問題的根源在於,一個重要的不變式被破壞了:P 只會在 s->count == 0 的時候才去 sleep。 但這個不變式在 V 剛好於錯誤時機執行時會被破壞。 有一種錯誤的解法,是試圖透過把 P 裡面取得 lock 的動作往前移,讓 count 的檢查與呼叫 sleep 的過程變成原子操作:
void
V(struct semaphore *s)
{
acquire(&s->lock);
s->count += 1;
wakeup(s);
release(&s->lock);
}
void
P(struct semaphore *s)
{
acquire(&s->lock); // <--- 錯誤方式
while(s->count == 0)
sleep(s);
s->count -= 1;
release(&s->lock);
}我們希望這個版本的 P 能避免 lost wakeup,因為 lock 阻止了 V 在 while(s->count == 0) 與 sleep(s) 之間插入執行。 它確實做到了這點,但也同時導致了死鎖:P 在進入 sleep 時仍持有 lock,導致 V 永遠無法取得 lock 而被卡住
我們將透過改變 sleep 的介面來修正先前的設計問題:呼叫者必須將「條件鎖(condition lock)」傳遞給 sleep,讓 sleep 可以在呼叫者被標記為睡眠,並在指定的 sleep channel 等待後釋放該鎖。 這把鎖會強制讓同時執行的 V 延後執行,直到 P 完成進入睡眠,這樣 wakeup 才能正確找到處於睡眠狀態的消費者並喚醒它。 一旦消費者再次被喚醒,sleep 會在返回前重新取得這把鎖。 經過這種修正後的 sleep/wakeup 機制可以如下列方式使用:
void
V(struct semaphore *s)
{
acquire(&s->lock);
s->count += 1;
wakeup(s);
release(&s->lock);
}
void
P(struct semaphore *s)
{
acquire(&s->lock);
while(s->count == 0)
sleep(s, &s->lock); // <--- 改版後的 sleep 會接受一個 lock 引數
s->count -= 1;
release(&s->lock);
}P 在進入 sleep 前就已經持有了 s->lock,這使得 V 無法在 P 檢查 s->count 和呼叫 sleep 之間插入並嘗試喚醒 P。 然而,sleep 仍必須以「對 wakeup 來說是原子的方式」,同時釋放 s->lock 並讓消費者 process 進入睡眠狀態,這樣才能避免 lost wakeup 的問題
7.6 Code: Sleep and wakeup
xv6 的 sleep(kernel/proc.c:548)與 wakeup(kernel/proc.c:579)實作了前面範例中所提到的介面。 基本的做法是:sleep 會將目前的 process 標記為 SLEEPING,然後呼叫 sched 來釋放 CPU; 而 wakeup 則會找出正在某個 wait channel 上睡眠的 process,並將其標記為 RUNNABLE。 sleep 和 wakeup 的呼叫者可以任意使用一個雙方同意的數值作為 channel。 xv6 通常會用 kernel 相關的資料結構的位址來當作這個 channel
// Sleep on wait channel chan, releasing condition lock lk.
// Re-acquires lk when awakened.
void
sleep(void *chan, struct spinlock *lk)
{
struct proc *p = myproc();
// Must acquire p->lock in order to
// change p->state and then call sched.
// Once we hold p->lock, we can be
// guaranteed that we won't miss any wakeup
// (wakeup locks p->lock),
// so it's okay to release lk.
acquire(&p->lock); //DOC: sleeplock1
release(lk);
// Go to sleep.
p->chan = chan;
p->state = SLEEPING;
sched();
// Tidy up.
p->chan = 0;
// Reacquire original lock.
release(&p->lock);
acquire(lk);
}
// Wake up all processes sleeping on wait channel chan.
// Caller should hold the condition lock.
