
xv6 riscv book chapter 1:Operating system interfaces
xv6 riscv book chapter 1:Operating system interfaces
作業系統的任務,是要讓多個程式能夠共享同一部電腦,並提供比硬體本身更多、更加實用的功能。 作業系統負責管理並抽象化底層硬體,使得如文字處理器這類應用程式無需關心所使用的是哪一種硬碟。 作業系統能讓多個程式共享硬體資源,並使它們能夠同時執行(或至少看起來是同時執行)。 最後,作業系統還提供讓程式之間可以互相溝通的介面,使它們能夠共享資料或協同作業
作業系統透過一組介面來向使用者程式提供服務,但要設計一個好的介面其實並不容易。 一方面,我們希望這個介面要簡單且精確,這樣比較容易實作正確; 但另一方面,我們又會想要提供許多進階的功能給應用程式使用。 解決這個矛盾的訣竅是:設計一組依賴少量機制的介面,並讓這些機制可以組合起來,提供高度的通用性
本書將使用一個具體的作業系統作為例子,來說明作業系統的各種概念。 這個作業系統叫做 xv6,它提供了 Ken Thompson 與 Dennis Ritchie 在 Unix 作業系統中所引入的基本介面,並且模仿了 Unix 的內部設計。 Unix 提供的介面通常「精準但可組合性強」,這讓它意外地擁有很高的通用性。 由於這種介面設計地非常成功,以至於現代的作業系統,例如 BSD、Linux、macOS、Solaris,甚至在某種程度上連 Microsoft Windows 都擁有類 Unix 的介面。 而理解 xv6,是理解這些系統(還有許多其他系統)的一個很好的起點
如圖 1 所示,xv6 採用了傳統的 kernel 架構,也就是一個特殊的程式,專門提供執行中程式所需的服務。 每個執行中的程式稱為一個「行程(process)」,它的記憶體會包含指令區、資料區,以及 stack。 指令負責實作該程式的運算邏輯; 資料則是程式操作的變數; stack 則負責組織與管理程式的函式呼叫。 一台電腦通常會同時擁有許多個行程,但只會有一個 kernel
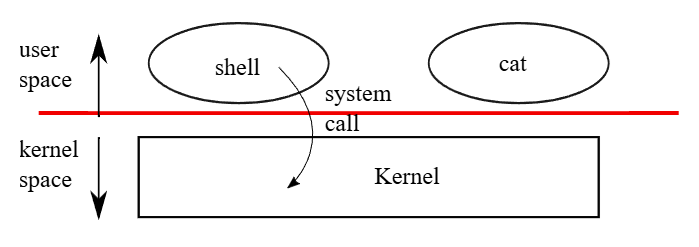
當一個行程需要呼叫 kernel 的服務時,它會發出一個「系統呼叫」,這是作業系統介面中的一種呼叫方式。 這個系統呼叫會進入 kernel,接著 kernel 會執行所請求的服務並返回。 因此一個行程的執行會在 user space 與 kernel space 之間交替進行
如後續章節將詳細說明的,kernel 會使用 CPU 提供的硬體保護機制(本書使用 CPU 一詞來指稱執行運算的硬體元件; 其他文件,如 RISC-V 規格,會使用 processor、core 或 hart 等詞來代替 CPU),來確保每個在 user space 中執行的行程只能存取自己的記憶體。 kernel 本身會於具備特權的硬體模式執行,以實作這些保護機制; 而使用者程式則在沒有這些特權的情況下執行。 當一個使用者程式發出系統呼叫時,硬體會提升執行權限,並開始執行 kernel 中事先安排好的函式
使用者程式所能看見的介面由 kernel 提供的所有系統呼叫組成。 xv6 kernel 提供了一部分傳統 Unix kernel 所具備的服務與系統呼叫。 圖 1.2 列出了 xv6 所提供的全部系統呼叫:
(Figure 1.2: xv6 system calls. If not otherwise stated, these calls return 0 for no error, and -1 if there’s an error)
| System call | Description |
|---|---|
int fork() | Create a process, return child's PID. |
int exit(int status) | Terminate the current process; status reported to wait(). No return. |
int wait(int *status) | Wait for a child to exit; exit status in *status; returns child PID. |
int kill(int pid) | Terminate process PID. Returns 0, or -1 for error. |
int getpid() | Return the current process's PID. |
int sleep(int n) | Pause for n clock ticks. |
