(WIP)台大 SP 筆記
台大 SP 筆記
大部分是用 GPT 整理的就是了,簡單修一下而已,有些自己沒看很懂得地方拿了課本的段落來做了翻譯。 只是自用筆記,想好好學的人去上課或是讀 TLPI 吧XD
課本是《 Advanced Programming in the UNIX Environment, 3/e》這本
File IO
buffered v.s. unbuffered I/O
buffered I/O 跟 unbuffered I/O 的差別主要在資料處理流程中是否經過額外的快取區 (buffer)
Buffered I/O (緩衝 I/O)
- 流程:
程式要寫資料時,先寫入到記憶體中的 buffer (快取區),等 buffer 滿了或被強制 flush 時,才一次性寫到裝置 (像硬碟或網路)。 讀取時則會先把一大塊資料讀進 buffer,程式從 buffer 取資料 - 特點:
- 系統呼叫 (syscall) 次數少 → 效能較高
- 適合大量小資料的存取,因為可以合併操作
- 需要額外的記憶體來做 buffer
- 可能有延遲:寫入後不一定馬上到達裝置,若程式 crash 或斷電,資料可能還沒 flush
- 例子:
- C 語言的
fopen()/fread()/fwrite()(標準 I/O library),就是 buffered I/O - Linux shell 的
cat file,實際是經過 libc 的 buffer
- C 語言的
- 流程:
Unbuffered I/O (非緩衝 I/O)
- 流程:
每次read()或write()系統呼叫,程式資料直接和作業系統核心的 I/O 子系統交互,通常會直達裝置 driver - 特點:
- 每次操作都要進行 syscall,效能可能較差
- 但動作是立即的,不會延遲
- 適合需要確定資料馬上寫出的場合 (例如 log、即時系統)
- 沒有額外 buffer,因此行為比較「可預測」
- 例子:
- Unix/Linux 的
read()/write()系統呼叫就是 unbuffered I/O - C 語言
open()搭配read()/write()
- Unix/Linux 的
- 流程:
File I/O & File Descriptors
1. 當程式對檔案做操作時會發生什麼?
當一個 process (行程) 執行 open, read, write 等檔案操作時,背後涉及:
- 磁碟上的資料 (on-disk data)
- 檔案的實際內容 (file contents)
- 檔案的 metadata (中繼資料),例如:
- 檔案權限 (permissions)
- 檔案實際在磁碟上的位置 (disk blocks)
- 其他資訊 (e.g., 時間戳、owner、link count 等,課堂後續會再深入)
也就是說,檔案不只包含了「內容」,還包含「描述內容的資料」
2. 在 Unix 中的檔案存取規則
- 必須先
open():
在 Unix 系統中,行程必須先打開檔案,才能進行讀寫 - 同一 process 可多次開啟同一檔案
例如:open("foo.txt")兩次,會得到兩個獨立的 file descriptor - 多個 process 可以同時開啟同一檔案
因此 OS 核心 (kernel) 需要追蹤每個 process 與檔案的關聯
重點:kernel 必須維護一份資料結構,記錄「哪個行程、透過哪個 file descriptor,正使用哪個檔案」
3. File Descriptor (檔案描述符)
- 定義:
在 Unix 中,kernel 以 file descriptor (FD) 來表示一個「已開啟的檔案」 - 特性:
- file descriptor 是一個非負整數
- 範圍:
0 ~ OPEN_MAX-1OPEN_MAX表示一個 process 最多能同時開啟多少檔案
- per-process:
每個行程都有自己獨立的 FD table,因此兩個 process 可能擁有相同數字的 FD,但指向不同的檔案
- 例子:
Process A 的 fd=3 可能是a.txt,Process B 的 fd=3 可能是b.txt,因為它們的 FD table 各自獨立
4. 標準檔案描述符 (Standard File Descriptors)
對於每個 process 的 file descriptor table 而言,Unix 約定俗成地將 0, 1, 2 綁定到了三個特殊的檔案:
0→ 標準輸入 (stdin)1→ 標準輸出 (stdout)2→ 標準錯誤 (stderr)
這些數字對應到 POSIX.1 標準定義的常數:
STDIN_FILENO(0)STDOUT_FILENO(1)STDERR_FILENO(2)
這些常數定義在 <unistd.h> 標頭檔中
底下這個例子會「把標準輸入複製到標準輸出」,就像精簡版的 cat 命令(但用的是 unbuffered I/O 的 read/write,不是 fread/fwrite):
#include <unistd.h>
int main(void)
{
char buf[100];
ssize_t n;
while ((n = read(STDIN_FILENO, buf, 100)) != 0)
