
xv6 riscv book chapter 6:Locking
xv6 riscv book chapter 6:Locking
包括 xv6 的大多數 kernel,在執行時都會交錯進行多個活動。 造成交錯的其中一個原因是多核的硬體:例如 xv6 的 RISC-V 支援多個獨立執行的 CPU。 這些 CPU 會共用實體 RAM,而 xv6 會善用這樣的特性來維護那些所有 CPU 都會讀寫的資料結構。 這種共用會產生一個問題,就是當某個 CPU 正在讀某個資料結構的同時,另一個 CPU 可能正好在修改它,甚至可能有多個 CPU 同時在修改同一筆資料
若沒有謹慎設計,這種平行存取很可能導致錯誤的結果,甚至破壞資料結構。 即便在單核心系統中,kernel 也可能在多個執行緒之間切換,使得它們的執行交錯進行。 最後,若某個裝置的 interrupt handler 與可被中斷的程式碼會修改同一份資料,而中斷剛好在不恰當的時機發生,則也可能會破壞資料。 並行(concurrency)這個詞就是指這種多條指令流因為多核平行處理、執行緒切換,或中斷而產生交錯的情況
kernel 中充滿了會被並行存取的資料。 舉例來說,兩個 CPU 可能會同時呼叫 kalloc,導致它們同時從 free list 的開頭取出項目。 kernel 的設計者傾向允許大量的並行,因為這樣可以透過平行運作提升效能,也能讓系統的反應更快。 但也因此,設計者必須在這樣的並行條件下,確保系統的正確性。 要寫出正確的程式碼有很多方法,也有一些較簡單的方法。 在並行情況下確保正確性的策略,以及支援這些策略的抽象機制,統稱為並行控制(concurrency control)技術
xv6 依據不同情況使用多種並行控制技術,而實際上還有更多其他可能的做法。 本章會聚焦在一種被廣泛使用的技術:鎖(lock)。 lock 提供互斥(mutual exclusion),確保每次只有一個 CPU 能持有這個鎖。 如果程式設計者為每個共享資料加上一把對應的鎖,並且在使用這份資料時總是持有這把鎖,那麼每次就只有一個 CPU 能使用這筆資料。 我們稱這種情況為「lock 保護了這筆資料」。 儘管 lock 是一種易於理解的並行控制機制,但它的缺點是可能會限制效能,因為它會讓原本可以並行的操作變成序列化的執行
本章接下來將說明 xv6 為何需要鎖、xv6 是如何實作鎖的,以及它是如何使用這些鎖的
6.1 Races
這邊用一個例子來說明為何我們需要鎖:假設有兩個 process,它們各自都有已結束(exited)的子行程,且這兩個 parent 在不同的 CPU 上呼叫了 wait。 由於 wait 會釋放子行程的記憶體,因此在每個 CPU 上,kernel 都會呼叫 kfree 來釋放這些子行程的記憶體 page
kernel 的記憶體分配器維護一個 linked list:kalloc() 會從 free list 中彈出一個 page,kfree() 則會把一個 page 推回 free list。 為了最佳效能,我們或許會希望這兩個 parent process 的 kfree 能同時並行執行,互不等待,但以 xv6 的 kfree 實作來說,這樣做是不正確的
圖 6.1 更詳細地說明了這個情境:free page 的 linked list 位於兩個 CPU 共享的記憶體中,而它們使用 load 與 store 指令來操作這個 list(實際上處理器內會有 cache,但概念上多處理器系統的行為就像是共享單一記憶體一樣)
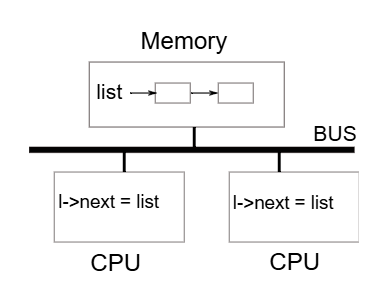
如果沒有並行的請求,則 list 的 push 實作可能如下:
struct element {
int data;
struct element *next;
};
struct element *list = 0;
void
push(int data)
{
struct element *l;
l = malloc(sizeof *l);
l->data = data;
l->next = list;
list = l;
}這段實作在單獨執行時是正確的,然而當多個實例同時執行時,這段程式就不正確了。 如果兩個 CPU 同時執行 push,那麼它們都可能如圖 6.1 所示地執行 l->next = list,這會導致在它們都還沒來得及執行 list = l 之前,就出現如圖 6.2 所示的錯誤結果:兩個 list 節點的 next 都指向原本的 list,而當這兩次 list = l 被執行時,第二次的賦值會覆蓋第一次的結果,導致第一次的節點遺失