int exec(char *file, char *argv[]) | Load a file and execute it with arguments; only returns if error. |
char *sbrk(int n) | Grow process's memory by n zero bytes. Returns start of new memory. |
int open(char *file, int flags) | Open a file; flags indicate read/write; returns an fd (file descriptor). |
int write(int fd, char *buf, int n) | Write n bytes from buf to file descriptor fd; returns n. |
int read(int fd, char *buf, int n) | Read n bytes into buf; returns number read; or 0 if end of file. |
int close(int fd) | Release open file fd. |
int dup(int fd) | Return a new file descriptor referring to the same file as fd. |
int pipe(int p[]) | Create a pipe, put read/write file descriptors in p[0] and p[1]. |
int chdir(char *dir) | Change the current directory. |
int mkdir(char *dir) | Create a new directory. |
int mknod(char *file, int, int) | Create a device file. |
int fstat(int fd, struct stat *st) | Place info about an open file into *st. |
int link(char *file1, char *file2) | Create another name (file2) for the file file1. |
int unlink(char *file) | Remove a file. |
本章接下來將粗略地介紹 xv6 所提供的幾項服務,包含行程管理、記憶體、檔案描述符(file descriptors)、pipes,以及檔案系統,並透過程式碼範例與說明,來展示 Unix 的命令列介面 shell 是如何使用這些功能。 從 shell 對系統呼叫的使用方式,可以看出這些呼叫是如何被精心設計的
shell 是一個普通的程式,它負責讀取使用者輸入的指令並執行。 另外它是一個使用者程式,而不是 kernel 的一部分,這點凸顯了系統呼叫介面的強大之處:shell 並不是什麼特別的程式。 這也代表 shell 很容易被替換; 因此,現代的 Unix 系統都有各式各樣的 shell 可供選擇,每種 shell 都有自己獨特的使用者介面與腳本功能。 xv6 的 shell 是 Unix Bourne shell 精神的一個簡單實作,其程式碼可以在 user/sh.c:1 內找到
1.1 Processes and memory
一個 xv6 行程由 user space 中的記憶體(包含指令、資料與 stack)以及屬於該行程、只有 kernel 能存取的內部狀態所構成。 xv6 採用時間分割(time-sharing)的方式來管理行程:它會在等待執行的行程之間,自動切換可用的 CPU。 當某個行程暫停執行時,xv6 會儲存該行程的 CPU 暫存器,等下次執行該行程時再將其還原。 kernel 還會為每個行程分配一個被稱為 PID(process identifier,行程識別碼)的編號
一個行程可以透過 fork 系統呼叫來建立一個新的行程。 fork 會將原本呼叫者的記憶體完整複製給新建立的行程:它會將呼叫者的指令、資料與 stack 全部複製到新行程中。 fork 會在原本與新建立的行程中各自返回一次,在原本的行程中,fork 會返回新行程的 PID; 而在新建立的行程中,fork 則返回 0。 原本的行程與新建立的行程,通常分別被稱為「父行程」與「子行程」
舉例來說,請看以下這段以 C 語言撰寫的程式碼片段:
int pid = fork();
if(pid > 0){
printf("parent: child=%d\n", pid);
pid = wait((int *) 0);