write(STDOUT_FILENO, buf, n);
return 0;
}read(STDIN_FILENO, buf, 100):從 fd=0(stdin) 讀最多 100 bytes 到buf,回傳讀到的實際位元組數nn > 0:讀到資料n == 0:EOF(輸入結束)n == -1:錯誤(需看errno)
write(STDOUT_FILENO, buf, n):把剛讀到的nbytes 寫到 fd=1(stdout)- 迴圈:重複讀→寫,直到
read()回傳 0(EOF)
File I/O:open、openat & close
#include <fcntl.h>
int open(const char *path, int oflag, ... /* mode_t mode */);
int openat(int fd, const char *path, int oflag, ... /* mode_t mode */);- 一個 process 可以透過
open或openat來開啟或建立檔案 - 成功時會回傳「file descriptor」,失敗時回傳 -1
- 回傳的 file descriptor 會是當前 process 尚未使用的最小編號
open()
open() 的參數
path:欲開啟或建立檔案的路徑,可以是「絕對路徑」或「相對路徑」oflag:指定檔案的存取模式與其他旗標
oflag 存取模式(三選一)
O_RDONLY:只讀O_WRONLY:只寫O_RDWR:讀寫
oflag 的額外旗標(可用 OR 組合)
O_APPEND:每次寫入時自動附加在檔尾O_TRUNC:開啟檔案時將大小截斷為 0O_CREAT:若檔案不存在就建立它O_NONBLOCK:非阻塞模式O_SYNC/O_DSYNC/O_RSYNC:同步 I/O,確保資料或 metadata 寫入完成
open() 與 mode
#include <fcntl.h>
int open(const char *path, flag | O_CREAT, mode_t mode);- 當指定「
O_CREAT」時,必須額外提供「mode」參數 mode指定新建檔案的權限mode會與「umask」結合:任何在umask中設定的 bit,會被清除- 例子:
umask=0x22- 新建檔案時
mode=0x777 - 最終檔案權限為
0x755
mode常數(檔案權限)S_IRWXU:00700,使用者有讀、寫、執行權限S_IRUSR:00400,使用者有讀權限S_IWUSR:00200,使用者有寫權限S_IXUSR:00100,使用者有執行權限S_IRWXG:00070,群組有讀、寫、執行權限S_IRGRP:00040,群組有讀權限S_IWGRP:00020,群組有寫權限S_IXGRP:00010,群組有執行權限S_IRWXO:00007,其他人有讀、寫、執行權限S_IROTH:00004,其他人有讀權限S_IWOTH:00002,其他人有寫權限S_IXOTH:00001,其他人有執行權限
好的,我幫你整理成一份筆記,符合你指定的格式(中文與英文之間加一個空白,括號用中文大寫括號)
openat()
openat()和open()的行為幾乎相同,不同之處在於參數fd與path的組合如果
path是「絕對路徑」,參數fd會被忽略如果
path是「相對路徑」:- 若
fd為AT_FDCWD,則path會以「目前工作目錄」為基準解譯 - 若
fd指向一個已開啟的目錄,則path會以該目錄為基準解譯
- 若
例子:
int dirfd = open("..", O_RDONLY); int fd = openat(dirfd, "test", O_RDWR | O_CREAT);等價於
int fd = openat(AT_FDCWD, "../test", O_RDWR | O_CREAT);openat()支援相對於某個已開啟目錄的檔案開啟open()只能支援相對於「目前工作目錄」的檔案開啟open()因為固定依賴當前工作目錄,容易受到「TOCTTOU 攻擊」(Time Of Check To Time Of Use)。 這是一種競態條件攻擊,後面會在介紹 symbolic links 後再深入探討
close()
#include <fcntl.h>
// 成功回傳 0,錯誤回傳 -1
int close(int fd);- 呼叫
close即可關閉一個已開啟的檔案 - 當一個 process 終止時,kernel 會自動關閉它所有已開啟的檔案
- 許多程式因此不會顯式地呼叫
close,而是依賴 process 終止時自動關閉
File I/O:creat
#include <fcntl.h>
// 成功時回傳一個 file descriptor,失敗時回傳 -1
int creat(const char *path, mode_t mode);- 呼叫
creat會建立一個檔案,並且以 write-only 模式開啟 - 這個函式功能與
open重疊 open(path, O_WRONLY | O_CREAT | O_TRUNC, mode)等價於creat(path, mode)- 因為功能重複,
creat現在幾乎已經過時 - 問題:如果要「建立並以 read-write 模式開啟檔案」怎麼辦?
