
The Linux graphics stack in a nutshell 翻譯 & 筆記
The Linux graphics stack in a nutshell 翻譯 & 筆記
原文連結:
我的理解上,整個 big picture 分為兩部分:
- rendering pipeline
- 與一般 graphics API 教學裡面說的 rendering pipeline 不同
- 一般 graphics API 教學裡的 rendering pipeline 是指 GPU 內部(由 OpenGL/Vulkan 規格定義)的圖形管線
- 如:頂點著色器 →(可選 TCS/TES/幾何)→ 光柵化 → 片段著色器 → 測試/混合 → 寫進 framebuffer
- 而這邊指的是應用程式透過 graphics API 一路到生成一塊 framebuffer 的流程
- 流程大概是:App → OpenGL/Vulkan → Mesa(user-space 驅動做著色器編譯/建命令)→ DRM(kernel 驅動提交/排程)→ GPU 執行「上面那條管線/或其他工作」→ 得到一塊 framebuffer
- 一般 graphics API 教學裡的 rendering pipeline 是指 GPU 內部(由 OpenGL/Vulkan 規格定義)的圖形管線
- 流程主要如下:
──────────────────────────── Rendering pipeline ─────────────────────────── 【User space】 App └─ OpenGL / Vulkan calls └─ User-mode GPU driver (Mesa or vendor ICD) ├─ Shader compile/optimize (GLSL/HLSL → SPIR-V → NIR*) *if Mesa ├─ Build device-specific commands ← black box (backend codegen) └─ Submit via libdrm / DRM ioctls (BO handles, command buffers, sync) ※ 由 user-mode driver 經 libdrm 發起提交/同步,App 不直接送 3D ioctls 【Kernel space】 DRM kernel driver (GEM/TTM, drm_sched, dma-fence/syncobj, dma-buf) └─ Schedules work on the GPU └─ GPU executes (the “graphic API” internal rendering pipeline) → writes into a render target / image / BO (pixel buffer)
- 與一般 graphics API 教學裡面說的 rendering pipeline 不同
- display pipeline
- 內含 KMS pipeline(又稱 mode-setting pipeline)
- 流程為:framebuffer → plane → CRTC → encoder →(可能有 bridge)→ connector
- 負責將 framebuffer 的內容輸出到螢幕上
- 流程主要如下:Compositor 那部分也有不經由 Wayland/X11 的作法,改由 graphics API 直接接到 KMS,例如 Vulkan 的
───────────────────── Display pipeline (presentation + KMS) ──────────────────── Presentation boundary(Vulkan:swapchain,OpenGL:前/後臺緩衝 + SwapBuffers/eglSwapBuffers) App acquires a presentable image(Vulkan:swapchain image,OpenGL:back buffer) → renders into it → presents (with sync/fence) └─ Compositor (Wayland) receives the image (often via dma-buf), composites └─ KMS (used by the compositor):atomic page flip / mode setting └─ Display engine:framebuffer → plane → CRTC → encoder → connector → monitorVK_KHR_display/direct-to-display
- 內含 KMS pipeline(又稱 mode-setting pipeline)
將兩者串起來的是「Presentation」這一層:Vulkan 以 swapchain 管理可呈現影像,OpenGL 則是以前/後臺緩衝配合 SwapBuffers/eglSwapBuffers。 一幀的實際時間順序是交錯的(主迴圈裡的多數操作都是非同步),多數應用的程式碼會同時包含「算繪(rendering)」跟「呈現(display/presentation)」兩塊:
- Acquire:App 取得一張「可呈現」的 image(Vulkan 會回傳 swapchain image 索引,通常以 semaphore/fence 同步其可用時機)
- Render into it:App 以「剛拿到的那張 image」做為最終寫入目標去算繪:
- 直接把它當 render pass 的 color attachment 來畫,或先 offscreen 畫到自己的中介貼圖,再 blit/resolve/fullscreen pass 到這張 image
- 這一步由 GPU 寫像素到該 presentable image(Vulkan 的 swapchain image / OpenGL 的 back buffer)
- Submit:App 提交命令到 GPU,等待(例如)