void
wakeup(void *chan)
{
struct proc *p;
for(p = proc; p < &proc[NPROC]; p++) {
if(p != myproc()){
acquire(&p->lock);
if(p->state == SLEEPING && p->chan == chan) {
p->state = RUNNABLE;
}
release(&p->lock);
}
}
}sleep 會先取得 p->lock(kernel/proc.c:559),之後才釋放 lk。 sleep 之所以會一直持有其中一把鎖,是為了防止同時執行的 wakeup(它必須同時取得兩把鎖)在錯誤的時間介入。 此時 sleep 已持有 p->lock,因此可以透過紀錄 sleep channel、將 process 狀態設為 SLEEPING,再呼叫 sched(kernel/proc.c:563-566)來讓 process 進入睡眠。 稍後我們會看到,為何一定要等到 process 被標記為 SLEEPING 後,p->lock 才能被 scheduler 釋放
之後的某個時間點,某個 process 會取得條件鎖、設置條件(也就是喚醒的前提),然後呼叫 wakeup(chan)。 這裡的重點是:wakeup 呼叫時要持有這把條件鎖(嚴格來說,只要 wakeup 緊跟在 acquire 之後就夠了,也就是說可以在 release 之後呼叫 wakeup)。 wakeup 會遍歷整張 process table(kernel/proc.c:579),並對每個被檢查的 process 取得其 p->lock。 如果 wakeup 發現某個 process 處於 SLEEPING 狀態,且它的 chan 與傳進來的參數相符,就會將其狀態改為 RUNNABLE。 接下來當 scheduler 執行時,就會注意到這個 process 已經可以被執行了
sleep 和 wakeup 的鎖定規則能保證一個 process 在進入睡眠時,不會錯過同時發生的 wakeup。 這是因為要進入睡眠的 process,會在檢查條件前就會持有條件鎖與 p->lock,或兩者的其中一個,直到被標記為 SLEEPING 之後才會釋放它們。 而呼叫 wakeup 的 process 在其迴圈中會同時持有這兩把鎖。 因此,喚醒者要麼會在消費者檢查條件之前就改變條件,要麼會在消費者已經標為 SLEEPING 後再執行 wakeup,這樣就能看到睡眠中的 process 並成功喚醒它了(除非有其他事情先喚醒它)
Tips
直到被標記為
SLEEPING之後才會釋放它們
這裡是指 p->lock 在回到 scheduler context 時會由 scheduler 釋放(release(&p->lock))
有時會有多個 process 同時在同一個 channel 上睡眠,例如多個 process 同時對一個 pipe 進行讀取,則只需一個 wakeup 就會把它們全部喚醒。 當中有一個 process 會先被執行,並成功取得 sleep 時用的鎖,在 pipe 的情況下,它會讀走等待中的資料。 其他 process 雖然也被喚醒,卻會發現沒有資料可讀。 從它們的角度來看,這次喚醒是「虛假的(spurious)」,它們必須再次進入睡眠。 也因此,sleep 一定會包在一個會檢查條件的迴圈中
即使兩個 sleep/wakeup 使用者不小心選了相同的 channel,也不會造成什麼問題:它們可能會遇到 spurious wakeup 的問題,但只要照上面所說的方式加上迴圈,就可以容忍這種情況。 sleep/wakeup 的設計魅力之一,就在於它既輕量(不需要額外建立用來表示 sleep channel 的特殊資料結構),又提供了一層間接性(呼叫者不需要知道自己在跟哪個特定的 process 互動)
7.7 Code: Pipes
xv6 中對 pipe 的實作是一個以 sleep 和 wakeup 同步 producer 與 consumer 的更複雜的例子。 我們在第一章中看過 pipe 的介面:寫入 pipe 一端的 byte 會被複製進 kernel 內部的 buffer 中,之後可以從另一端讀出。 後面的章節會探討圍繞 pipe 的 file descriptor 支援,但我們現在先來看 pipewrite 與 piperead 的實作
每個 pipe 都用一個 struct pipe 來表示,其中包含一個 lock 和一個 data buffer。 nread 與 nwrite 這兩個欄位分別記錄從 buffer 中讀出的總 byte 數與寫入的總 byte 數。 這個 buffer 是環狀的:在寫入到 buf[PIPESIZE-1] 之後,下一個 byte 會被寫入到 buf[0]。 但計數器 nread 和 nwrite 並不會像這樣回繞
這種設計讓實作可以簡單地區分 buffer 已滿(nwrite == nread + PIPESIZE)與 buffer 為空(nwrite == nread)的狀態,但也意味著對 buffer 的存取必須使用 buf[nread % PIPESIZE],不能直接用 buf[nread](對 nwrite 也是如此)
假設此時有兩個不同 CPU 同時分別呼叫 piperead 與 pipewrite。 pipewrite(kernel/pipe.c:77)會先取得 pipe 的鎖,這把鎖保護的是計數器、資料與相關的不變性。 此時 piperead(kernel/pipe.c:106)也會嘗試取得這把鎖,但這會失敗,因此它會卡在 acquire 中(kernel/spinlock.c:22)自旋等待鎖釋放
int
pipewrite(struct pipe *pi, uint64 addr, int n)
{
int i = 0;