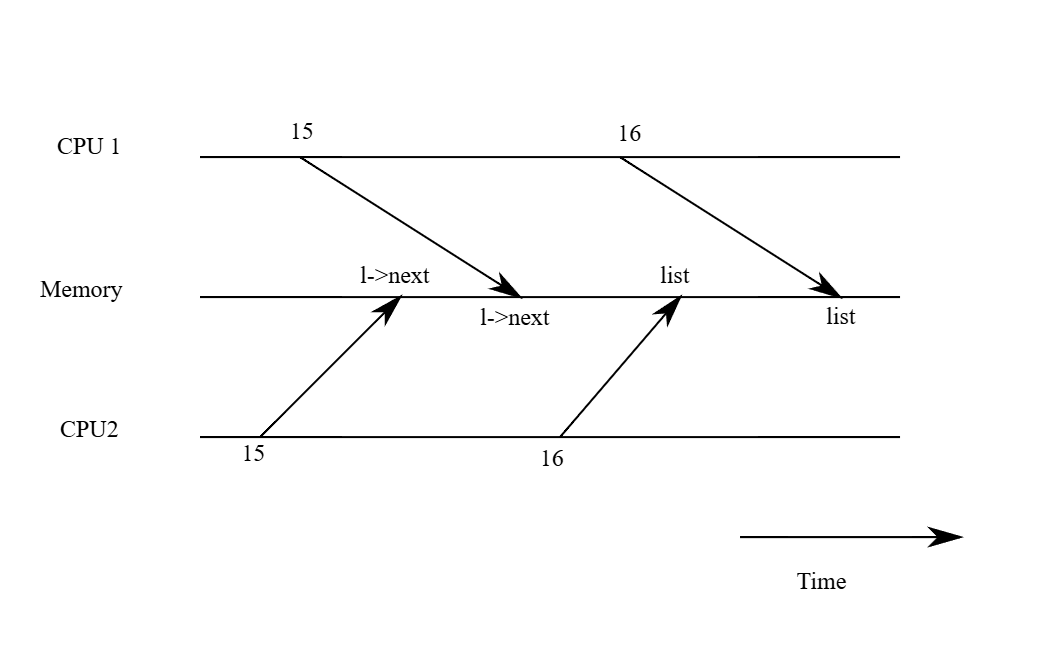
在 list = l 發生的資料遺失就是一個競爭(race)的例子。 race 是指某個記憶體位置被多個執行緒或 CPU 同時存取,而且其至少有一個是寫入操作。 race 通常代表有 bug,要麼是更新被遺失(如果是多次寫入),要麼是讀到尚未完整更新的資料結構。 race 的結果會受到編譯器產生的機器碼、兩個 CPU 執行的時序,以及記憶體系統安排這些操作順序的方式影響,因此 race 導致的錯誤常常很難重現與除錯。 舉例來說,在 debug push 時加上 print statement 可能就改變了執行時序,使 race 的情況消失
避免 race 最常見的方法就是使用 lock。 lock 可以保證互斥(mutual exclusion),也就是在任一時間點,只有一個 CPU 能執行 push 中敏感的程式碼部分,這樣就能完全避免發生上述錯誤情況。 正確加上 lock 的版本只需要新增幾行:
struct element *list = 0;
struct lock listlock; // add this line
void
push(int data)
{
struct element *l;
l = malloc(sizeof *l);
l->data = data;
acquire(&listlock); // add this line
l->next = list;
list = l;
release(&listlock); // add this line
}在 acquire 與 release 之間的這段程式碼稱為臨界區(critical section)
我們通常說某個 lock 保護了某筆資料,這種時候實際上是指這個 lock 保護了一組描述這筆資料不變式(invariants),不變式是資料結構在不同操作之間需要維持的「性質」。 通常,一個操作是否正確,會仰賴於操作開始時那些不變式是否成立。 這個操作可能會在執行過程中暫時破壞這些不變式,但它必須在結束前再次恢復它們。 舉例來說,在 linked list 的例子中,不變式包括 list 應該指向串列的第一個節點,且每個節點的 next 欄位應該指向下一個節點
在 push 的實作中,這個不變式會被暫時打破:在 l->next = list 處,l 就已經指向了下一個節點,但此時 list 還沒指向 l(直到 list = l 才重新建立起來)。 前面我們討論的 race 發生的原因就是有另一個 CPU 在這些不變式暫時無效時執行了依賴於它們的操作。 正確使用 lock 可以確保任何時刻只有一個 CPU 可以在臨界區內操作資料結構,從而避免在不變式尚未成立的情況下執行錯誤的操作
你可以把 lock 想成是「序列化(serializing)」多個並行的臨界區,使它們一次只會有一個執行,從而保護那些不變式(前提是這些臨界區在單獨執行時本身就是正確的)。 你也可以這樣理解:由同一個 lock 保護的臨界區彼此之間具有「原子性」,也就是它們彼此之間只會看到其他臨界區完整執行後的結果,而永遠不會看到執行到一半的中間狀態
雖然 lock 對於確保正確性很有幫助,但它本質上會限制效能。 舉例來說,若兩個 process 同時呼叫 kfree,lock 會將這兩段臨界區序列化地執行,但這樣就無法透過使用不同 CPU 來得到效能上的好處了。 我們會說多個 process 在同時需要同一把 lock 時產生了衝突(conflict),或者說這把 lock 發生了競爭(contention)
kernel 設計中一大挑戰就是如何在追求平行化的同時避免 lock contention。 xv6 在這方面的設計比較少,但較進階的 kernel 則會特別針對資料結構與演算法設計來避免 contention。 以 list 為例,有些 kernel 會為每個 CPU 維護一個獨立的 free list,只有在當前 CPU 的 list 是空的情況下,才會去「偷取」別的 CPU 的記憶體。 其他應用場景則可能需要更複雜的設計
lock 的放置位置對效能也很重要。 舉例來說,雖然把 push 中的 acquire 移到更早的位置(例如放在 l = malloc(sizeof *l) 前)也是正確的作法,但這麼做可能會降低效能,因為這樣 malloc 的呼叫也會被序列化。 下面的「Using locks」小節會提供一些指引,說明該如何選擇 acquire 和 release 的插入位置