printf("child %d is done\n", pid);
} else if(pid == 0){
printf("child: exiting\n");
exit(0);
} else {
printf("fork error\n");
}exit 系統呼叫會讓呼叫它的行程停止執行,並釋放像是記憶體與已開啟檔案這類資源。 exit 接收一個整數作為狀態引數,慣例上,0 表示成功,1 表示失敗
wait 系統呼叫會回傳一個已結束(或被終止)的子行程的 PID,並將該子行程的結束狀態寫入「傳給 wait 的記憶體位置」; 如果目前還沒有任何已結束的子行程,wait 就會阻塞,直到有一個子行程結束。 如果呼叫者沒有子行程,wait 會立即回傳 -1。 如果父行程不在意子行程的結束狀態,它可以傳入 0 當作 wait 的引數
在這個範例中,這兩行輸出:
parent: child=1234
child: exiting的順序可能會互換(甚至交錯),這取決於父行程與子行程誰先執行到 printf。 當子行程結束後,父行程中的 wait 呼叫會返回,接著父行程會印出 parent: child 1234 is done。 雖然子行程最初擁有與父行程相同的記憶體內容,但父子行程各自擁有獨立的記憶體與暫存器,因此在其中一方改變變數時,不會影響到另一方。 例如,當 wait 的返回值被存入父行程的變數 pid 中時,也不會改變子行程中的 pid 變數,子行程中的 pid 值仍然是 0
exec 系統呼叫會用從檔案系統中載入的程式映像(memory image),取代呼叫該行程原本的記憶體內容。 這個檔案必須具有特定格式,格式中會定義檔案的哪個部分是指令、哪個部分是資料、從哪個指令開始執行等等。 xv6 採用 ELF 格式,這部分會在第三章中進一步說明,通常這個檔案是將原始碼編譯後所產生的結果
當 exec 成功時,它不會返回到呼叫它的程式; 相反地,從檔案中載入的指令會從 ELF header 中指定的進入點開始執行。 exec 接收兩個引數(argument):一個是包含可執行檔的檔案名稱,另一個是用作引數的字串陣列
舉例來說:
char *argv[3];
argv[0] = "echo";
argv[1] = "hello";
argv[2] = 0;
exec("/bin/echo", argv);
printf("exec error\n");這段程式碼會將目前的程式取代為 /bin/echo 這個程式的執行實例,並帶入引數列表 echo 與 hello。 大多數程式會忽略引數陣列的第一個元素,這個元素慣例上是程式本身的名稱
xv6 的 shell 使用上述系統呼叫來代替使用者執行程式。 這個 shell 的主體結構相當簡單,可以參考 user/sh.c:146 中的 main 函式。 主迴圈會透過 getcmd 從使用者那讀取一行輸入。 接著它會呼叫 fork,建立 shell 行程的複本。 父行程會呼叫 wait,而子行程則負責執行命令
例如,如果使用者在 shell 中輸入 "echo hello",runcmd 就會被呼叫,並以 "echo hello" 作為引數。 runcmd(user/sh.c:55)會執行真正的命令。 對於 "echo hello",它會呼叫 exec(見 user/sh.c:79)。 如果 exec 成功,子行程就會開始執行 echo 的指令,而不是 runcmd。 之後的某個時間點,echo 會呼叫 exit,此時父行程中的 wait 會返回,控制流程便會回到 main 函式中(見 user/sh.c:146)
你可能會想,為什麼 fork 和 exec 不直接合併成一個呼叫; 我們稍後會看到,shell 透過分離它們來實作 I/O 的重導(redirection)功能。 為了避免「建立一個行程複本、接著馬上被 exec 替換掉」這種浪費,kernel 會針對這類用途對 fork 的實作進行最佳化,例如採用虛擬記憶體技術中的 copy-on-write(詳見第 4.6 節)
xv6 對於大部分 user space 的記憶體配置是隱式進行的:fork 會配置足夠的記憶體來複製父行程的記憶體給子行程,exec 則會配置足夠的記憶體以容納可執行檔的內容。 若某個行程在執行期間需要更多記憶體(例如 malloc),可以呼叫 sbrk(n) 來將其資料區延伸 n 個 0 位元組; sbrk 會回傳新記憶體的起始位置
1.2 I/O and File descriptors