creat不支援讀寫開啟,正解是:open(path, O_RDWR | O_CREAT | O_TRUNC, mode)
O_TRUNC標誌的行為- 如果檔案已存在,且是「一般檔案」,而且存取模式允許寫入 (
O_RDWR或O_WRONLY),則檔案大小會被截斷為 0 - 如果檔案是 FIFO 或終端機裝置檔,
O_TRUNC會被忽略 - 其他情況下,
O_TRUNC的行為未定義
- 如果檔案已存在,且是「一般檔案」,而且存取模式允許寫入 (
Unix Kernel 對 File I/O 的支援
Unix 核心在管理一個開啟的檔案時,使用三種資料結構。 它們之間的關係會影響多個 process 共享檔案時的行為:
- Open file descriptor table(每個 process 各自擁有)
- Open file table(整個系統共享)
- V-node table(整個系統共享)
Open file descriptor tabl
- 每個 process 有一張自己的表
- 每個 entry 對應一個 file descriptor
- entry 內容:
- file descriptor flag(例如 close-on-exec 等,之後會介紹)
- 指向「open file table」中某一項的指標
Open file table
- 每個開啟的檔案在系統中會有一個 entry
- 每個 entry 的內容包含:
- file status flag(例如 readable/writable/append/sync/nonblocking)
- 檔案目前的 offset(檔案指標位置)
- 指向「v-node table」中某一項的指標
V-node(i-node)table
- 每個 entry 代表一個 v-node(虛擬節點結構)
- v-node 內容包含:
- 指向對應 i-node 的指標