imageAvailable,完成後 signal(例如)renderFinished等同步物件 - Present:
- Wayland/X11 surface:交回 compositor,合成,多數情況對齊 vblank 顯示
- Direct-to-display(如
VK_KHR_display):WSI 走 DRM/KMS 呈現,實作上傾向 atomic commit,legacy 路徑仍可見於部分環境
整個東西還蠻複雜的,這篇文只是給個 big picture,其中的每個部分,像是 DRM、Wayland 等都還能再展開很多篇幅出來,單靠這篇文是無法了解太多細節的,但我認為這篇文還是一篇很優秀的介紹文
註:ICD(Installable Client Driver)為 Vulkan 術語,OpenGL 一般稱 Mesa GL 驅動或專有 GL 驅動
The Linux graphics stack in a nutshell, part 1
當 Linux 圖形開發者談到「現代的 Linux 圖形系統」時,通常指的是多個獨立軟體元件的組合。 它包含了由核心管理的顯示資源、用於合成的 Wayland、加速的 3D 算繪(而非 X11)。 這個系列的兩篇文章會快速地帶你走訪圖形程式碼,看看它是如何把應用程式的資料轉成像素資料並顯示到螢幕上的。 本文這一篇將聚焦於應用程式算繪、Mesa 的內部運作,以及所需的核心功能
Application rendering
圖形輸出從應用程式開始,應用程式會處理並保存要視覺化的格式化資料。 用於視覺化的常見資料結構是「場景圖(scene graph)」:它是一棵樹,其中的每個節點要麼存放三維空間中的模型,要麼存放模型的屬性
模型節點包含要呈現的資料,例如遊戲的場景,或科學模擬的元素; 屬性節點則設定模型的朝向或位置,每個屬性節點都會影響其下方的節點。 為了把場景圖算繪成螢幕上的影像,應用程式會自上而下、由左到右走訪這棵樹,依序設定或清除屬性,並相應地算繪 3D 模型
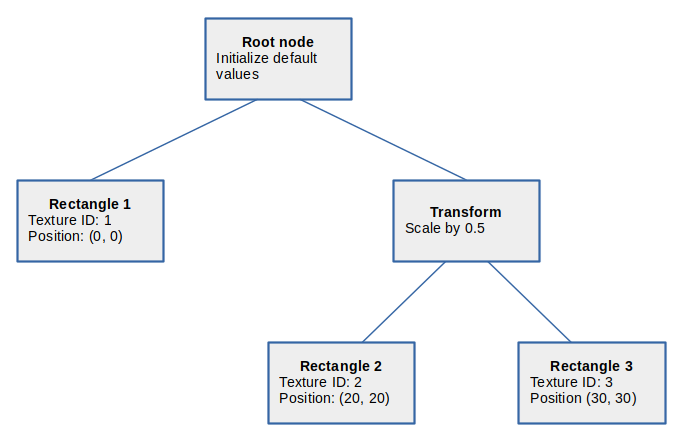
在下方的範例場景圖裡,算繪從根節點開始,根節點會準備算繪器(renderer)並設定輸出位置。 應用程式先走左側分支,在座標
應用程式以 4×4 矩陣描述各種變換(例如定位或縮放),演算法會在算繪過程中套用這些矩陣。 此例中,該變換節點會將其所有子節點等比例縮放為 0.5 倍,因此算繪「Rectangle 2」與「Rectangle 3」時,大小會呈現為原來的一半,位置分別調整為
為了簡化算繪並利用硬體加速,大多數應用程式會使用標準 API,例如 OpenGL 或 Vulkan。 不同 API 的細節各有差異,但它們都會提供介面來管理圖形記憶體、把資料寫入其中,並算繪已保存的資訊。 最終會得到一張影像,應用程式可以直接顯示,或再把它當成輸入做後續處理
所有圖形資料都放在「緩衝物件」裡,每個緩衝物件都是一段附有控制代碼或 ID 的圖形記憶體。 例如,3D 模型會存放在對應的「頂點緩衝物件(vertex-buffer object)」中,紋理會存放在「紋理緩衝物件(texture-buffer object)」中,物件的表面法線也會放在緩衝物件裡,而輸出的影像本身也存放在一個緩衝物件裡。 因此,圖形算繪在很大程度上其實是在做記憶體管理的工作
Tips
在 OpenGL 名稱裡,VBO(Vertex Buffer Object)是常見的頂點資料容器,它只是「緩衝物件」在作為頂點來源時的慣稱。 紋理一般對應到「紋理物件(texture object)」,另有一種稱為 Buffer Texture / Texture Buffer Object(TBO)的機制,讓紋理能直接使用一個緩衝物件作為儲存體、供著色器索引大量資料,因此原文內提到的「紋理緩衝物件」可視為泛指「與紋理相關的(含 TBO 在內的)物件/緩衝」
至於「輸出影像」在實作上可能是附著於 framebuffer 的紋理或 renderbuffer,但要點是一切最終都落在由句柄/控制代碼管理的 GPU 記憶體區塊上,這也是為何圖形程式設計很大一部分在處理資源與記憶體生命週期
只要圖形著色器(shader)能處理,應用程式就可以用任何格式提供輸入資料。 著色器是一種程式,其中包含把輸入資料轉換成輸出影像的指令,它由應用程式提供,並由顯示卡來執行
實際的的著色器程式可能會實作複雜的 multi-pass 演算法,但在此範例中只會介紹必要的部分。 著色器中最常見的兩種操作是頂點變換與紋理查詢。 我們可以把頂點想成多邊形的角。 用 OpenGL Shading Language(GLSL)撰寫時,頂點變換看起來像這樣:
uniform mat4 Matrix; // same for all of a rectangles's vertices
in vec4 inVertexCoord; // contains a different vertex coordinate on each invocation
gl_Position = Matrix * inVertexCoord;變數 inVertexCoord 是來自應用程式場景圖的輸入座標。 變數 gl_Position 則是在應用程式輸出緩衝中的座標。 簡單來說,前者屬於顯示中的場景座標系,後者屬於應用程式視窗內的座標系。 Matrix 是描述這兩個座標系之間的變換的 4×4 矩陣
這段著色器操作會對場景圖中的每個頂點執行一次。 在前述的矩形場景圖例子裡,inVertexCoord 內會含有所有頂點,其中某些矩形的頂點可能會被多次包含在內。 而矩陣 Matrix 會包含這些頂點的變換,例如要如何把它移到正確的位置,或依照變換節點指定的 0.5 比例進行縮放
當頂點被變換到輸出座標系之後,著色器程式會計算被覆蓋的「片段(fragment)」的各種數值,這是圖形領域的術語,指的是一個帶有 Z 軸深度值與其他資訊的輸出像素。 每個片段都需要顏色,在 GLSL 中,可以利用 texture() 函式從紋理取回顏色:
uniform sampler2D Tex; // the texture object of the current rectangle