6.2 Code: Locks
xv6 有兩種類型的 lock:spinlock 和 sleep-lock。 我們先從 spinlock 開始介紹,xv6 用一個 struct spinlock 來表示一個 spinlock(kernel/spinlock.h:2)。 這個結構中最重要的欄位是 locked,當這個欄位為 0 表示 lock 是可用的,非零則表示 lock 已被持有。 從邏輯上來說,取得一把 lock 的實作可能長這樣:
void
acquire(struct spinlock *lk) // does not work!
{
for(;;) {
if(lk->locked == 0) {
lk->locked = 1;
break;
}
}
}不幸的是,這段實作在多核系統中無法保證互斥(mutual exclusion)。 可能會有兩個 CPU 同時執行到 if(lk->locked == 0) 這一行,且都發現 lk->locked 為 0,然後都執行 assign 將它設為 1,結果就是兩個不同的 CPU 都以為自己取得了這把 lock,這違反了互斥的基本原則。 因此我們需要一種能讓 lock 的判斷和 lock 的索取這兩行變成一個原子(不可分割)操作的方法
由於 lock 的使用非常普遍,多核處理器通常會提供某些指令,來實作判斷與索取 lock 的原子版本。 RISC-V 提供了 amoswap r, a 這條指令,其會讀取記憶體位址 a 的內容,然後將暫存器 r 的值寫入該位址,並把原先記憶體中的值存回 r。 換句話說,它會原子性地交換暫存器和記憶體位址的內容。這個過程是不可中斷的,硬體會確保在這個讀寫過程中沒有其他 CPU 介入存取這塊記憶體
xv6 的 acquire(kernel/spinlock.c:22)函式使用了一個可移植的 C 函式 __sync_lock_test_and_set,它的底層實作會轉換成 amoswap 指令; 這個函式會回傳 lk->locked 這個欄位的舊值(也就是 swap 前的值)。 acquire 會將這個 swap 操作包在一個迴圈裡,不斷重試(自旋),直到成功取得 lock 為止
每次迴圈都會嘗試將 1 寫入 lk->locked,並檢查它原本的值; 如果原本的值是 0,代表我們成功取得了 lock,且這次的 swap 會將 lk->locked 設為 1。 如果原本的值是 1,代表有其他 CPU 已經持有這把 lock,而這次我們雖然也執行了 swap,把 1 寫了進去,但其並沒有改變原來的值(都是 1)
為了除錯用途,當成功取得 lock 後,acquire 會紀錄是哪個 CPU 取得了這把 lock(lk->cpu)。 lk->cpu 這個欄位也會被該 lock(lk)保護,因此只能在持有該 lock 的情況下修改它
release(kernel/spinlock.c:47)函式與 acquire 相反:它會先清空 lk->cpu 欄位,然後釋放 lock。 從概念上來看,釋放 lock 只需要將 lk->locked 設為 0 就可以了。 但是 C 語言標準允許編譯器用多個 store 指令來實作單個 assignment,所以賦值操作在多執行緒的環境下可能不會是 atomic 的。 為了避免這個問題,release 使用了 C 標準庫中的 __sync_lock_release 函式,這個函式會做原子性的賦值以將 lk->locked 設為 0,它的底層也會轉換成 RISC-V 的 amoswap 指令
6.3 Code: Using locks
xv6 在許多地方使用了 lock 來避免 race condition。 就如前面提到的,kalloc(kernel/kalloc.c:69)和 kfree(kernel/kalloc.c:47)是很好的例子。你可以嘗試做第 1 和第 2 題練習,看看當這些函式省略 lock 時會發生什麼事。 你可能會發現實際上我們很難觸發明顯的錯誤行為,這也顯示要可靠地測試某段程式碼是否真的沒有 lock 的問題或 race condition 是很困難的。 xv6 本身也可能仍有尚未被發現的 race 問題