- v-node 資訊(檔案類型,以及操作檔案所需的函式指標)
V-node 與 I-node 的區別
- V-node
- 是一種「記憶體中的結構」,用來抽象化不同檔案系統
- 儲存檔案類型,以及操作檔案的函式指標
- 發明目的是讓單一電腦能同時支援多種檔案系統
- I-node
- 同時存在於磁碟與記憶體中
- 包含檔案的 metadata:
- 檔案擁有者
- 檔案大小
- 檔案所屬裝置
- 權限資訊
- 資料區塊在磁碟上的位置
- 當檔案被打開時,作業系統會把對應的 i-node 從磁碟載入到記憶體,方便之後的操作
- 早期 Unix 使用 v-node 概念,讓不同檔案系統有統一的接口
- Linux 本身並沒有獨立的 v-node,取而代之使用 generic i-node,概念上等同於 v-node
Big picture
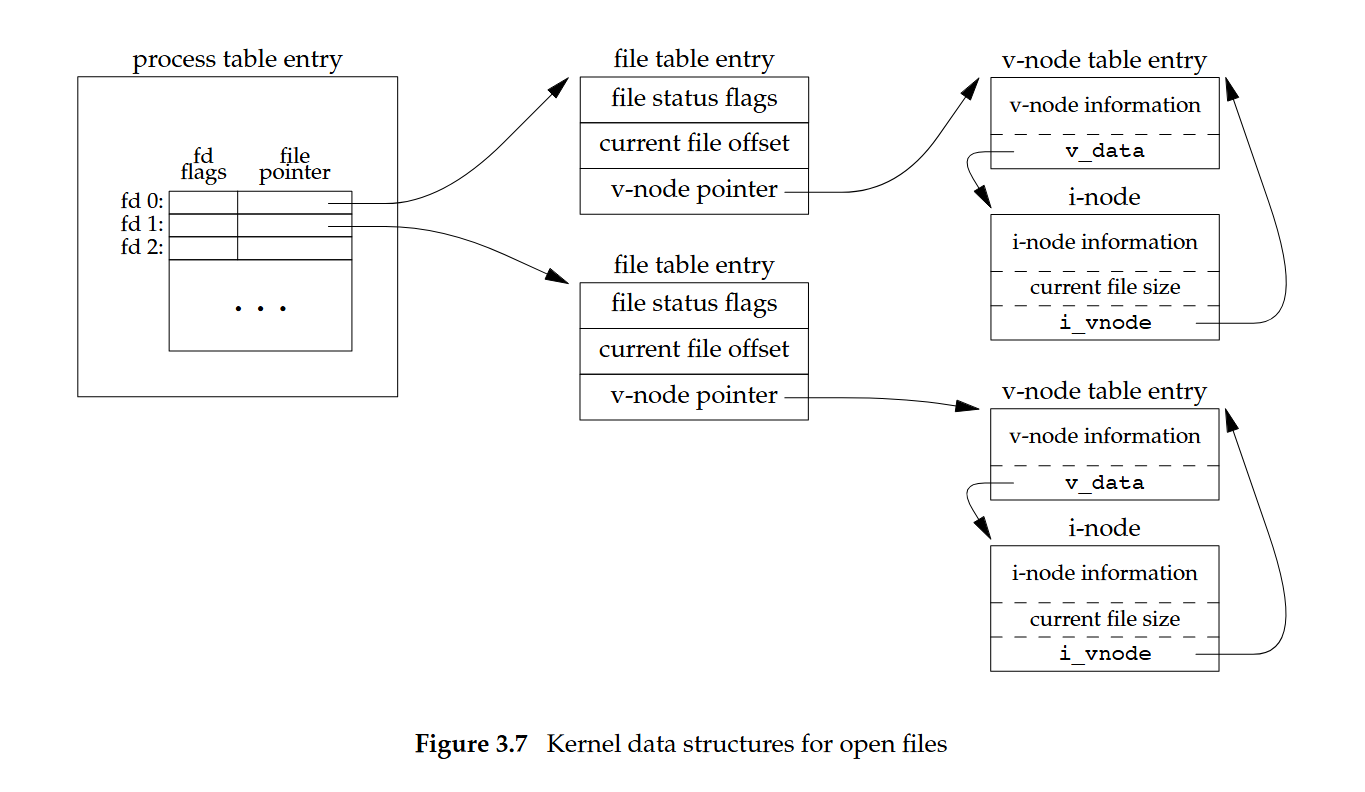
上圖中可見:
- 每個 process 有自己的「open file descriptor table」,表格裡每一列對應一個 fd(例如 0、1、2…),包含「fd flags」與一個指向「open file table entry」的指標
- 「open file table」(全系統共享)的一個 entry 代表一次「open」動作的結果,保存:
- file status flags(可讀/可寫/append/sync/nonblocking…)
- current file offset(檔案位移點)
- 指向「v-node table entry」的指標
- 「v-node table entry」封裝檔案系統無關的抽象,內含 v-node information 與 v_data,並連到對應的 i-node
- 「i-node」保存檔案的 metadata(owner、size、權限、資料區塊位置…)與目前檔案大小,以及回指到 vnode(實作上視系統而定)