in vec2 vsTexCoord; // interpolated texture coordinate for the fragment
Color = texture(Tex, vsTexCoord);這裡 Tex 代表一個紋理緩衝(texture buffer)。 vsTexCoord 的值是紋理座標,也就是在紋理中要讀取的位置。 texture() 會回傳一個顏色值,將該顏色值指定給 Color,就能把一個帶顏色的像素寫入輸出緩衝
為了將像素資料填滿輸出緩衝,這段著色器程式碼會對每個片段各執行一次。 正被繪製的模型會指定要使用的紋理緩衝,而紋理座標則由 OpenGL 的內部計算提供。 以上述的場景圖為例,應用程式會對每個矩形各自呼叫這段程式碼,並使用該矩形所對應的紋理緩衝
把這些著色器指令套用到整棵場景圖之後,就能生成應用程式的完整輸出影像了
Mesa
到目前為止我們談到的內容都不是特定於 Linux 的,不過這些內容提供了我們檢視實作方式的框架。 在 Linux 上,Mesa 3D 函式庫(簡稱 Mesa)實作了 3D 算繪的各種介面,並支援多種圖形硬體。 對應用程式來說,它提供了用於桌面圖形的 OpenGL 或 Vulkan、用於行動系統的 OpenGL ES,以及用於計算的 OpenCL。 至於硬體端,Mesa 替當今多數的圖形硬體實作了驅動程式
Mesa 的驅動通常不會自己從零實作這些應用程式介面,因為 Mesa 內建了大量的輔助元件與抽象。 對於像 OpenGL 這類有狀態的介面,Mesa 的 Gallium3D 架構會把介面與驅動彼此連接,這被稱為狀態追蹤器(state tracker)。 Mesa 內含多個 OpenGL、OpenGL ES 與 OpenCL 版本的的狀態追蹤器。 當應用程式使用某個 API 時,它其實是在修改該介面的狀態追蹤器
Mesa 內的硬體驅動還會把狀態追蹤器的資訊進一步轉成硬體狀態與算繪指令。 舉例來說,OpenGL 的 glBindTexture() 會在 OpenGL 的狀態追蹤器中選定當前的紋理緩衝。 接著硬體驅動會把該紋理緩衝物件載入到圖形記憶體,並把啟用中的著色器程式與之連結,讓紋理能參照該緩衝物件。 在我們前面的例子裡,這個紋理就是該著色器程式中的 Tex
Tips
這段在講 OpenGL「設定狀態 → 驅動落地」的流程:glBindTexture() 等呼叫只是在 API 狀態機裡變更「當前紋理」,真正的資源建立與綁定、以及著色器對取樣器/紋理的關聯,會在驅動端被轉譯為硬體可理解的狀態與命令,再送往 GPU。 這種「由 API 狀態映射到硬體狀態」正是 Gallium 與各廠驅動協作的核心
Vulkan 用的是一種「無狀態」的介面,因此 Gallium3D 這類驅動並不適用於它,取而代之地 Mesa 提供了 Vulkan 執行環境(Vulkan runtime)來協助其實作。 如果某硬體已有了 Vulkan 驅動,那它可能就完全不需要基於 Gallium3D 的 OpenGL 支援了
Zink 是一個把 Gallium3D 映射到 Vulkan 的 Mesa 驅動。 有了 Zink,OpenGL 的狀態會轉成 Gallium3D 的狀態,然後再透過標準的 Vulkan 介面轉交給硬體。 原則上,這能與任何硬體的 Vulkan 驅動配合。 可以想見,未來 Mesa 內的驅動可能會只實作 Vulkan,並仰賴 Zink 來提供 OpenGL 相容性
Tips
官方文件把 Vulkan 驅動放在 Mesa 的 Vulkan runtime 之上,以共用的執行期與工具幫助各廠撰寫 Vulkan 驅動。 另一方面,Zink 這個 Gallium 驅動則把 OpenGL(具狀態)映射到 Vulkan(無狀態)呼叫,以便在「只有 Vulkan」的硬體上提供 OpenGL 相容層,詳見 https://docs.mesa3d.org/vulkan/index.html
除了 Gallium3D 之外,Mesa 還為硬體驅動提供了許多輔助元件,例如 winsys 或 GBM。 winsys 用於把視窗系統的細節包裝起來,GBM(Generic Buffer Manager)則簡化了緩衝物件的配置。 應用程式也可以使用多種著色器語言,例如 GLSL 或 SPIR-V。 Mesa 會把應用程式提供的著色器程式碼編譯成「New Intermediate Representation(NIR)」,接著 Mesa 的驅動會再把它轉換為硬體指令。 為了讓 Mesa 的硬體加速處理這些著色器與其相關資料,這些緩衝物件必須存放在顯示卡能存取到的記憶體位置
Tips
winsys 是把裝置無關的 Gallium 驅動連到不同平台(例如 Linux 上的 DRM、Windows 上的 GDI、X11 的 xlib 等)的橋接層。 GBM 是 Mesa 的「通用緩衝管理器」,負責分配/管理可供掃描輸出與算繪使用的緩衝物件
著色器方面,Mesa 會把 GLSL、SPIR-V 等前端經編譯/轉譯後統一變成 New Intermediate Representation(NIR),再由各硬體驅動把 NIR 轉為對應 GPU 的機器/微碼指令。 這些資源必須配置在 GPU 可直接存取的記憶體區域,才能由硬體單元加速處理
Kernel memory management
凡是顯示硬體可存取的記憶體,通常都被統稱為「圖形記憶體」,這是整個圖形軟體堆疊的核心資源,堆疊中的所有元件都會與它互動。 就硬體面而言,圖形記憶體的配置形式有很多種:從獨立顯示卡上的專用記憶體,到系統單晶片(SoC)板上的一般系統記憶體。 介於兩者之間的還包括具有可進行 DMA 的(DMA-able)或共享的圖形記憶體的顯示晶片、獨顯裝置上的 GART(graphics address remapping table)記憶體,以及所謂主機板整合顯示所使用的「stolen graphics memory」
Tips
獨顯常有獨立 VRAM; iGPU/SoC 通常直接使用系統的 RAM; 某些平台會以 GART 做位址重映射,讓裝置以連續位址看見分散的實體頁; 而「stolen memory」指韌體/BIOS 啟動時預留給內顯的一塊系統記憶體。 DMA-able 則強調該區域可被裝置以 DMA 直接讀寫