struct proc *pr = myproc();
acquire(&pi->lock);
while(i < n){
if(pi->readopen == 0 || killed(pr)){
release(&pi->lock);
return -1;
}
if(pi->nwrite == pi->nread + PIPESIZE){ //DOC: pipewrite-full
wakeup(&pi->nread);
sleep(&pi->nwrite, &pi->lock);
} else {
char ch;
if(copyin(pr->pagetable, &ch, addr + i, 1) == -1)
break;
pi->data[pi->nwrite++ % PIPESIZE] = ch;
i++;
}
}
wakeup(&pi->nread);
release(&pi->lock);
return i;
}
int
piperead(struct pipe *pi, uint64 addr, int n)
{
int i;
struct proc *pr = myproc();
char ch;
acquire(&pi->lock);
while(pi->nread == pi->nwrite && pi->writeopen){ //DOC: pipe-empty
if(killed(pr)){
release(&pi->lock);
return -1;
}
sleep(&pi->nread, &pi->lock); //DOC: piperead-sleep
}
for(i = 0; i < n; i++){ //DOC: piperead-copy
if(pi->nread == pi->nwrite)
break;
ch = pi->data[pi->nread++ % PIPESIZE];
if(copyout(pr->pagetable, addr + i, &ch, 1) == -1)
break;
}
wakeup(&pi->nwrite); //DOC: piperead-wakeup
release(&pi->lock);
return i;
}當 piperead 還在等待時,pipewrite 會在迴圈中逐一將 addr[0..n-1] 的資料寫進 pipe(kernel/pipe.c:95)。 在這個過程中,可能會遇到 buffer 被填滿的情況(kernel/pipe.c:88),此時 pipewrite 會呼叫 wakeup 去通知任何正在等待的 reader,表示 buffer 裡有資料可讀,然後自己對 &pi->nwrite 呼叫 sleep,等待某個 reader 從 buffer 中拿走一些 byte。 這個 sleep 在讓 pipewrite 的 process 進入睡眠狀態的會同時釋放 pipe 的 lock
此時 piperead 取得了 pipe 的 lock 並進入 critical section:它發現 pi->nread != pi->nwrite(kernel/pipe.c:113)(這代表之前 pipewrite 是因為 pi->nwrite == pi->nread + PIPESIZE 而進入 sleep 的,見 kernel/pipe.c:88),所以接著進入 for 迴圈,從 pipe 中複製資料出去(kernel/pipe.c:120),並根據複製的 byte 數增加 nread。 此時這些空出來的 byte 就又可供寫入了,因此 piperead 會呼叫 wakeup(kernel/pipe.c:127)喚醒可能在等待的 writer。 wakeup 會找到那個在 &pi->nwrite 上睡眠的 process,也就是之前因為 buffer 滿了而進入 sleep 的 pipewrite process,並將該 process 標記為 RUNNABLE
pipe 的程式碼為 reader 和 writer 使用了不同的 sleep channel(分別為 pi->nread 與 pi->nwrite); 這麼做可能會讓系統在有大量 reader 和 writer 同時等待同一條 pipe 的情況下更有效率。 pipe 的 sleep 都寫在一個會檢查條件的迴圈中; 如果有多個 reader 或 writer,其中第一個醒來的 process 會發現條件滿足,而其他人會因為條件還不成立再次進入 sleep
7.8 Code: Wait, exit, and kill
sleep 和 wakeup 可以用在許多種類的等待情境中。 一個有趣的例子是在第一章中介紹的:child 的 exit 和 parent 的 wait 之間的互動。 在 child 終止時,parent 可能已經因 wait 而處於睡眠中,或是正在執行其他事情; 如果是後者,即使已經距離 exit 呼叫過了一段時間,之後呼叫 wait 時也必須能夠觀察到 child 的死亡
xv6 採用的做法是讓 exit 將呼叫者的狀態設為 ZOMBIE,child 會保持在該狀態,直到 parent 呼叫 wait 並察覺到它,接著將 child 的狀態改成 UNUSED,複製其退出狀態,並將其 process ID 回傳給 parent。 如果 parent 在 child 之前先結束了,那麼 parent 會把 child 移交給 init process,其會永久地呼叫 wait; 因此每個 child 都會有一個負責清理它的 parent。 實作上的挑戰在於如何避免 parent 和 child 同時呼叫 wait 或 exit,或兩個 process 同時呼叫 exit 時產生 race condition 或 deadlock
// Exit the current process. Does not return.