檔案描述符(File descriptors)是一個較小的整數,用來表示一個由 kernel 管理的物件,行程可以從這個物件讀取或寫入資料。 行程可以透過開啟檔案、目錄、或裝置、建立 pipe,或複製現有的描述符,來取得一個檔案描述符。 為了簡化說明,我們會將檔案描述符所指向的物件統稱為「檔案」; 檔案描述符這個介面抽象化了檔案、pipe 與裝置之間的差異,使它們看起來都像是 byte stream。 我們會把輸入與輸出稱為 I/O
Tips
雖然名字叫「file」,但其實它可以指向任何 I/O 來源,例如檔案、終端機、pipe、裝置等。 它是一個抽象層,讓程式不用知道背後實體是什麼,就能進行讀寫操作
在內部,xv6 kernel 使用檔案描述符作為每個行程表格中的索引,因此每個行程都有一個從 0 開始的私有檔案描述符空間。 依照慣例,行程從描述符 0(標準輸入)讀取,將輸出寫到描述符 1(標準輸出),將錯誤訊息寫到描述符 2(標準錯誤)。 如我們後面會看到,shell 利用這些慣例來實作 I/O 重導與 pipeline。 預設情況下這三個描述符對應到主控台,因此 shell 會確保它總是打開這三個檔案描述符
read 與 write 系統呼叫會根據檔案描述符,從已開啟的檔案中讀取或寫入位元組。 呼叫 read(fd, buf, n) 會從檔案描述符 fd 所指向的檔案中最多讀取 n 個位元組,接著將它們複製到 buf 中,並回傳實際讀取的位元組數。 每個指向檔案的檔案描述符都會有一個相關的偏移量(offset)。 read 會從目前的偏移位置讀取資料,然後將偏移量往後推移「該次讀取的位元組數」,下一次 read 會接續讀取後面的資料。 當沒有更多資料可讀時,read 會回傳 0,以表示檔案結尾
write(fd, buf, n) 這個呼叫會將 buf 中的 n 個位元組寫入檔案描述符 fd 所指向的目標,並回傳實際寫入的位元組數。 只有在發生錯誤時,才可能寫入少於 n 個位元組。 與 read 類似,write 會從目前的檔案偏移位置開始寫入資料,並在寫入後將偏移量增加「該次寫入的位元組數」,每次 write 都會從上一次結束的位置繼續
以下這段程式碼(它構成了 cat 程式的 kernel 邏輯)會將資料從標準輸入複製到標準輸出。 如果發生錯誤,它會將錯誤訊息輸出到標準錯誤:
char buf[512];
int n;
for(;;){
n = read(0, buf, sizeof buf);
if(n == 0)
break;
if(n < 0){
fprintf(2, "read error\n");
exit(1);
}
if(write(1, buf, n) != n){
fprintf(2, "write error\n");
exit(1);
}
}這段程式碼中最值得注意的是,cat 並不知道它是從檔案、主控台,還是 pipe 中讀取資料的。 同樣地,cat 也不知道它是把資料印到主控台、寫到檔案,還是其他地方。 檔案描述符的使用方式,加上將描述符 0 視為輸入、描述符 1 視為輸出的慣例,使得 cat 的實作可以非常簡潔
close 系統呼叫會釋放一個檔案描述符,讓它可以被日後的 open、pipe 或 dup 系統呼叫(下文會說明)重新使用。 新分配的檔案描述符總是從目前行程中尚未使用的最小編號開始
檔案描述符與 fork 的互動,使得 I/O 重導的實作變得簡單。 fork 會連同父行程的記憶體一起複製其檔案描述符表,因此子行程啟動時會擁有與父行程完全相同的已開啟檔案。 系統呼叫 exec 雖然會取代呼叫者的記憶體,但會保留它的檔案描述符表。 這樣的行為允許 shell 透過「先 fork 出子行程、在子行程中重新開啟指定的檔案描述符、再呼叫 exec 來執行新程式」的方式來實作 I/O 重導
以下是一段簡化版本的 shell 程式碼,模擬執行 cat < input.txt 這條命令的行為:
char *argv[2];
argv[0] = "cat";
argv[1] = 0;
if(fork() == 0) {
close(0);
open("input.txt", O_RDONLY);
exec("cat", argv);
}當子行程關閉檔案描述符 0 之後,open 一定會將新開啟的 input.txt 指派給該描述符,因為 0 是當前可用的最小檔案描述符。 接下來 cat 的執行中,檔案描述符 0(標準輸入)就會對應到 input.txt。 這整個過程只改變了子行程的描述符,父行程的檔案描述符不會受到影響
xv6 shell 中的 I/O 重導就是依照這個方式運作的(user/sh.c:83)。 請記得,在程式執行到這個階段時,shell 已經建立了子行程,而 runcmd 會接著呼叫 exec 來載入新的程式