由於圖形記憶體是全系統範圍的資源,因此由核心的 Direct Rendering Manager(DRM)子系統負責管理。 為了使用 DRM 的功能,Mesa 會開啟 /dev/dri 底下的顯示卡裝置檔,例如 /dev/dri/renderD128。 依據其在 user space 的對應需求,DRM 會以「緩衝物件(buffer object)」的形式對外提供圖形記憶體,每個緩衝物件代表可用記憶體中的一段切片
Tips
DRM 是 Linux 核心負責圖形/顯示與直接算繪的子系統。 /dev/dri 下包含「主要節點」與「render 節點」的裝置檔,Mesa 透過開啟這些節點與 DRM 交握。 對使用者空間而言,最重要的抽象就是「buffer object(BO)」,它是 GPU 可存取的一段記憶體,後續會被著色器、掃描輸出或合成器引用
DRM 框架針對常見情境提供了多種記憶體管理器。 AMD、NVIDIA、以及(即將)Intel 的獨顯 DRM 驅動會使用 Translation Table Manager(TTM)。 TTM 支援獨立圖形記憶體、GART 記憶體與系統記憶體。 TTM 可以在這些區域之間搬移緩衝物件,因此當裝置的獨立記憶體滿載時,未使用的緩衝物件就能被換出到系統記憶體
Tips
TTM 是早期/泛用的圖形記憶體管理層,提供多「記憶體域」之間的置換/遷移能力(例如 VRAM ↔ GART ↔ 系統 RAM),並維護 page 映射與釘住(pin)的狀態。 這種「驅逐/回收」機制讓 VRAM 可聚焦於熱資料,把冷資料暫置於系統 RAM
簡單的 framebuffer 裝置的驅動通常會使用 SHMEM 的輔助元件(helpers),它會在共享記憶體裡配置緩衝物件。 在這裡,一般的系統記憶體會充當該裝置的有限資源的「影子緩衝(shadow buffer)」。 圖形驅動的內部會管理裝置的圖形記憶體,但對外則以位於系統記憶體中的緩衝物件來呈現。 這也讓對 USB 或 I2C 匯流排上的裝置的緩衝物件能被記憶體映射,即便這些匯流排本身不支援裝置記憶體的 page 映射,也能改為映射到影子緩衝來達成
Tips
SHMEM(shared memory)輔助驅動用一般的 RAM 做為後備存儲,對外提供可 mmap 的區塊。 像 USB/I2C 這類週邊匯流排沒有 MMU 風格的裝置記憶體映射能力,因此會以「影子緩衝」的方式把資料放在可映射的系統 RAM,避免直接對裝置記憶體做 page-level 的映射
另一個常見的配置器是 DMA helper,它負責管理實體記憶體中位於可進行 DMA 的區域中的緩衝物件。 這種設計常見於 SoC 板上,圖形晶片會透過 DMA 操作來擷取與儲存資料。 當然,若 DRM 驅動有更多需求,也可以擴充現有的記憶體管理器,或自行實作專用的管理器
Tips
DMA helper 會挑選「DMA-able」的實體頁(例如經過對齊、可連續、具特定屬性的頁),滿足裝置的 DMA 限制。 SoC 常以「一致性/連續性記憶體(如 CMA)」或特定記憶體區段做影像/視訊/顯示的 DMA 來源/目的地。 若硬體對對齊、快取一致性或 IOMMU 有特殊需求,驅動可自訂配置流程
用於管理緩衝物件的 ioctl() 介面稱為 Graphics Execution Manager(GEM)。 每個 DRM 驅動都會依其硬體特性與需求來實作 GEM。 GEM 介面允許把緩衝物件的記憶體 page 映射到 user space 或核心位址空間,並允許把這些 page 釘住(pin)在特定位置,或把它們匯出給其他驅動使用
舉例來說,user space 的應用程式可以對 DRM 裝置檔的 file descriptor 以正確的位移呼叫 mmap(),來取得某個緩衝物件的記憶體 page 存取權。 這個呼叫最終會落到 DRM 驅動的 GEM 程式碼中,由其建立映射。 我們稍後會看到,這對軟體算繪特別有用
唯一一個 GEM 沒有提供的共通操作是「緩衝配置」。 每個緩衝物件都有特定的使用情境,會影響且受限於它的配置參數、記憶體所在位置或硬體限制。 因此,每個 DRM 驅動都會提供專用的 ioctl() 來配置緩衝物件,藉此記錄這些與硬體相關的設定。 Mesa 中對應於該 DRM 驅動的元件就會據此呼叫這個 ioctl()
Tips
GEM 是 DRM 的共通 ioctl 族,處理 BO 的生命週期與映射/釘住/同步等。 常見的還有 dma-buf 的匯出/匯入,讓不同驅動/子系統共享同一塊 BO。 mmap 到 user space 能讓 CPU 直接讀寫 BO(例如軟體光柵器 llvmpipe),而 pin 則確保在 DMA/掃描輸出期間實體頁不會被移動
BO 的「建立/配置」通常是驅動自訂的 ioctl(例如指定大小、對齊、平鋪/壓縮模式、快取屬性、記憶體域、掃描輸出相容性等)。 Mesa 的驅動前端會依用途(像做 render target、texture、scanout)決定參數後,向核心驅動發出建立請求,建立完成再以通用 GEM/dma-buf 介面做映射與共享
Rendering operations
光是擁有用來存放輸出影像、輸入資料與著色器程式的緩衝物件還不夠。 要開始算繪時,Mesa 會指示 DRM 把所有必要的緩衝物件放進圖形記憶體,並啟動目前啟用的著色器程式。 這些流程同樣完全取決於硬體,由各個 DRM 驅動程式分別透過 ioctl() 操作提供。 和緩衝配置一樣,Mesa 內的硬體驅動會呼叫 DRM 驅動的 ioctl() 操作。 對於基於 Gallium3D 的 Mesa 驅動,這一步發生在驅動把狀態追蹤器(state tracker)的資訊轉換成硬體狀態的時候
Tips
實作面上會涉及:將 BO 置入適當的記憶體域(例如 VRAM/系統記憶體)、建立/更新硬體狀態(綁定著色器、紋理、頂點來源等)、提交「繪圖命令」。 Gallium3D 的狀態追蹤器會先彙整 API 狀態,再由硬體特定(HW-specific)的 Mesa 驅動把這些狀態轉成底層 ioctl() 呼叫與命令緩衝(command buffer),交給 DRM 驅動送往 GPU