使用 lock 最困難的地方之一是決定要使用多少把 lock,以及每把 lock 應該保護哪些資料與不變式,這有一些基本原則可以遵循。 第一,當某個變數可能在一個 CPU 上被寫入,同時又可能在另一個 CPU 上被讀取或寫入,就應該使用 lock 來防止這兩個操作重疊。 第二,記住 lock 的目的是保護不變式:如果某個不變式涵蓋了多個記憶體位置,那麼通常這些位置都應該由同一把 lock 保護,才能確保這個不變式不會被破壞
上述規則說明了何時需要加鎖,但並未說明什麼情況下不需要加鎖。 如前面所述,為了效能考量,我們不應該過度地加鎖,因為鎖會減少平行性。 如果不需要平行性,那可以只用單一執行緒,這樣就不用擔心加鎖的問題。 一個簡單的 kernel 在多核系統上也可以這麼做:只要在進入 kernel 時取得一把全域的 lock,離開時再釋放(但像是 pipe 的讀取或 wait 之類會阻塞的系統呼叫會變得比較麻煩)
很多單核作業系統就是用這種方式轉移到多核環境的,這種做法有時被稱為「big kernel lock」。 但這會犧牲平行性:任何時候只有一個 CPU 能執行 kernel。 如果 kernel 需要進行大量地運算,改用更多、且範圍較小的 lock 會更有效率,這樣 kernel 才能同時在多個 CPU 上執行
以 coarse-grained(粗粒度)lock 為例,xv6 實作在 kalloc.c 中的記憶體分配器內,整個 free list 是由一把 lock 所保護的。 如果有多個 process 在不同的 CPU 上同時試圖分配記憶體 page,它們就得輪流等待,在 acquire 中自旋。 自旋會浪費 CPU 時間,因為這不算是實質工作。 如果這把 lock 的競爭浪費了大量的 CPU 時間,也許可以透過修改分配器的設計,改為使用多個 free list,每個都有自己的 lock,如此就能真正做到平行地進行記憶體分配
再看一個 fine-grained(細粒度)lock 的例子:xv6 為每個檔案設置了一把獨立的 lock,因此當不同的 process 操作不同的檔案時,通常不需等待彼此的 lock,可以同時進行。 這個檔案鎖的設計其實還可以做得更細,例如若要允許多個 process 同時寫入同一個檔案的不同區塊,就可以再細分鎖的範圍。 最終,鎖的粒度應根據實際效能測試以及系統設計的複雜度來決定
後續章節在介紹 xv6 的各部分時,會提到 xv6 是如何使用 lock 來處理並行問題的。 作為預告,表 6.3 列出了 xv6 中所有使用的 lock
(Figure 6.3: Locks in xv6)
| Lock | Description |
|---|---|
bcache.lock | Protects allocation of block buffer cache entries |
cons.lock | Serializes access to console hardware, avoids intermixed output |
ftable.lock | Serializes allocation of a struct file in file table |
itable.lock | Protects allocation of in-memory inode entries |
vdisk_lock | Serializes access to disk hardware and queue of DMA descriptors |
kmem.lock | Serializes allocation of memory |
log.lock | Serializes operations on the transaction log |
pipe's pi->lock | Serializes operations on each pipe |
pid_lock | Serializes increments of next_pid |
proc's p->lock | Serializes changes to process's state |
wait_lock | Helps wait avoid lost wakeups |
tickslock | Serializes operations on the ticks counter |
inode's ip->lock | Serializes operations on each inode and its content |
buf's b->lock | Serializes operations on each block buffer |