open 的第二個引數是一組用位元表示的旗標,用來控制 open 的行為。 這些可用的旗標定義在 fcntl.h(file control)中(kernel/fcntl.h:1-5),包括:O_RDONLY、O_WRONLY、O_RDWR、O_CREATE 與 O_TRUNC,它們分別代表以讀取、寫入、讀寫模式開啟檔案,若檔案不存在則會建立該檔案,並將檔案長度截斷為零
現在你應該可以理解,為什麼將 fork 和 exec 設計為分開的呼叫是有幫助的:這兩者之間的空檔,讓 shell 能夠在不影響主 shell 的情況下,重新設定子行程的 I/O。 想像有一個虛構的 forkexec 系統呼叫,那麼要在這樣的架構下實作 I/O 重導會變得相當麻煩。 可能的做法會像:shell 在呼叫 forkexec 前修改自己的 I/O 設定(然後再復原); 或者讓 forkexec 接收 I/O 重導的引數; 或者(這是最不理想的)讓每個像 cat 這樣的程式都學會自己做 I/O 重導
雖然 fork 會複製檔案描述符表,但每個底層檔案的偏移量仍然會在父子行程之間共用。 請看以下這段程式碼:
if(fork() == 0) {
write(1, "hello ", 6);
exit(0);
} else {
wait(0);
write(1, "world\n", 6);
}在這段程式執行結束後,與檔案描述符 1 相關聯的檔案中,將會包含 hello world 這段資料。 父行程的 write(由於有 wait 的關係,會在子行程執行完畢後才執行)會從子行程 write 所留下的位置繼續寫入。 這種行為有助於讓 shell 指令序列產生連續的輸出,例如 (echo hello; echo world) >output.txt
dup 系統呼叫會複製一個已存在的檔案描述符,並回傳一個新的描述符,這個新的描述符會指向相同的底層 I/O 物件。 這兩個檔案描述符會共用一個偏移量,就像透過 fork 複製出的描述符一樣。 以下是另一種將 hello world 寫入到檔案的方法:
fd = dup(1);
write(1, "hello ", 6);
write(fd, "world\n", 6);如果兩個檔案描述符是透過一連串的 fork 和 dup 呼叫,從同一個原始描述符衍生而來的,那它們就會共用偏移量。 否則,即使它們是對同一個檔案使用 open 所得到的描述符,也不會共享偏移量。 dup 允許 shell 實作像這樣的指令:ls existing-file non-existing-file > tmp1 2>&1。 其中的 2>&1 是告訴 shell,將描述符 2(標準錯誤)設為描述符 1(標準輸出)的副本。 這樣,現有檔案的檔名與不存在檔案的錯誤訊息,會同時寫入到 tmp1 這個檔案中。 雖然 xv6 的 shell 不支援錯誤輸出的 I/O 重導,但你現在已經知道如何實作它了
檔案描述符是一個強大的抽象,因為它隱藏了它所連接對象的細節:一個行程在寫入檔案描述符 1 時,實際上可能是在寫入一個檔案、一個像主控台這樣的裝置,或是一個 pipe
1.3 Pipes
pipe 是一塊由 kernel 管理的小型緩衝區,對行程而言,它表現為一對檔案描述符:一個用於讀取、一個用於寫入。 將資料寫入 pipe 的一端,會使這些資料可以從 pipe 的另一端被讀取。 pipe 提供了一種讓行程之間可以互相溝通的方式
以下這段範例程式碼執行了 wc 這個程式,並將其標準輸入接到一個 pipe 的讀取端:
int p[2];
char *argv[2];
argv[0] = "wc";
argv[1] = 0;
pipe(p);
if(fork() == 0) {
close(0);
dup(p[0]);
close(p[0]);
close(p[1]);
exec("/bin/wc", argv);
} else {
close(p[0]);
write(p[1], "hello world\n", 12);
close(p[1]);
}上例程式呼叫了 pipe,這會建立一條新的 pipe,並將讀取與寫入的檔案描述符存放在陣列 p 中。 在 fork 之後,父行程與子行程都擁有指向該 pipe 的描述符。 子行程會呼叫 close 與 dup,讓描述符 0 指向 pipe 的讀取端,然後關閉 p 中的描述符,接著呼叫 exec 來執行 wc。 當 wc 從標準輸入讀取時,它實際上是從這條 pipe 讀資料。 父行程會關閉 pipe 的讀取端、寫入資料,然後再關閉寫入端
如果沒有資料可讀,則對 pipe 進行 read 時會等待「資料被寫入」或「所有指向寫入端的描述符都已關閉」這兩種情況發生; 在後者情況下,read 會回傳 0,就像讀到檔案結尾一樣。 read 會阻塞直到確定不會有新資料出現,這正是為什麼子行程在執行 wc 之前一定要關閉 pipe 寫入端的原因之一:如果 wc 有一個描述符仍然指向 pipe 的寫入端,那它就永遠看不到檔案結尾(EOF)