理想情況下,圖形驅動程式只是充當 user space 的應用程式與硬體之間的代理。 硬體算繪器會與圖形堆疊的其餘部分非同步地運作,只有在發生錯誤或成功完成時才回報給驅動。 有點像系統 CPU 在遇到 page fault 或 illegal instructions 時才會通知作業系統,只要沒有需要回報的事情,驅動的額外負擔就很小
不過也有例外,例如較舊型號的 Intel 圖形晶片不支援頂點變換,因此 Mesa 內的驅動必須以軟體來實作。 在 Raspberry Pi 上,由於 VideoCore 4 晶片沒有 I/O MMU 可將著色器與系統隔離,核心的 DRM 驅動必須驗證每個著色器的記憶體存取
Tips
GPU 一旦接手命令便獨立執行,通常以中斷/訊號回報完成或錯誤,期間驅動維持低開銷。 若硬體某些階段缺失(如早期 GPU 無頂點變換),Mesa 需以軟體補齊。 若缺乏 I/O MMU,著色器可能任意存取系統記憶體,因此驅動需在提交前檢查著色器的存取範圍以確保系統安全
Software rendering
到目前為止,我們都假設有硬體支援圖形算繪。 如果沒有這種支援,或 user space 的應用程式無法使用它,會發生什麼事呢? 例如,對於某個 user space 的 GUI 工具組,由於像 OpenGL 這樣以硬體為中心的介面不符合它的需求,其可能會偏好使用軟體算繪。 還有在開機時顯示開機標誌並提示輸入磁碟加密密碼的程式 Plymouth,它通常無法使用完整的圖形堆疊。 針對這些情境,DRM 提供了 dumb-buffer 的 ioctl() 介面
透過使用 dumb buffer,應用程式會在圖形記憶體中配置緩衝物件,但不具備任何硬體加速的支援,因此回傳的緩衝物件只能用於軟體算繪。 像 GUI 工具組或 Plymouth 這類 user space 的應用程式,會把該緩衝物件的 page 映射到自己的位址空間,然後把輸出影像複製進去
Tips
dumb buffer 通常是線性、可 mmap 的顏色緩衝,沒有平鋪/壓縮與 GPU 特化格式。 CPU 把畫面資料(或由 Mesa 的 llvmpipe/softpipe 產生)寫入其中,再交由顯示路徑取用。 效能有限,但通用性高、依賴少
Mesa 的軟體算繪器也類似:輸入的緩衝物件都位於系統記憶體,由系統 CPU 來處理著色器指令。 輸出緩衝則是用來存放算繪結果影像的 dumb-buffer 物件。 雖然這既不快也不花俏,但對於不支援加速算繪的簡單硬體,已足以跑起現代的桌面環境
至此,我們已經走完應用程式在算繪方面的圖形堆疊了。 在完成場景圖的走訪之後,應用程式的輸出緩衝物件中就包含了它要顯示的視覺化場景或資料,但這個緩衝還沒有被送上螢幕。 不論是加速或 dumb 的路徑,要把緩衝送上螢幕都需要經過合成(compositing)與模式設定(mode-setting),這構成了圖形堆疊的另一半。 在第二部分,我們會談 Wayland 的合成、用 DRM 設定顯示模式,以及圖形堆疊中的其他一些功能
The Linux graphics stack in a nutshell, part 2
要把應用程式的圖形輸出顯示到螢幕上,必須進行合成(compositing)與模式設定(mode-setting),而且要在各個元件之間正確同步,並維持較低的額外開銷。 接下來我們將檢視 Linux 圖形堆疊中的這些元件。 上一章我們沿著圖形流程從應用程式走到了 Mesa,還使用了核心 Direct Rendering Manager(DRM)子系統的記憶體管理功能。 最終我們得到了存放在輸出緩衝(output buffer)中的應用程式圖形資料,現在是時候將這張影像顯示給使用者了
Compositing
user space 的應用程式幾乎不會自己把輸出顯示出來,而是交給螢幕合成器來完成。 合成器(compositor)是一個系統服務,它會接收每個應用程式的輸出緩衝,並把它們繪製成螢幕上的影像。 視窗的配置方式取決於合成器的實作,但最常見的是堆疊(stacking)與平鋪(tiling)。 合成器也負責收集使用者的輸入,並把輸入轉送給目標應用程式
過去,合成以及圖形堆疊中的幾乎所有其他事情,都由 X Window System 提供,X 實作了一種用於把圖形顯示到螢幕上的網路協定。 由於「其他事情」包含繪圖、mode-setting、螢幕分享,甚至列印,X 因此承受了軟體臃腫的問題,也難以因應圖形硬體與 Linux 系統的變化,於是人們便開始尋找一個更輕量的替代方案
它的現代接班人是 Wayland,其同樣採用了 client‑server 的設計,應用程式會作為用戶端,向合成器所提供的顯示服務提出請求。 Wayland 的參考合成器是 Weston,但實務上更常見的是 GNOME 的 Mutter 或 KDE 的 KWin
Wayland 並不提供繪圖或列印,這個協定僅提供合成所需的功能。 Wayland 的 surface 代表一個應用程式視窗,它是應用程式用來顯示其輸出、並從合成器接收輸入事件的介面。 surface 上會附掛一個 Wayland buffer,其中包含可顯示的像素資料,以及顏色格式與尺寸資訊
這些像素資料位於用戶端應用程式先前算繪完成的輸出緩衝中。 當變更某個 surface 所附掛的緩衝物件或其內容時,應用程式會透過 Wayland 協定送出 surface-damage 訊息給合成器,後者據此更新螢幕上的內容,也可能會改用新緩衝物件的內容。 也就是說,應用程式的輸出緩衝會成為 Wayland 合成器的輸入緩衝
Tips
Wayland 把視窗抽象為 surface,把像素載體抽象為 buffer。 應用程式會把已算繪的像素附掛到 surface,並宣告「damage」區域告知哪裡需要重繪。 合成器接到通知後,取用該 buffer(通常為可 zero-copy 共享的 dma-buf),再把它放到合成場景中。 協定不會管要「如何繪圖」,只管「如何交付像素與事件」
合成器中的算繪流程,與第一章介紹的應用程式算繪完全相同。 合成器會維護一份代表應用程式視窗的 Wayland surface 清單。 這些視窗與合成器自身的介面元素,又會形成另一棵場景圖。 背景可以是桌布影像、背景圖樣或顏色,合成器會在背景之上繪製各個應用程式視窗。 實作上最簡單的方式是為每個視窗繪製一個矩形,並將應用程式提供的緩衝區物件當作紋理影像來使用