// An exited process remains in the zombie state
// until its parent calls wait().
void
exit(int status)
{
struct proc *p = myproc();
if(p == initproc)
panic("init exiting");
// Close all open files.
for(int fd = 0; fd < NOFILE; fd++){
if(p->ofile[fd]){
struct file *f = p->ofile[fd];
fileclose(f);
p->ofile[fd] = 0;
}
}
begin_op();
iput(p->cwd);
end_op();
p->cwd = 0;
acquire(&wait_lock);
// Give any children to init.
reparent(p);
// Parent might be sleeping in wait().
wakeup(p->parent);
acquire(&p->lock);
p->xstate = status;
p->state = ZOMBIE;
release(&wait_lock);
// Jump into the scheduler, never to return.
sched();
panic("zombie exit");
}wait 會先取得 wait_lock(kernel/proc.c:391),這把鎖扮演著條件鎖的角色,用來確保 wait 不會錯過 child exit 所發出的 wakeup。 接著 wait 會掃描整張 process table,如果找到一個狀態為 ZOMBIE 的 child,它會釋放該 child 的資源和其 proc 結構,並將其 exit status 複製到 wait 所提供的指標中(如果該指標不是 0),然後回傳該 child 的 process ID
如果 wait 找到一些 child,但都還沒 exit,它就會呼叫 sleep 來等待其中任何一個結束(kernel/proc.c:433),然後再次掃描。 wait 經常同時持有兩把鎖:wait_lock 和某個 child 的 pp->lock。 為了避免 deadlock,持鎖的順序必須是先取 wait_lock 再取 pp->lock
// Wait for a child process to exit and return its pid.
// Return -1 if this process has no children.
int
wait(uint64 addr)
{
struct proc *pp;
int havekids, pid;
struct proc *p = myproc();
acquire(&wait_lock);
for(;;){
// Scan through table looking for exited children.
havekids = 0;
for(pp = proc; pp < &proc[NPROC]; pp++){
if(pp->parent == p){
// make sure the child isn't still in exit() or swtch().
acquire(&pp->lock);
havekids = 1;
if(pp->state == ZOMBIE){
// Found one.
pid = pp->pid;
if(addr != 0 && copyout(p->pagetable, addr, (char *)&pp->xstate,
sizeof(pp->xstate)) < 0) {
release(&pp->lock);
release(&wait_lock);
return -1;
}
freeproc(pp);
release(&pp->lock);
release(&wait_lock);
return pid;
}
release(&pp->lock);
}
}
// No point waiting if we don't have any children.
if(!havekids || killed(p)){
release(&wait_lock);
return -1;
}
// Wait for a child to exit.
sleep(p, &wait_lock); //DOC: wait-sleep
}
}exit(kernel/proc.c:347)會記錄退出狀態、釋放部分資源、呼叫 reparent 將自己的 child 移交給 init process、喚醒可能正在 wait 的 parent、將自己標記為 zombie,並永久讓出 CPU。 exit 在這段過程中會同時持有 wait_lock 和 p->lock。 持有 wait_lock 是為了確保喚醒 parent(wakeup(p->parent))時不會遺失 wakeup(因為這是條件鎖)。 它也必須持有 p->lock,以避免在 child 尚未完成 swtch 之前,parent 在 wait 中看到 child 處於 ZOMBIE 狀態。 exit 持鎖的順序與 wait 相同,以避免 deadlock