- 讀圖要點:
- process 的 fd 並不直接指向 i-node,而是經由「open file table」再到「v-node/i-node」
- 同一個 process 可以同時擁有多個 fd,各自指向不同的「open file table entry」,而這些 entry 最終可能指向相同的檔案(相同 v-node/i-node)
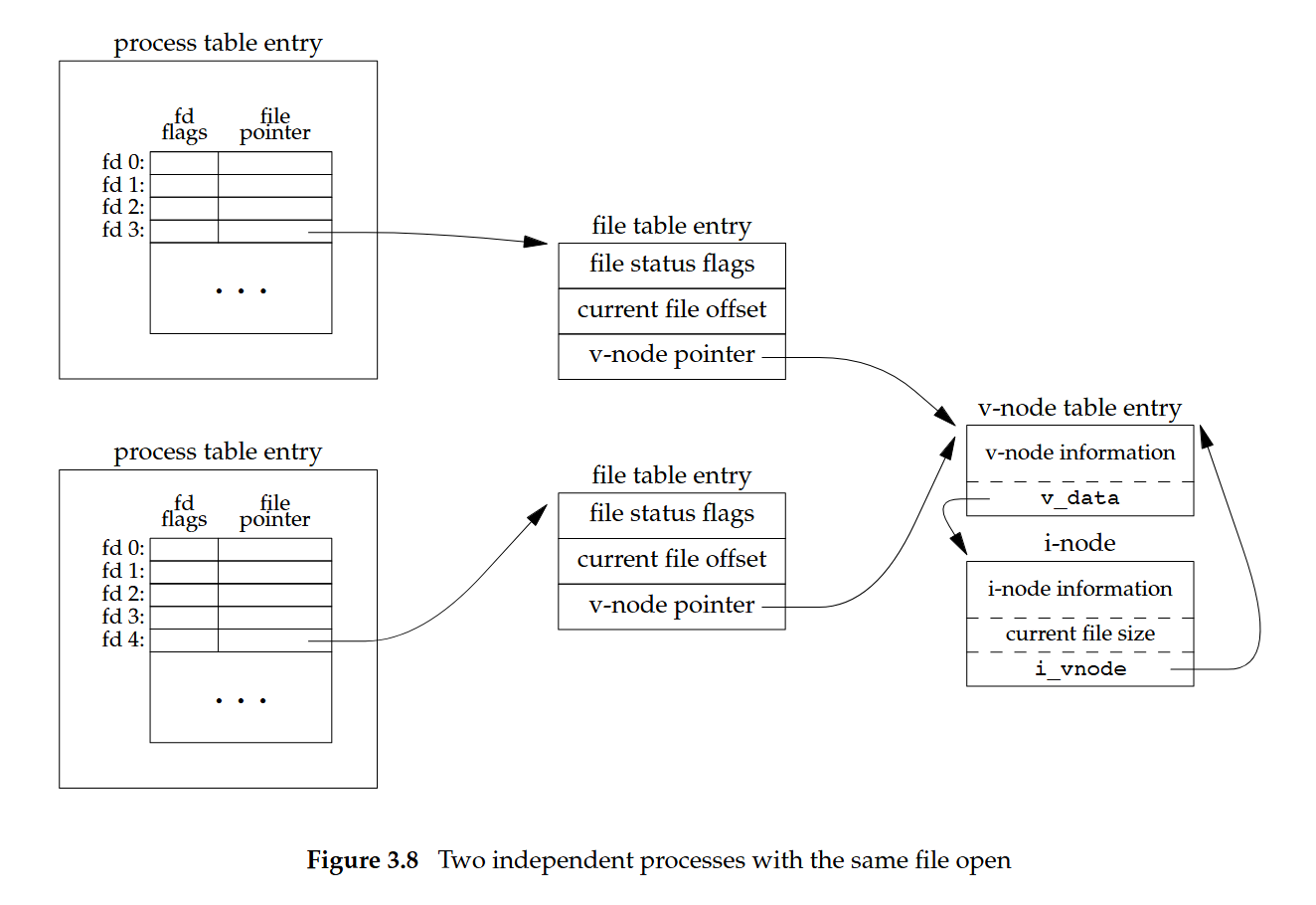
上圖中可見:
- 兩個互不相關的 processes 分別對同一個檔案呼叫一次
open時,情況如下:- 每個 process 的 fd 指向「自己的」open file table entry(彼此不同)
- 兩個 open file table entries 最終都指向「同一個」v-node/i-node(因為是同一個檔案)
- 重要影響:
- 因為 open file table entry 不同,「current file offset」是各自獨立的。 A 讀了 100 bytes 不會改變 B 的 offset
- 「file status flags」也各自獨立。 A 可以用
O_RDONLY開啟,B 可以用O_RDWR - 底層檔案內容與大小由同一個 i-node 代表,所以任一方寫入會改變同一份檔案的內容與可能的大小(另一方之後讀到的資料會反映更新)
一些小整理:
- 若是同一個 process 對同一個 fd 做
dup(或fork之後尚未exec,父子繼承相同 open),會讓多個 fd 指向「同一個」open file table entry,這種情況下「file offset」是共享的。 圖二展示的是「兩次獨立的 open」,所以 offset 不共享 - fd(per-process)→ open file table(per-open)→ v-node/i-node(per-file)