在應用程式視窗之上,合成器還會繪製它自己的使用者介面,例如讓使用者能與合成器本身互動的工作列。 最後、最上層的是用來目前正在與使用者互動的元素,在桌面系統上通常就是鼠標。 與應用程式一樣,合成器同樣使用一般的 user space 介面進行算繪,例如透過 Mesa 的 OpenGL 或 Vulkan
Tips
合成器會把每個視窗視為一個「貼上紋理的矩形」,用 GPU 將它們依疊放/平鋪與 Z 順序、透明度等參數合成出最終畫面,同時也把自身 UI(面板、鼠標、提示等)納入同一場景圖中。 這讓合成器能沿用與應用程式相同的圖形管線與資源管理模式來完成顯示
讓這一切成真的最後一塊拼圖,是「緩衝物件」的傳輸機制。 與 X 不同,Wayland 應用程式和其合成器會在相同的主機上執行。 因此實作上可以針對這種情況做最佳化:不需要任何網路編碼、緩衝壓縮等額外處理
若要傳輸一個位於系統記憶體中的緩衝物件,應用程式會建立一個指向該緩衝記憶體的檔案描述符,透過連線所使用的串流 socket 傳送出去(只需一則低成本的訊息),並讓合成器把這個檔案描述符所對應的記憶體 page 映射到它自己的位址空間
這樣應用程式與合成器之間就建立了低開銷的像素資料交換通道:應用程式把影像畫進共享記憶區,合成器則從該處取用並進行算繪。 實務上也常同時使用多個緩衝物件做雙緩衝。 Wayland 的 surface-damage 訊息則以低開銷的方式扮演同步機制
Tips
Wayland 以 wl_shm 共享記憶體途徑分享像素:客戶端將一段可共享的記憶體(通常為 memfd 或 shm)作成 wl_buffer,並透過 UNIX domain socket 使用 SCM_RIGHTS 把對應的檔案描述元傳給合成器,合成器 mmap 該 FD 後即可讀取像素。 這種做法避免了複製與網路序列化,且可配合多重緩衝(雙/三緩衝)與 damage 區域更新以降低重繪成
詳見:
對於軟體算繪,透過共享記憶體傳輸資料就足以滿足它了,但因為應用程式必須先在圖形硬體上算繪,然後再透過相對較慢的硬體匯流排把結果回讀到共享記憶體區域,因此這還不能滿足高效能的硬體算繪需求
為了避免上述代價,圖形緩衝必須維持在圖形記憶體中。 Wayland 提供了一個協定的擴充,透過 Linux 的 dma-buf 來共享緩衝物件。 dma-buf 代表了一個可在硬體裝置、驅動與 user-space 程式之間共享的記憶體緩衝
應用程式如同第一部分所述,會透過 Mesa 介面以硬體加速算繪其場景圖,但它不是傳遞指向共享記憶體的參照,而是傳送一個指向該緩衝物件(且仍位於圖形記憶體中)的 dma-buf 物件。 Wayland 合成器可以直接使用其中的像素資料,而無需經由硬體匯流排把資料回讀出來
Tips
linux-dmabuf Wayland 擴充允許客戶端把 GPU 端緩衝以 dma-buf(可跨驅動/裝置的共享 FD)形式交給合成器,這樣像素自始至終都留在「GPU/顯示」可直接存取的記憶體範圍,達成 zero-copy 的傳遞。 dma-buf 是 Linux 核心提供的跨裝置緩衝共享/同步框架,被 DRM/顯示子系統廣泛地使用
詳見:
硬體加速的算繪本質上是非同步的,因此需要同步機制。 當應用程式把本幀最後的算繪命令交送給 Mesa 之後,並不能保證硬體已經完成算繪了。 這是刻意設計、為了高效能所必需的。 但若合成器在硬體完成前就顯示了緩衝物件的內容,輸出就會出現扭曲
為了避免這種狀況,硬體在完成算繪時會發出訊號,這稱為 fencing,對應的資料結構稱為 fence。 這個 fence 會附加在應用程式傳給合成器的 dma-buf 物件上。 合成器會等到該 fence 發出完成訊號後,才使用結果資料來產生自己的輸出
Tips
在 Linux 圖形堆疊裡,這類同步通常以 dma-fence(或透過 DRM syncobj 等機制)來實作:fence 物件附著在共享的 dma-buf 上,表示「當 GPU 完成對此緩衝的寫入時會發出訊號」。 Wayland 也有明確同步的協定擴充,讓客戶端把相關的 fence/同步點隨同緩衝一併傳遞給合成器,確保在正確時機取用像素,避免撕裂/閃爍/破圖
Pixels to the monitor
在把螢幕上的影像算繪出來之後,合成器必須把它顯示給使用者看。 DRM 的 mode-setting 程式碼負責控制從圖形記憶體讀取像素資料並將其送往輸出裝置的所有面向。 為了達成這件事,每個驅動程式都會建立一條管線(pipeline),用來描述像素資料在圖形硬體中的流動。 管線中的每個階段都對應到一段硬體功能,負責在資料前往顯示器的途中處理像素資料
必要的階段包括 framebuffer、plane、CRTC、encoder 與 connector,下面會分別加以說明。 要讓顯示輸出正常運作,這些階段之中每一個至少都要有一個啟用中的實例。 不過,大多數硬體提供的功能都能滿足最低需求,並允許視需要啟用或停用管線中的各階段。 DRM 架構為每一個階段都提供了軟體抽象,讓驅動程式可以在其上實作
Tips
KMS 對使用者空間呈現的核心物件就是這五種:framebuffer → plane → CRTC → encoder → connector。 一般至少各有一個,較進階的硬體可有多個 plane、CRTC 等,支援多螢幕、Overlay、鼠標等用途。 這些抽象由 DRM/KMS 統一定義,驅動依硬體能力去對應
詳見:
這條管線的第一個階段是 DRM 的 framebuffer。 它是一個緩衝物件,裡面存放了合成器產生的螢幕影像,並帶有影像的色彩格式與尺寸等資訊。 每個 DRM 驅動會用這些資訊去設定硬體,並把硬體的指標指向該緩衝物件的起始位元組,讓硬體知道到哪裏去取得像素資料
抓取像素資料這件事稱為 scanout,而承載像素資料的緩衝物件則稱為 scanout buffer。 每個 framebuffer 需要用到的 scanout buffer 數量取決於該 framebuffer 的色彩格式,許多格式(例如常見的 RGB 類型)會把所有像素資料都放在單一緩衝裡,而像 YUV 這類格式則可能需要把像素資料拆成多個緩衝
Tips
framebuffer 是被 scanout 讀取的像素來源,它同時攜帶像素格式、寬高等屬性。 驅動會將這些屬性寫入對應暫存器,並提供記憶體起始位址,硬體據此讀取像素