xv6 的 shell 會用類似上述程式碼的方式來實作像 grep fork sh.c | wc -l 這類的 pipeline 指令。 子行程會建立一條 pipe,用來連接 pipeline 左端與右端。 接著,它會為 pipeline 的左端呼叫 fork 與 runcmd,接著為右端也呼叫 fork 與 runcmd,並等待兩者完成。 pipeline 的右端本身可能也包含 pipeline(例如 a | b | c),這會額外再 fork 出兩個子行程(分別給 b 和 c)。 因此,shell 最終可能建立出一棵行程樹。 這棵樹的葉節點是實際執行的命令,而內部節點則是負責等待左右子行程完成的過渡行程
pipe 在表面上看起來與暫存檔案並無太大差別,這段 pipeline 程式
echo hello world | wc也可以改用暫存檔來實作,不用 pipe:
echo hello world >/tmp/xyz; wc </tmp/xyz但在這種情況下,pipe 相較於暫存檔至少有三項優勢:
- 第一,pipe 會自動清除自身; 如果使用檔案重導,執行完後 shell 必須另外小心地移除
/tmp/xyz - 第二,pipe 能傳遞任意長度的資料流,而檔案重導方式則需要硬碟上有足夠空間來儲存全部資料
- 第三,pipe 允許 pipeline 中的各階段並行執行,而使用檔案的做法則要求第一個程式必須先結束,第二個才能開始
1.4 File system
xv6 的檔案系統提供了「資料檔案(data files)」與「目錄(directories)」,前者的內容是未經詮釋的位元組陣列,而後者的內容是指向資料檔案與其他目錄的具名引用(named reference)。 目錄之間會形成一棵樹狀結構,其從一個特別的目錄開始,稱為 root(根目錄)。 像 /a/b/c 這樣的路徑,表示在根目錄 / 底下的 a 目錄中的 b 目錄中的 c 檔案或目錄。 如果路徑不是以 / 開頭,則會根據呼叫該程式的行程「當下的目前目錄(current directory)」來解析; 這個目前目錄可以透過 chdir 系統呼叫來變更
以下兩段程式碼會開啟同一個檔案(假設中間所有目錄皆已存在):
chdir("/a");
chdir("b");
open("c", O_RDONLY);
open("/a/b/c", O_RDONLY);第一段程式會將目前目錄改為 /a/b; 第二段則完全不會去變動目前目錄的位置
xv6 提供了一些系統呼叫來建立新的檔案與目錄:
mkdir用來建立新的目錄- 在呼叫
open時加上O_CREATE標誌,則會建立新的資料檔案 mknod則用來建立新的裝置檔案
下面這個範例示範了三者的使用方式:
mkdir("/dir");
fd = open("/dir/file", O_CREATE|O_WRONLY);
close(fd);
mknod("/console", 1, 1);mknod 會建立一個特殊檔案,該檔案代表一個裝置。 與裝置檔案相關聯的是主裝置號與次裝置號(即 mknod 的兩個引數),其能用來唯一識別一個 kernel 中的裝置。 之後行程開啟該裝置檔案時,kernel 會將 read 和 write 系統呼叫轉向裝置驅動程式的實作,而不是交由檔案系統處理
一個檔案的名稱與該檔案本身是分開的; 同一個底層檔案(稱為 inode)可以對應到多個名稱,這些名稱被稱為「連結(link)」。 每個連結都是一個目錄項目,該項目包含一個檔案名稱以及對一個 inode 的引用。 inode 存放的是關於該檔案的中繼資料(metadata),包括檔案類型(檔案、目錄或裝置)、檔案長度、檔案在硬碟上的內容位置,以及該檔案被多少個連結所引用
fstat 系統呼叫會從檔案描述符所對應的 inode 中取得資訊。 它會填入一個 struct stat 結構,該結構在 stat.h(kernel/stat.h)中的定義如下:
#define T_DIR 1 // Directory
#define T_FILE 2 // File
#define T_DEVICE 3 // Device
struct stat {
int dev; // File system's disk device
uint ino; // Inode number
short type; // Type of file
short nlink; // Number of links to file
uint64 size; // Size of file in bytes