6.4 Deadlock and lock ordering
如果 kernel 中某段程式路徑必須同時持有多把 lock,那麼所有程式路徑都必須以相同的順序取得這些 lock,這一點非常重要,否則會有發生死結(deadlock)的風險。 假設 xv6 中有兩段程式路徑都需要取得 lock A 和 lock B,其中第一段會依序取得 A 再取得 B,而第二段則是先取得 B 再取得 A
假設 thread T1 執行第一段路徑並已取得 lock A,thread T2 執行第二段路徑並已取得 lock B。 接下來 T1 嘗試取得 lock B,而 T2 嘗試取得 lock A。 此時這兩次 acquire 都會無限期阻塞,因為它們彼此持有對方需要的 lock,且只有等到 acquire 成功後才會釋放原本的 lock
為了避免這種死結情況,所有程式路徑都必須依照相同的順序取得 lock。 這也意味著每一把 lock 的取得順序事實上是每個函式行為規格的一部分:呼叫者必須以符合整體約定的方式來使用這些函式,確保 lock 的取得順序一致
由於 sleep 的實作方式(詳見第七章),xv6 中有許多長度為 2 的 lock-order chain,這涉及到每個 process 的 lock(也就是每個 struct proc 中的那把 lock)。 舉例來說,consoleintr(kernel/console.c:136)是處理鍵盤輸入中斷的函式。 當接收到換行字元時,所有正在等待 console 輸入的 process 都應該被喚醒。 為了達成這點,consoleintr 會在持有 cons.lock 的情況下呼叫 wakeup,而 wakeup 在喚醒某個 process 時會取得該 process 的 lock
因此,xv6 為了避免死結,規定全域的 lock 順序中必須先取得 cons.lock,然後才可以取得任何的 process lock。 而在檔案系統中,xv6 則有最長的 lock chain。 例如在建立檔案時,需要同時持有該目錄的 lock、新檔案 inode 的 lock、一個 disk block buffer 的 lock、硬碟驅動程式的 vdisk_lock,以及呼叫者的 p->lock。 為了避免死結,檔案系統程式碼必須依照前述順序來依次取得這些 lock
要遵守全域的、避免死結的 lock 取得順序,其實比想像中困難。 某些時候,這樣的 lock 順序會與程式邏輯的結構衝突。 例如,某個模組 M1 呼叫另一個模組 M2,但 lock 的順序卻要求先取得 M2 的 lock,才能取得 M1 的 lock。 也有時候,在事前根本不知道下一把要取得的 lock 是哪一個,因為可能必須先持有某把 lock 才能知道下一個要鎖的是誰
這種情況會出現在檔案系統中,像是在依序解析路徑名稱的每一層時會發生,也會出現在 wait 與 exit 搜尋 process table 中的子行程時。 最後,避免死結的需求也常常限制了 lock 粒度的細緻程度,因為使用越多的 lock,死結發生的機會也越高。 事實上,如何避免死結,常常是 kernel 實作時的一個主要考量因素
6.5 Re-entrant locks
乍看之下,某些死結與 lock 順序的難題似乎可以透過使用 re-entrant locks(又稱為 recursive locks)來避免。 這種 lock 的設計概念是:如果某個 process 已經持有了一把 lock,並且它再次嘗試去取得同一把 lock,那麼 kernel 可以直接允許這件事發生(因為這個 process 已經擁有該 lock),而不是像 xv6 那樣直接觸發 panic
然而事實上,re-entrant lock 反而讓並行性的分析變得更困難:它破壞了一個重要的直覺,也就是「持有 lock 的區段之間具有原子性(critical section 彼此互斥)」。 來看看以下這些函式:f、g,以及一個假設性的函式 h:
struct spinlock lock;
int data = 0; // protected by lock
f() {
acquire(&lock);
if(data == 0){
call_once();
h();
data = 1;
}
release(&lock);
}
g() {
acquire(&lock);
if(data == 0){
call_once();
data = 1;
}
release(&lock);
}
h() {
...