依硬體能力而定,framebuffer 可以比輸出的顯示模式更大或更小。 舉例來說,假設顯示器設定為 1920×1080 像素,如果 framebuffer 大於顯示模式,則顯示器上可能只會顯示該 framebuffer 內的某個區域; 反之,若 framebuffer 小於顯示模式,則它可能只會覆蓋顯示器上的一小塊,其他區域則留白
因此,管線的下一階段會在整體畫面中定位這個 scanout buffer。 在 DRM 術語裡,這個階段稱為 plane,它負責設定該 scanout buffer 的位置、方向與縮放參數。 視硬體而定,系統可能會有多個使用不同 framebuffer 的 plane。 所有啟用中的 plane 都會把它們的像素輸出送往管線的第三階段,因歷史因素該階段被稱為 CRTC(cathode-ray tube controller)
CRTC 負責所有與顯示模式的設定相關的事項。 DRM 驅動會以某個顯示模式來設定(program)CRTC 的硬體,並將它與所有啟用中的 plane 及輸出端相連。 系統也可以同時存在多個設定各異的 CRTC,具體配置僅受限於硬體特性
各個 plane 會以疊放的方式排列,因此它們可以彼此重疊,或覆蓋輸出畫面的不同區域。 依據已設定的顯示模式與各 plane 的位置,CRTC 硬體會從這些 plane 取出像素資料,在需要時對重疊的 plane 進行混合,然後把結果傳遞到其輸出端
Tips
plane 讓一個或多個來源緩衝被定位、縮放、(必要時)旋轉到目標畫面中。 最基本的有主平面(primary)、鼠標平面(cursor),不少硬體還有 overlay 平面。 多個 plane 的像素會彙入 CRTC 做最後的合成/時序輸出。 CRTC 抽象的是掃描輸出的引擎與影像時序的產生
plane 可視為可定位/縮放/(必要時)混合的圖層。 CRTC 依 plane 的座標與優先序(疊放順序)決定在每個掃描位置取哪個 plane 的像素,若開啟透明度或色鍵等功能,會做硬體混合(blending),最後再把合成後的像素流送往後續輸出
輸出端由 encoder 與 connector 這兩種物件表示。 顧名思義,encoder 是把像素資料編碼成特定輸出訊號的硬體元件。 某個 encoder 會關聯到一個特定的 connector,後者代表與輸出裝置之間的實體連結,例如接了螢幕的 HDMI 或 VGA 連接埠。 connector 也會提供輸出裝置支援的顯示模式、實體解析度、色彩空間等資訊。 掛在同一個 CRTC 上的多個輸出端,會在不同的輸出裝置上鏡像顯示同一個 CRTC 的畫面
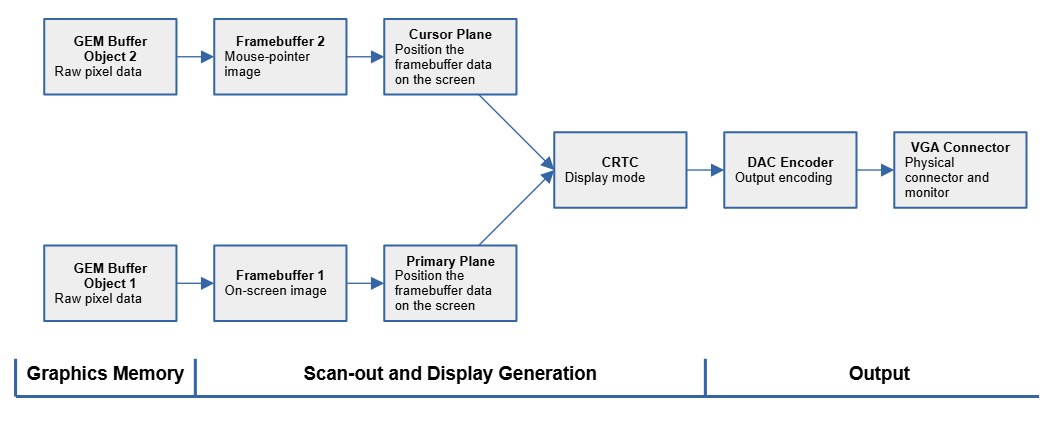
下圖示範了一條簡單的 mode-setting 管線,除了主畫面之外,還有一個專用於鼠標的 plane,以及作為 scanout buffers 的緩衝物件。 圖中的箭頭顯示了像素資料從緩衝物件一路流向 VGA connector 的邏輯流程,這是針對較舊的獨立顯示卡的一種典型的 mode-setting 管線
Tips
典型的配置包含:主 framebuffer/plane(桌面內容)、cursor plane(硬體指標,低延遲且不需重複重繪整個畫面)、CRTC(時序/掃描)、encoder(轉為 VGA/HDMI/DP 等訊號)與 connector(實體埠)。 scanout buffer 指的是被掃描輸出單元直接讀取的像素緩衝,圖示強調了資料沿著 KMS 管線的方向性與分工
Pipeline setup
DRM 驅動並不負責決定連接與配置 mode-setting 管線中各個階段的策略,這件事會交由 user space 的程式處理,也就是回到合成器(compositor)的部分。 作為其初始設定的一部分,合成器會開啟 /dev/dri 底下的裝置檔(例如 /dev/dri/card1),並呼叫對應的 ioctl() 來設定顯示管線。 它也會自某個 connector 取得可用的顯示模式,並挑選一個合適的模式
Tips
KMS 採「使用者空間決策、核心驅動執行」的分工:合成器透過 libdrm/ioctl() 取得硬體能力、EDID 與模式列表,選定模式後再下發設定。 這讓不同桌面環境(Mutter/KWin/Weston 等)能以一致方式控制顯示輸出
當合成器算繪出第一張螢幕影像後,會首次對 mode-setting 管線進行設定。 為此它會為螢幕畫面的緩衝物件建立一個 framebuffer,並把該 framebuffer 附加到某個 plane,接著在 CRTC 上為其螢幕緩衝的顯示模式進行設定,再將從 framebuffer 到 connector 的所有管線階段串接起來,最後啟用顯示
Tips
這是「第一次亮屏」所需的最小步驟集合:把「像素來源(framebuffer/scanout buffer)」定位到畫面(plane),再由 CRTC 套用時序與模式,最後透過 encoder/connector 輸出到實體介面
要在下一幀更換顯示影像,無需進行完整的 mode-setting 流程,合成器只要把當前的 framebuffer 換成新的即可。 這稱為 page flipping。 mode-setting 管線中的各個階段可以用多種方式連接:一個 CRTC 可能會鏡像到多個 encoder,或是一個 framebuffer 可能會同時被多個 CRTC 掃描輸出。 雖然這提供了彈性,但也表示並非所有階段組合都受支援
Tips
硬體資源(CRTC/plane/encoder 的數量與配對關係)決定可行拓樸,某些連線僅支援特定 encoder,或 plane 僅能被特定 CRTC 使用。 合成器需依據驅動回報能力挑選可行的連線方案
一個較粗糙(naive)的實作會逐一套用每個階段的設定:先在 CRTC 設定顯示模式,接著把所有緩衝物件上傳到圖形記憶體,然後設定用於掃描輸出的 framebuffer 與 plane,最後啟用 encoder 與 connector。 若在這個過程中有任何一步失敗,螢幕就會保持黑屏,或(更糟)處於畫面失真狀態