- 是否「共享 offset/status flags」取決於兩個 fd 是否指向同一個「open file table entry」:
- 同一個 entry(例如
dup、fork後未重新open):共享 offset/status - 不同 entry(兩次獨立
open):offset/status 各自獨立,但指向同一 v-node/i-node,因此共享檔案內容
- 同一個 entry(例如
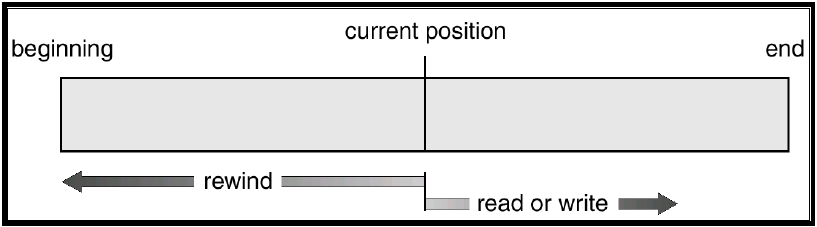
File Offset
- 在 Unix,每個「已開啟的檔案」都會有一個「當前 file offset」
- 這個 offset 是一個整數,表示從檔案開頭到目前為止已經存取的位元組數
- 在大部分情況下,offset 的值是正的,但某些裝置可能允許負的 offset
- 當檔案被開啟時,offset 會初始化為 0,除非在
open()的參數oflag中指定了O_APPEND
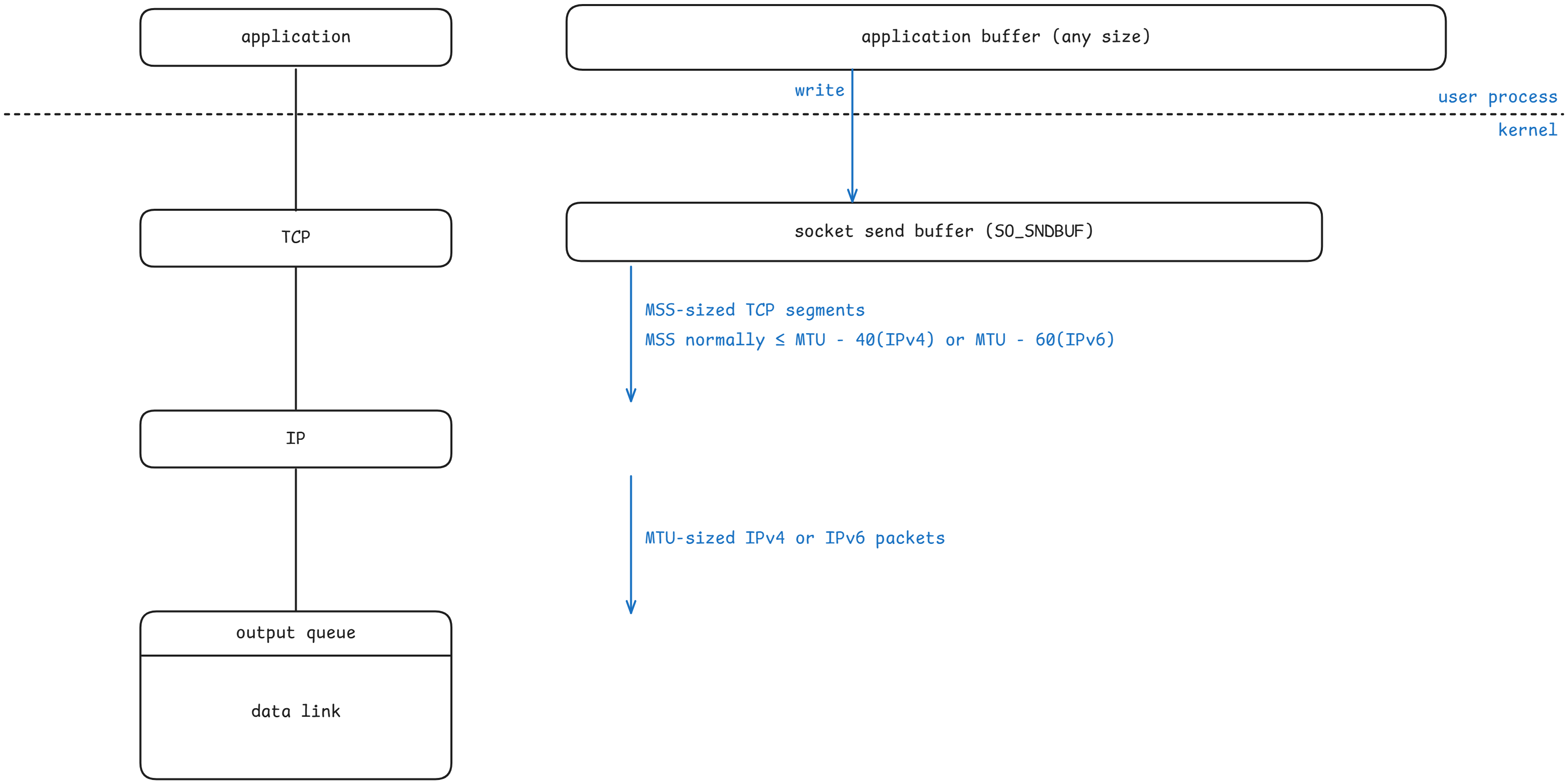
File I/O:read
#include <unistd.h>
// 成功時回傳實際讀取的位元組數,錯誤時回傳 -1,遇到 EOF 回傳 0
ssize_t read(int fd, void *buf, size_t nbytes);- 使用
read從已開啟的檔案讀取資料fd:檔案描述符buf:呼叫者提供的記憶體緩衝區,用來存放讀取到的資料nbytes:要求讀取的位元組數
- 讀取從檔案的當前 offset 開始,在成功回傳前,offset 會增加實際讀取的位元組數
- 讀取一般檔案時,如果在讀到要求數量之前就到達了檔案結尾(EOF):
- 範例問題:若要求讀取 100 bytes,但檔案只剩下 30 bytes?