}觀察這段程式碼,我們會直覺地認為 call_once 只會被呼叫一次:要麼是在 f 中被呼叫,要麼是在 g 中,但不會兩者都呼叫。 但如果允許使用 re-entrant lock,而且 h 恰好又呼叫了 g,則 call_once 將會被呼叫兩次
如果不允許使用 re-entrant lock,那麼當 h 呼叫 g 會造成死結,這雖然也不好,但如果重複呼叫 call_once 是一個嚴重錯誤的話,那麼死結反而是比較可以接受的情況。 因為 kernel 開發者會觀察到這個死結(kernel 會 panic),然後可以修正這段程式碼來避免它; 而若是 call_once 被呼叫了兩次,可能會默默地造成一個很難追蹤的錯誤
基於這個原因,xv6 採用的是較容易理解的 non-re-entrant(不可重入)lock。 當然,只要程式設計者謹記加鎖的規則,這兩種方式都可以良好運作。 如果 xv6 要改成支援 re-entrant lock,就必須修改 acquire,讓它能夠辨識目前的 lock 是否已經被呼叫該函式的 thread 持有。 此外還需要在 struct spinlock 中加入一個用來記錄巢狀鎖定次數的欄位,其設計方式會類似接下來會介紹的 push_off
6.6 Locks and interrupt handlers
有些 xv6 的 spinlock 用來保護同時被 thread 與 interrupt handler 存取的資料。 舉例來說,clockintr 這個 timer interrupt handler 可能會於 kernel thread 正在 sys_sleep(kernel/sysproc.c:61)中讀取 ticks(kernel/trap.c:164)時,嘗試把 ticks 加一。 為了序列化這兩種存取,xv6 使用 tickslock 這把 lock 來保護 ticks
spinlock 與中斷的交互作用會帶來潛在的危險。 假設現在 sys_sleep 已經持有了 tickslock,而此時該 CPU 被 timer interrupt 打斷,進入 clockintr。 clockintr 接著會嘗試取得 tickslock,發現它已被持有,於是就會等待釋放。 但問題在於:這把 lock 只能由 sys_sleep 釋放,而 sys_sleep 又無法繼續執行,因為中斷尚未結束。 因此整個 CPU 會陷入死結,所有需要這把 lock 的程式碼也會跟著卡住
Tips
這段描述的是一種「自我死結」情境,也稱為 interrupt-induced deadlock:thread 拿著 lock 時被中斷,而 interrupt handler 又需要那把 lock,但 thread 又得等中斷結束才會繼續執行。 兩者互相依賴,導致整個 CPU 無限等待。 這個問題特別會發生在 spinlock 無法 sleep 的情況下
為了避免上述情況,如果某把 spinlock 是會被中斷處理函式使用的,那麼任何 CPU 在持有這把 lock 的期間,都絕對不能允許中斷。 xv6 採取更保守的做法:當 CPU 取得任何 lock 時,xv6 都會先關閉該 CPU 的中斷。 其他 CPU 上的中斷仍然可以發生,所以在其他 CPU 上,interrupt handler 仍可能會去 acquire 某把 spinlock,只是不能在持有該 lock 的同一 CPU 上這樣做
xv6 會在 CPU 不再持有任何 spinlock 時重新開啟中斷。 為了支援巢狀的 critical section,它必須做一些狀態紀錄。 acquire 會呼叫 push_off(kernel/spinlock.c:89),release 則會呼叫 pop_off(kernel/spinlock.c:100),這兩個函式用來追蹤目前 CPU 上的 lock 巢狀層數。 當這個巢狀層數變成 0 時,pop_off 會還原當初進入最外層 critical section 時的中斷狀態。 intr_off 與 intr_on 則分別對應執行 RISC-V 關閉與開啟中斷的指令
非常重要的一點是,acquire 必須在設置 lk->locked(kernel/spinlock.c:28)之前就先呼叫 push_off。 如果順序顛倒,就會出現一個短暫的時間區間,在那期間 lock 已經被持有,但中斷仍然是開啟的,此時若剛好發生中斷,就會導致整個系統死結。 同樣地,也必須在釋放 lock 之後才呼叫 pop_off(kernel/spinlock.c:66)
6.7 Instruction and memory ordering
直覺上我們會認為程式會按照原始碼中語句出現的順序執行。 對於單執行緒的程式碼而言,這種心智模型是合理的,但在多個執行緒透過共享記憶體進行互動時,這個模型就是錯誤的了[1], [2]。 原因之一是:編譯器產生的 load 與 store 的指令順序,可能與原始碼中所暗示的順序不同,甚至可能完全省略某些指令(例如把資料暫存在暫存器中,根本不寫回記憶體)。 另一個原因是 CPU 為了提升效能,可能會重新安排指令的執行順序。 舉例來說,若指令序列中的 A 與 B 彼此沒有依賴性,那麼 CPU 可能會先執行 B,這可能是因為 B 的輸入比較早準備好,或是為了與 A 的執行重疊來增加平行性