舉例來說,在裝置記憶體有限的情況下,可能無法同時容納多個 plane 所需的 framebuffer,因此模式的切換,甚至只做簡單的 page flip,都可能失敗。 自古以來,顯示更新失敗一直是圖形堆疊的常見問題
DRM 的「原子化模式設定(atomic mode setting)」在某種程度上解決了這個問題。 模式設定的程式碼會把管線中所有元素的完整狀態,追蹤在一個名為 drm_atomic_state 的複合資料結構中,並為管線中的每個階段維護一個對應的子狀態。 所謂的「原子化」,指的是它要麼一次套用所有管線階段的完整複合狀態,要麼完全不套用。 為了達成這件事,mode-setting 分為兩個階段:首先檢查(check)整個新的原子狀態,若檢查成功,接著再提交(commit)相同的狀態上去
在檢查階段,DRM core、其輔助程式,以及各 DRM 驅動會把所提議的狀態,拿去與可用圖形硬體的限制與約束進行比對。 舉例來說,某個 plane 必須驗證其所附加的 framebuffer 是否為相容的色彩格式,而 CRTC 則必須驗證所給定的顯示解析度是否受硬體支援。 若檢查成功,DRM 驅動會在 commit 階段把新狀態設定(program)到硬體上。 若其中任何一個階段的狀態檢查失敗,DRM 便會停止 mode-setting 作業,並把錯誤回傳給 user space 的程式
因此,當合成器要設定某個顯示模式時,會一次性地設定整條管線中各階段的 atomic state,並一併套用。 若成功,顯示輸出就會相應更新。 對於連續的 page flipping 操作,合成器會先複製目前的狀態,把其中的 framebuffer 換成新的,然後套用這份新狀態。 再次進行 page flipping 時,核心的 DRM 程式碼仍會走一遍 atomic check/atomic commit 的流程,但其開銷會比完整的 mode-setting 小很多
DRM 的狀態檢查階段獨立於硬體的當前狀態,且不會修改它。 若某個 atomic 狀態的檢查失敗,合成器會收到錯誤碼,但顯示輸出保持不變。 合成器也可以只做驗證而不提交,藉此事先彙整出一份受支援的組態清單。 想進一步閱讀的話,LWN 在 2015 年已對 atomic mode setting 的內部運作做過詳細介紹了,見 part 1 與 part 2
Tips
「檢查不改動」確保了可預先探測:合成器能離線地嘗試各種組合(解析度、plane 佈局、格式等),建立白名單,實際切換時只提交已知可行的原子狀態,降低黑屏或花屏風險
Additional features
在先前討論 plane 時,我們假設所有硬體上的 plane 都是相同的,但這其實不一定是對的。 通常會有一個稱為 primary plane 的平面用於類 RGB 的色彩格式,且覆蓋整個顯示畫面。 合成器會設定 primary plane 來顯示它的螢幕影像
但多數硬體還會提供一個額外的鼠標用平面,稱為 cursor plane。 這個平面只會覆蓋一小塊區域,並位於 primary plane 之上。 顧名思義,合成器使用 cursor plane 來顯示滑鼠指標影像,因此能在不改變 primary plane 的情況下自由移動該指標
位於 primary 與 cursor plane 之間的是 overlay planes,它們大小各異,且常支援類 YUV 的色彩格式。 這讓它很適合用較低的 CPU 開銷來顯示影像資料串流。 因此,通常影像播放器應用程式會提供含有 YUV 基礎像素資料的緩衝物件給合成器
合成器會用該像素資料建立一個 framebuffer 並配置給 overlay plane。 此平面會在硬體中掃描 YUV 的像素資料,並將其轉換為 RGB 的色彩。 透過 dma-buf,影像播放器可以把硬體影像解碼器產生的各個 YUV 幀直接轉交給合成器,讓整個影像處理都交由硬體完成
若顯示更新的延遲為關鍵考量,將 mode-setting 能力直接交給單一應用程式會更有幫助。 為此,合成器會把該功能出租(lease)給應用程式。 當某個應用持有有效的 DRM lease 時,它便能完全控制整條 mode-setting 管線。 這對需要嚴格協調其內建顯示器的輸出頻率與延遲、以維持 3D 幻覺效果的 3D 頭戴式裝置特別有用。 DRM lease 的租約可能會到期或被撤銷,因此最終 mode-setting 的主控權仍在合成器手上
雖然現代合成器使用 Wayland 作為協定,但 X Window System 的應用程式還是很常見。 Xwayland 是在 Wayland 工作階段中執行的 X 伺服器,它透過在 Wayland 與 X 協定之間做轉譯,讓 X 應用程式得以透明地參與 Wayland 工作階段。 大多數的使用情境而言,這種方式是可行的,但還是有些例外
例如 Xwayland 無法模擬螢幕擷取與螢幕分享。 X 應用可以存取 X 工作階段的整棵視窗樹,因此很容易進行螢幕擷取。 基於安全考量,Wayland 協定不允許應用程式讀取整個螢幕或其他應用程式的視窗。 於是 Wayland 合成器會提供專門的實作來擷取或分享螢幕內容,常見實作包含 PipeWire、VNC 或 RDP
若沒有在執行的合成器,Linux 會顯示文字主控台。 DRM 能支援核心的 framebuffer 主控台來輸出文字,這個 DRM 的 fbdev 模擬就像一個 user space 的 DRM 用戶端,但它完全在核心中執行。 它也提供舊式的 framebuffer 介面,例如 /dev/fb0。 不過,fbdev 與 DRM 的 fbdev 相容層正走向退場,目前已有把大量主控台功能搬到 user space 的構想
在本文撰寫之時,Linux 圖形領域快速發展的一個主題是 HDR(High Dynamic Range)算繪。 它能以更細膩的色彩與光照呈現輸出,因而顯示出以傳統算繪常被喪失的細節。 對 HDR 的支援將使 Linux 能滿足專業圖形藝術家的需求。 當前支援仍不一致,但在遊戲中已可使用 HDR,而各種 Linux 桌面也開始實作 HDR 了
至此,我們已沿著現代 Linux 圖形堆疊把應用程式內容送上螢幕 —— 從算繪與記憶體管理,到合成與模式設定。 不過這其實只是淺嘗輒止,這個堆疊仍在不斷演進,持續加入對新功能與新硬體的支援