exit 在將自己的狀態設為 ZOMBIE 之前就喚醒 parent,看起來好像不太正確,但這其實是安全的:雖然 wakeup 可能會讓 parent 被排程執行,但 wait 中的迴圈在 child 的 p->lock 被 scheduler 釋放之前,無法存取該 child,因此 wait 不會太早看到該 process,直到 exit 把狀態設為 ZOMBIE 為止(kernel/proc.c:379)
exit 允許一個 process 終止自己,而 kill(kernel/proc.c:598)則允許某個 process 請求終止另一個 process。 讓 kill 直接銷毀目標 process 會太過複雜,因為該目標可能正在另一個 CPU 上執行,甚至可能正處於對 kernel 資料結構進行敏感更新的途中。 因此 kill 所做的事情非常簡單:它只會設置目標 process 的 p->killed,如果該 process 正在睡眠狀態,也會喚醒它
最終這個被 kill 的 process 會進入或離開 kernel,而在那個時間點,usertrap 中的程式碼會檢查 p->killed 是否有被設置(它透過呼叫 killed 來檢查,見 kernel/proc.c:627),如果有被設置就呼叫 exit。 如果該 process 當時正執行在 user space,它很快就會因為系統呼叫或 timer(或其他裝置)的中斷而進入 kernel
Tips
kill 並不會馬上讓目標 process 終止,因為 process 可能正在 user space 執行,甚至可能正在別的 CPU 上處理一些尚未完成的 kernel 操作。 為了避免 race condition 或破壞 kernel 的一致性,xv6 的做法是設一個 p->killed flag,然後等待目標 process 自己進入 kernel(可能是被中斷打斷或做系統呼叫),再由 usertrap 判斷是否要執行 exit。 使用的是延遲中止的設計
如果目標 process 此時正在 sleep,那麼 kill 呼叫 wakeup 就會讓它從 sleep 返回。 這其實是有潛在風險的,因為原本等待的條件可能仍然不成立。 不過,在 xv6 裡,所有對 sleep 的呼叫都包在一個 while 迴圈中,sleep 返回之後會重新檢查條件。 有些 sleep 的呼叫還會在迴圈中檢查 p->killed,如果發現它被設置了,就會放棄目前的行為。 這只有在放棄當前操作是合理的情況下才會這樣做,例如 pipe 的讀寫程式碼(kernel/pipe.c:84)就會在 killed 被設置時直接返回; 之後程式流程會回到 trap,那裡會再一次檢查 p->killed,然後執行 exit
有些 xv6 中的 sleep 迴圈並不會檢查 p->killed,因為這些程式碼正處於一個原子性的 multi-step system call 中。 virtio driver 就是一個例子(kernel/virtio_disk.c:285):它不會檢查 p->killed,因為單個 disk 操作可能是數個寫入中的其中一部分,而這些寫入全部完成後,檔案系統的狀態才會是正確的。 如果一個 process 在等待 disk I/O 的期間被 kill,它仍然會完成目前的系統呼叫,等回到 usertrap 時才會檢查 killed flag 並結束
7.9 Process Locking
每個 process 所對應的 lock(p->lock)是 xv6 中最複雜的 lock。 要理解 p->lock,一個簡單的方式是:只要要讀取或寫入下列 struct proc 欄位時,就必須持有這把 lock:p->state、p->chan、p->killed、p->xstate,以及 p->pid。 這些欄位可能會被其他 process 或其他 CPU 上的 scheduler 執行緒存取,因此需要用 lock 來保護
然而,p->lock 的大多數用途其實是在保護 xv6 中 process 資料結構與演算法的更高層次面向。 以下列出 p->lock 所負責的全部事項:
- 與
p->state一起,它可以防止在配置proc[]中的新 process slot 時發生競爭條件proc[]是全系統的 process 表,而創建新 process 時需要找一個UNUSEDslot。 若沒有鎖,可能兩個 CPU 同時選中一個 slot。 持有p->lock可讓檢查state == UNUSED和後續設置變成原子操作
- 在 process 被建立或銷毀的過程中,它能讓該 process 對外「不可見」
- 一個 process 尚未完成初始化,或還沒清除完記憶體前,不應被其他人查詢或操作。 持有
p->lock可避免其他人看到尚未準備好或已經部分銷毀的 process 狀態
- 一個 process 尚未完成初始化,或還沒清除完記憶體前,不應被其他人查詢或操作。 持有
- 它可以防止 parent 的
wait在 child 將狀態設為ZOMBIE但還沒釋出 CPU 前,就過早回收該 process - 它可以防止其他 CPU 的 scheduler 在一個 process 將狀態設成
RUNNABLE但尚未完成swtch前,就決定要執行它- 從