};link 系統呼叫可以建立另一個檔名,使其指向與現有檔案相同的 inode。 以下這段程式碼會建立一個同時名為 a 與 b 的檔案:
open("a", O_CREATE|O_WRONLY);
link("a", "b");此時讀寫 a 就等同於讀寫 b。 每個 inode 都有唯一的 inode 編號。 在執行完上面這段程式碼後,我們可以透過 fstat 得知 a 和 b 是否指向同一個內容,若是,則它們會回傳相同的 inode 編號(ino),且其 nlink 會是 2
unlink 系統呼叫會從檔案系統中移除一個檔名。 只有當檔案的連結數為零,且沒有任何檔案描述符指向它時,inode 與其硬碟上的內容才會被釋放。 因此若在前段程式碼中加入:
unlink("a");則該檔案的 inode 與內容仍可透過 b 存取。 此外:
fd = open("/tmp/xyz", O_CREATE|O_RDWR);
unlink("/tmp/xyz");是一種慣用的方式,用來建立一個沒有名稱的暫時 inode,當程式關閉 fd 或終止時,該 inode 就會被自動清除
Unix 提供許多可從 shell 呼叫的檔案操作工具,這些工具是使用者層級的程式,例如 mkdir、ln 與 rm。 這樣的設計讓任何人都能透過新增使用者層級的程式來擴充命令列介面。 現在回頭看,這個設計似乎理所當然,但當時的其他系統常常選擇把這些命令內建在 shell 裡,甚至將 shell 內建在 kernel 之中
有一個例外是 cd,它是內建在 shell 裡的。 由於 cd 必須改變 shell 本身的目前工作目錄,如果 cd 是以一般命令執行的,則 shell 會需要建立一個子行程,子行程執行 cd,而 cd 只會改變子行程的工作目錄。 父行程(也就是 shell)的目前目錄將不會受到影響
1.5 Real world
Unix 將「標準」檔案描述子、pipe,以及可用於操作這些機制的 shell 語法結合了起來,這在撰寫通用且可重複使用的程式上是一項重大進展。 這個想法激發了「軟體工具(software tools)」的文化,而這正是 Unix 強大與受歡迎的主因之一,而 shell 也成為了最早的「腳本語言(scripting language)」。 Unix 的系統呼叫介面直到今天也仍持續存在於 BSD、Linux 和 macOS 等系統中
Unix 的系統呼叫介面已透過 Portable Operating System Interface 標準(POSIX)進行標準化。 然而 xv6 並「不」符合 POSIX 規範:它缺少許多系統呼叫(包含像 lseek 這種基本的也沒有),而且它提供的許多系統呼叫與標準不一致
我們設計 xv6 的主要目標是簡單與清晰,同時提供一個簡潔的 UNIX-like 系統呼叫介面。 有些人對 xv6 進行擴充,加入更多的系統呼叫與簡易的 C 函式庫,使其能執行一些基本的 Unix 程式。 然而,現代的 kernel 系統提供比 xv6 多得多的系統呼叫與 kernel 服務,例如支援網路、視窗系統、使用者層級的執行緒、多種裝置的驅動程式等等。 現代 kernel 持續快速演進,並且提供了許多超出 POSIX 規範的功能
Unix 將多種不同類型的資源(檔案、目錄、裝置)透過一組共通的檔案名稱與檔案描述符的介面進行統一的存取。 這個概念其實可以擴展到更多類型的資源; 一個很好的例子是 Plan 9,它將「資源皆為檔案(resources are files)」的理念應用到網路、圖形等更多領域。 不過,大多數基於 Unix 的作業系統並沒有走這條路
檔案系統與檔案描述符一直是非常強大的抽象方式。 然而,作業系統的介面也有其他模型。 Unix 的前身 Multics,將檔案儲存抽象成類似記憶體的形式,這產生出截然不同風格的介面。 Multics 設計上的複雜性直接影響了 Unix 的設計者,使他們立志要打造一個更簡潔的系統
xv6 並沒有提供使用者的概念,也沒有針對使用者間的保護機制; 用 Unix 的術語來說,所有 xv6 的行程都是以 root 身份執行的
本書將探討 xv6 如何實作其類 Unix 的介面,但其中的概念與想法並不限於 Unix。 任何作業系統都必須將多個行程多工(multiplex)到底層硬體上、將行程彼此隔離,並提供受控的行程間通訊機制。 在學習完 xv6 後,你應該能夠理解其他更複雜的作業系統,並在其中辨識出 xv6 所體現的 kernel 概念
1.6 Exercises
- 撰寫一個程式,使用 UNIX 系統呼叫以透過一對 pipe(每個方向一個)在兩個行程之間來回傳遞一個位元組(byte),實現類似「乒乓(ping-pong)」的效果。 以每秒交換次數(exchanges per second)為單位來量測此程式的效能