- 回答:第一次呼叫
read會回傳 30,下一次呼叫read會回傳 0(表示 EOF)
- 還有其他情況(例如從 pipe、FIFO 讀取),課本中會有更多描述,之後會再討論
File I/O:write
#include <unistd.h>
// 成功時回傳實際寫入的位元組數,錯誤時回傳 -1
ssize_t write(int fd, void *buf, size_t nbytes);buf中的資料會被寫入到一個已開啟的檔案- 寫入從檔案當前的 file offset 開始
- 成功寫入後,file offset 會增加實際寫入的位元組數
- 與
read()不同,write()可以超過 EOF
- 常見的寫入錯誤:磁碟空間用盡,或超過該 process 可用的檔案大小限制
- 如果檔案在
open()時指定了O_APPEND,則在每次寫入前,file offset 都會被設到檔案尾端- 但
read()並不會像O_APPEND那樣自動跳到尾端,它會從當前的 offset 開始
- 但
read() 與 write() 小整理
write()可以超過 EOF- 如果寫入從 EOF 開始或更後的位置,檔案會被擴展
read()則在遇到 EOF 時停止- 若到達 EOF,
read()會回傳 0,表示沒有更多資料可以讀取
- 若到達 EOF,
File I/O:lseek
// off_t: signed int type
#include <unistd.h>
// 成功回傳新的 file offset,錯誤回傳 -1
off_t lseek(int fd, off_t offset, int whence);- 可以用
lseek()來設定一個已開啟檔案的「當前 file offset」 fd是檔案描述符whence可以是以下三種值:SEEK_SET:將檔案 offset 設為「從檔案開頭起算 offset 個位元組」(offset 可為正數或 0)SEEK_CUR:將檔案 offset 設為「當前 offset + offset 參數」(offset 可為正數、負數或 0)SEEK_END:將檔案 offset 設為「檔案大小 + offset 參數」(offset 可為正數、負數或 0)
常見操作
- 取得當前 file offset:
off_t currpos; currpos = lseek(fd, 0, SEEK_CUR); lseek()可以用來:- 移動到負的 offset(只要不超出檔案開頭)
- 從當前位置偏移 0 bytes(等於只是查詢 offset)
- 移動到超過檔案尾端的位置
行為特性
lseek()只會在 kernel 的「open file table」裡記錄 file offset- 呼叫
lseek()並不會觸發實際的 I/O - 下一次
read()或write()會依據更新後的 offset 進行 - 如果從「尚未寫入的區域」讀取,會回傳 0(類似空洞,稱為 hole)
範例(來自 APUE Figure 3.1)
下面的例子測試 standard input 是否能夠進行 seeking
#include "apue.h"
int main(void) {
if (lseek(STDIN_FILENO, 0, SEEK_CUR) == -1)
printf("cannot seek\n");
else
printf("seek OK\n");
exit(0);
}執行結果示例:
$ ./a.out < /etc/passwd
seek OK
$ cat < /etc/passwd | ./a.out
cannot seek
$ ./a.out < /var/spool/cron/FIFO
cannot seek說明:
- 當輸入來自一般檔案(例如
/etc/passwd)時,可以 seek - 當輸入是 pipe 或 FIFO 時,不能 seek
特殊情況與錯誤
- 如果
fd指向 pipe、FIFO 或 socket,lseek()會回傳 -1,並設置errno <errno.h>定義了整數變數errno,用來表示錯誤原因errno的常見錯誤值:EBADF:fd不是一個有效的檔案描述符EINVAL:whence無效,或 offset 超出合法範圍ENXIO:當whence為SEEK_DATA或SEEK_HOLE時,offset 超過檔案尾端EOVERFLOW:結果 offset 超過off_t可表示範圍ESPIPE:fd是 pipe、socket 或 FIFO
- Q:如果
lseek()使用的負 offset 超過了檔案開頭,會發生什麼?- A:回傳 -1,並設置
errno(通常為EINVAL)
- A:回傳 -1,並設置
範例 2(來自 APUE Figure 3.2)
#include "apue.h"
#include <fcntl.h>
char buf1[] = "abcdefghij";
char buf2[] = "ABCDEFGHIJ";
int main(void) {
int fd;
if ((fd = creat("file.hole", FILE_MODE)) < 0)
err_sys("creat error");
if (write(fd, buf1, 10) != 10)