來看看以下 push 的實作,它展示了可能出錯的情境。 如果編譯器或 CPU 把第 4 行的 store 操作移到第 6 行的 release 之後,那會造成災難性的後果:
l = malloc(sizeof *l);
l->data = data;
acquire(&listlock);
l->next = list; // line 4
list = l;
release(&listlock); // line 6如果真的發生這樣的重新排序,那就會出現一個短暫的時間區間,期間其他 CPU 可能取得這把 lock,並看到已更新的 list,但此時的 list->next 還未被初始化
好消息是,編譯器與 CPU 都會遵循一套稱為 memory model(記憶體模型)的規則,來幫助並行程式設計者。 此外它們也提供一些原語(primitives),讓程式設計者能控制重新排序的行為
Tips
儘管存在重新排序的風險,但作業系統或語言層提供了記憶體模型(如 C/C++11 memory model、RISC-V memory model)來讓這些行為可預測。 更進一步的工具像是:
- memory barriers / fences:指令級別的排序限制
- atomic operations:具有特定順序語意的同步原語
這些工具能幫助開發者明確告訴 CPU/編譯器「不要進行重新排序」
為了告訴硬體與編譯器「不要進行重新排序」,xv6 在 acquire(kernel/spinlock.c:22)與 release(kernel/spinlock.c:47)中都使用了 __sync_synchronize() 函式。 這個函式是一種 memory barrier(記憶體屏障),它會要求編譯器與 CPU 不要讓 loads 或 stores 穿越這道屏障而重新排序。 xv6 的 acquire 與 release 函式中的這些屏障,幾乎在所有重要的情況下都能強制確保正確的執行順序,因為 xv6 會用 lock 包住對共享資料的存取。 不過在第九章中還會討論一些例外情況
6.8 Sleep locks
有時候 xv6 需要長時間持有一把鎖。 例如檔案系統(見第八章)在從硬碟讀寫檔案內容時會將檔案上鎖,而這些硬碟操作可能會花上數十毫秒。 若在這段期間持有一把 spinlock,會造成浪費,因為如果其他 process 想取得這把 lock,就會在這段時間中不斷自旋、浪費 CPU 資源。 另一個使用 spinlock 的缺點是,process 在持有 spinlock 時無法讓出 CPU
但我們希望 process 在等待硬碟時能讓出 CPU,好讓其他 process 可以使用,然而在持有 spinlock 時讓出 CPU 是不合法的,因為這可能導致 deadlock:如果此時另一條執行緒也想取得這把 spinlock,而 acquire 並不會讓出 CPU,那麼這條執行緒就會自旋,可能阻止原本持有 lock 的執行緒再次執行、從而無法釋放 lock
在持有 lock 的狀態下讓出 CPU,也會違反 spinlock 所要求的「必須關閉中斷」的條件。 因此,我們希望有一種 lock,在等待獲得時可以讓出 CPU,並且在持有 lock 的期間也能讓出 CPU(甚至允許中斷發生)
xv6 提供了 sleep-lock 來滿足這個需求。 acquiresleep(kernel/sleeplock.c:22)在等待期間會讓出 CPU,具體機制會在第七章詳細說明。 簡單來說,sleep-lock 內部有一個 locked 欄位,由一把 spinlock 保護,acquiresleep 中會呼叫 sleep,並在這個呼叫中以原子地方式同時讓出 CPU 並釋放 spinlock。 這樣的設計讓其他執行緒可以在 acquiresleep 等待期間繼續執行
由於 sleep-lock 不會關閉中斷,因此不能在 interrupt handler 中使用。 又因為 acquiresleep 可能會讓出 CPU,所以 sleep-lock 也不能被用在 spinlock 的 critical section 內(不過反過來,spinlock 可以在 sleep-lock 的 critical section 裡使用)
總的來說,spinlock 適合用在短暫的 critical section,因為等待它會浪費 CPU; 而 sleep-lock 則適合用在耗時較長的操作上
6.9 Real world
即使經過了多年針對並行原語與平行運算的研究,使用 lock 進行程式設計仍然是一項困難的挑戰。 將 lock 隱藏在像是 synchronized queue 這種高階結構中通常是比較好的做法,不過 xv6 並沒有這樣做。 如果你必須直接使用 lock 來寫程式,建議搭配能偵測 race condition 的工具,因為人們很容易漏掉某些需要 lock 保護的不變性條件