RUNNING切換出去時狀態會被改為RUNNABLE,但此時還沒完成 context switch。 如果其他 scheduler 此時看到RUNNABLE而選它,會產生不一致
- 從
- 它能保證只有一個 CPU 的 scheduler 決定要執行某個
RUNNABLE的 process- 防止兩個 scheduler 同時選中同一個 process
- 它防止 timer interrupt 在 process 正在
swtch時讓它再次yield- 如果在切換 context 的過程中又被中斷,可能會造成 process 被不當地 preempt。 這段說明
p->lock是讓swtch對 timer interrupt 保持原子性的手段之一
- 如果在切換 context 的過程中又被中斷,可能會造成 process 被不當地 preempt。 這段說明
- 配合條件變數所用的 lock,它可以防止
wakeup漏掉正在呼叫sleep但還沒完成yield的 process - 它防止在
kill檢查p->pid與設置p->killed之間,該目標 process 就已經 exit 並被重複使用pid是唯一識別 process 的 ID,但proc[]slot 是會被重用的。 如果在kill檢查pid後、設置killed前,該 slot 被別的 process 佔用了,可能會 kill 錯人
- 它讓
kill對p->state的讀寫成為一個原子操作- 不只是
pid,對state的操作也要是安全的。 否則kill可能對一個不該 kill 的狀態進行操作
- 不只是
p->parent 欄位則由全域的 wait_lock 保護,而不是由 p->lock 保護。 只有 process 的 parent 會修改 p->parent,但該欄位也會被這個 process 本身以及其他想找它子 process 的 process 所讀取。 wait_lock 的用途是當 wait 呼叫進入 sleep、等待某個 child 終止時,充當條件用的 lock。 一個正在結束的 child 會持有 wait_lock 或 p->lock,直到它將自己的狀態設為 ZOMBIE,喚醒 parent,並釋出 CPU 為止
wait_lock 也會序列化 parent 與 child 同時呼叫 exit 的情況,這樣 init process(它會繼承該 child)就能保證會從 wait 中被喚醒。 wait_lock 是一把全域的鎖,而不是每個 parent 都有一把,因為在 process 拿到它之前,它可能還不知道誰是它的 parent
7.10 Real world
xv6 的 scheduler 採用一種簡單的排程策略:輪流執行每個 process,這種策略被稱為輪轉(round robin)。 而實際的作業系統會實作更複雜的策略,例如允許 process 擁有優先權。 這樣一來,scheduler 會傾向選擇可執行的高優先權 process,而不是低優先權的 process。 不過,這類策略通常很快就會變得複雜,因為作業系統往往同時還想達成其他目標,例如公平性與高吞吐量
此外,複雜的排程策略還可能導致一些非預期的互動問題,例如優先權反轉(priority inversion)與護航效應(convoys)。 優先權反轉會發生在高優先權與低優先權的 process 同時使用某個 lock,而這個 lock 被低優先權的 process 持有時,就會阻止高優先權的 process 前進。 若有很多高優先權的 process 在等待同一個低優先權的 process 釋出共享的 lock,就可能形成長串的等待隊列(convoy); 一旦這樣的 convoy 形成,可能會持續很長一段時間,導致效能下降。 為了避免這些問題,更精密的 scheduler 必須加入額外機制
sleep 與 wakeup 是一種簡單而有效的同步方法,但還有很多其他同步方式。 這些方法的首要挑戰是避免本章開頭所提到的「lost wakeups」問題。 早期的 Unix kernel 的 sleep 做法是直接關閉中斷,這在當時單核心的系統上是足夠的。 但因為 xv6 是多核心系統,它對 sleep 加入了額外的 lock
FreeBSD 的 msleep 採取了相同的做法。 Plan 9 的 sleep 則是使用一個 callback function,在進入 sleep 前、持有 scheduler 的 lock 時執行該函數,以作為最後一次檢查 sleep 條件,來避免 lost wakeup。 Linux kernel 的 sleep 使用一個明確的 process queue,稱為 wait queue,來取代 wait channel; 這個 queue 自身有其內部的 lock
在 wakeup 中掃描整個 process 集合是一種低效率的做法。 更好的做法是把 sleep 和 wakeup 中的 chan 換成一種資料結構,這個資料結構能保存所有在該條件上等待的 process,例如 Linux 使用的 wait queue。 Plan 9 的 sleep 與 wakeup 將這個結構稱為 rendezvous point。 許多 thread library 把同樣的東西稱為 condition variable; 在這種情況下,sleep 與 wakeup 的操作分別被稱為 wait 與 signal。 所有這些機制的核心原則是一樣的:sleep 的條件會受到某種 lock 保護,並且這個 lock 會在 sleep 的同時被原子性地釋放