大多數作業系統都支援 POSIX threads(Pthreads),這允許一個使用者行程能同時在多個 CPU 上執行數個執行緒。 Pthreads 提供了使用者層級的 lock、barrier 等功能。 Pthreads 也允許程式設計者指定某些 lock 是否要支援 re-entrant
在使用者層級實作 Pthreads 需要作業系統的支援。 例如,如果一個 pthread 在某個系統呼叫中被 block,則同一個 process 中的其他 pthread 應該仍能在那顆 CPU 上繼續執行。 又例如,如果某個 pthread 改變了整個 process 的位址空間(像是對記憶體進行 map 或 unmap),kernel 必須讓所有在其他 CPU 上執行該 process 的執行緒也能更新它們的 page table hardware,以反映這個位址空間的改變
雖然可以在不使用 atomic instruction 的情況下實作 lock[3],但這樣的做法成本很高,因此大多數作業系統會選擇使用 atomic instruction 來實作 lock
當多個 CPU 同時嘗試 acquire 同一把 lock 時,這個 lock 的開銷就會變得很高。 如果某個 CPU 把 lock 保存在它的本地快取中,而另一個 CPU 想要取得這把 lock,那麼用來更新這段快取的 atomic instruction 必須先將這條 cache line 從原本的 CPU 移動到目標 CPU,並可能需要讓其他 CPU 中的快取副本失效。 從其他 CPU 的快取中取出 cache line 的成本,可能會比從本地快取中取得的成本還高出數十倍
為了避免 lock 帶來的高開銷,許多作業系統會使用 lock-free 的資料結構與演算法[4], [5]。 例如,可以設計一個 linked list,在查詢的時候完全不需要用 lock,而插入時也只需一個 atomic 指令。 不過 lock-free 程式設計比使用 lock 更加複雜,例如必須考慮指令與記憶體的重排序。 考慮到用 lock 寫程式已經夠困難了,因此 xv6 選擇不加入 lock-free 機制,以減少複雜性
6.10 Exercises
- 註解掉
kalloc中對acquire與release的呼叫(kernel/kalloc.c:69)。 這應該會對呼叫kalloc的 kernel 程式碼造成問題。 你預期會看到什麼症狀? 當你執行 xv6 時是否真的看到了這些症狀? 執行usertests時又會如何? 如果你沒有看到任何問題,那是為什麼? 試著在kalloc的 critical section 中加入一些 dummy 的迴圈,看看能不能讓問題更明顯 - 假設你恢復
kalloc的 locking,改為註解掉kfree的 locking,那會發生什麼問題? 相比之下,kfree缺少 lock 是不是沒kalloc那麼嚴重? - 如果兩個 CPU 同時呼叫
kalloc,其中一個必須等待另一個,這對效能是有害的。 請修改 kalloc.c 增加並行性,使得不同 CPU 上的kalloc呼叫可以同時進行,而不必互相等待 - 使用 POSIX threads 撰寫一個平行程式(大多數作業系統都有支援)。 例如你可以實作一個平行的 hash table,並測量當 CPU 數增加時,put/get 的數量是否能跟著擴張
- 在 xv6 上實作一個簡化版的 Pthreads。 也就是實作一個使用者層級的 thread library,使得一個使用者行程可以有不只一個 thread,並安排這些 thread 可以在不同 CPU 上平行執行。 請設計一套正確處理 blocking system call 與共享位址空間改動的方案
Bibliography
- [1]:The RISC-V instruction set manual Volume I: unprivileged specification ISA. https://drive.google.com/file/d/17GeetSnT5wW3xNuAHI95-SI1gPGd5sJ_/view?usp=drive_link, 2024.
- [2]:Hans-J Boehm. Threads cannot be implemented as a library. ACM PLDI Conference, 2005.
- [3]:L Lamport. A new solution of dijkstra’s concurrent programming problem. Communications of the ACM, 1974.
- [4]:Maurice Herlihy and Nir Shavit. The Art of Multiprocessor Programming, Revised Reprint. 2012.
- [5]:Paul E. Mckenney, Silas Boyd-wickizer, and Jonathan Walpole. RCU usage in the linux kernel: One decade later, 2013.