wakeup 的實作會喚醒所有在特定 channel 上等待的 process,而在某些情況下,可能有很多 process 都在等同一個 channel。 作業系統會將這些 process 全部排入排程隊列,然後它們會競爭去檢查 sleep 條件。 這種情況下的 process 行為有時被稱為「雷群效應(thundering herd)」,應該盡量避免這種情況發生。 大多數的 condition variable 提供兩個 wakeup 相關的操作:signal(喚醒一個 process)以及 broadcast(喚醒所有等待中的 process)
semaphore 也經常被用來做同步。它的計數器通常代表像是 pipe buffer 中可用的 byte 數,或是某個 process 擁有的 zombie child 數量。 semaphore 將這個計數值納入抽象的一部分,可以避免「lost wakeup」的問題:因為 wakeup 的次數是有明確計數的。 此外,這個計數也能避免虛假喚醒(spurious wakeup)與雷群效應(thundering herd)的問題
在 xv6 中終止 process 並清理其資源會引入相當多的複雜性。 在大多數作業系統中,這件事甚至更加複雜,因為被終止的 process 可能在 kernel 裡處於深層的 sleep 狀態,而要將它的 call stack 卸除時必須非常小心,因為 call stack 上的每個函數可能都需要做一些清理工作。 有些程式語言提供例外處理機制來協助這類清理,但 C 語言沒有
此外,還有其他事件可能會導致一個正在 sleep 的 process 被喚醒,即使它等待的事件尚未發生。 例如,在 Unix 中,如果一個 process 處於 sleep 狀態,其他 process 可以向它送出 signal。 在這種情況下,該 process 會從被中斷的系統呼叫返回,並回傳 -1,同時將錯誤碼設為 EINTR。 應用程式可以根據這些值來決定後續處理方式。 而 xv6 不支援 signal,因此不會遇到這類複雜性
xv6 中對於 kill 的支援並不完全令人滿意:有些 sleep loop 應該要檢查 p->killed 卻沒有檢查。 另一個相關的問題是,即便某些 sleep loop 會檢查 p->killed,仍然會遇到 sleep 與 kill 之間的競爭條件:kill 可能會在 victim 的 loop 檢查完 p->killed,但尚未呼叫 sleep 之前設下 p->killed 並試圖喚醒 victim。 如果發生這種情況,victim 將無法察覺 p->killed,直到它所等待的條件真的發生。 這可能會是很久以後,甚至永遠不會發生(例如如果 victim 在等待來自 console 的輸入,而使用者沒有打字)
Tips
kill 會設定 p->killed 並叫醒 process,但如果 process 剛好檢查過 p->killed 但還沒真的去 sleep,那麼它會 miss 掉這個訊號。 結果就是 process 還是 sleep 了,等不到喚醒,直到條件真的成立才醒來,這可能永遠不會發生(如等待輸入)
這是一個經典的 race,解法通常是將檢查條件與睡眠動作做成「原子操作」。 在 xv6 中 sleep 實作是:呼叫者先持有某個 lock,然後 sleep 把它加入 chan 的等待隊列後釋放 lock 並切換 context,但這中間還是會有空窗期
一個真正的作業系統會使用明確的 free list 來在常數時間內找到空的 proc 結構,而不是像 xv6 那樣在 allocproc 裡用線性搜尋的方式; xv6 採用線性搜尋是為了簡化設計
7.11 Exercises
- 在不使用
sleep與wakeup的前提下,在 xv6 中實作semaphore(可以使用 spin lock)。 挑選幾個使用sleep與wakeup的地方,改用 semaphore 取代。並評估這樣做的結果 - 修正前面提到的
kill與sleep之間的競爭問題,使得當kill發生在 victim 的 sleep loop 已經檢查過p->killed但尚未呼叫sleep之間時,victim 仍能放棄目前的系統呼叫 - 設計一個機制,讓所有 sleep loop 都會檢查
p->killed。 例如,讓在 virtio driver 中的 process 被其他 processkill時,能夠快速跳出 while loop - 修改 xv6,使從一個 process 的 kernel thread 切換到另一個時,只需要一次 context switch,而不是透過 scheduler thread。 使讓出 CPU 的 thread 自行選出下一個要執行的 thread 並呼叫
swtch。 挑戰包括避免多顆 CPU 同時執行同一個 thread、處理鎖的正確性,以及避免 deadlock - 修改 xv6 的
scheduler,當沒有任何 process 可執行時,使用 RISC-V 的WFI(wait for interrupt)指令。 嘗試確保只要還有 process 處於 runnable 狀態,就不會有 CPU 還在執行WFI