err_sys("buf1 write error");
/* offset 現在是 10 */
if (lseek(fd, 16384, SEEK_SET) == -1)
err_sys("lseek error");
/* offset 現在是 16384 */
if (write(fd, buf2, 10) != 10)
err_sys("buf2 write error");
/* offset 現在是 16394 */
exit(0);
}執行流程
- 使用
creat()建立新檔案file.hole write(fd, buf1, 10)→ 在檔案開頭寫入 "abcdefghij",此時 offset = 10lseek(fd, 16384, SEEK_SET)→ 將 offset 移到 16384(中間的區域尚未寫入)write(fd, buf2, 10)→ 在 offset=16384 的位置寫入 "ABCDEFGHIJ",最後 offset=16394
檔案內容觀察
$ ./a.out
$ ls -l file.hole
-rw-r--r-- 1 sar 16394 Nov 25 01:01 file.hole- 檔案大小為 16394 bytes
使用 od -c file.hole 查看內容:
$ od -c file.hole
0000000 a b c d e f g h i j \0 \0 \0 \0 \0 \0
0000020 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0
-
0040000 A B C D E F G H I J
0040012- 可以看到前 10 個字元是 "abcdefghij"
- 接著是一大段
\0(代表 hole,尚未分配實體磁碟區塊,但讀取時會以 0 填充) - 最後是 "ABCDEFGHIJ"
檔案空洞的效果
透過 ls -ls 比較 file.hole 與沒有 hole 的版本:
$ cat < file.hole > file.nohole
$ ls -ls file.hole file.nohole
8 -rw-r--r-- 1 sar 16394 Nov 25 01:01 file.hole
20 -rw-r--r-- 1 sar 16394 Nov 25 01:03 file.noholefile.hole的檔案大小一樣是 16394 bytes,但實際只使用了 8 個磁碟區塊file.nohole經過cat重新複製後,空洞被填補為實際的\0,因此用了 20 個磁碟區塊
小整理
lseek()可以讓檔案 offset 跳過一段未寫入的區域- 如果之後直接寫入,會在檔案中間形成「hole」
- hole 區域在檔案大小上會計入,但實際不佔用磁碟空間
- 這種檔案稱為「sparse file」(稀疏檔案)
Unix time command
當我們在 Linux 使用 time 命令來測量程式執行時間時,會看到三個主要的時間統計值:
- real
又稱「wall clock time」或「elapsed time」,表示從程式開始執行到結束所經過的實際時間,就像用手錶量到的時間。 這個時間包含了 CPU 執行時間、I/O 等待時間、context switch、以及其他程式執行所造成的延遲 - user
程式在「user space」中執行所消耗的 CPU 時間。 這部分主要包含應用程式本身的計算工作,例如數學運算、字串處理、記憶體操作等 - sys
程式在「kernel space」中執行所消耗的 CPU 時間。 這通常來自系統呼叫,例如read()、write()、open()、close()等需要進入 kernel 的操作
例如下面是我環境上 time ls 命令的輸出:
mes@MesDesktop:~/MesBlog$ time ls
mes-build.sh node_modules package.json pnpm-lock.yaml src tsconfig.json
real 0m0.002s
user 0m0.001s
sys 0m0.001s這三個值的關係為:
- 一般情況下
real >= user + sys,因為除了 CPU 真正執行的時間外,還有等待 I/O、被排程器暫停、或其他延遲 - 在平行運算(多核心)下,可能出現
real < user + sys,因為多個核心同時貢獻了 CPU 時間
導致 real 大於 user + sys 差異的原因很多,常見的包括:
- I/O Wait Time:等待 I/O(disk、network 等)計入 clock time,不計入 CPU time
- Context Switching:process 或 thread 切換的時間不完全反映在 CPU time
- Parallelism:在 multi-core 系統上可能同時用到多顆 core,使 CPU time 可能超過 clock time
- System Load:其他 process 造成延遲,增加 clock time 但不增加該 process 的 CPU time
- Sleep Time:自願 sleep 或等待事件的時間不計入 CPU time
- Scheduler Behavior:排程器未立即執行就緒的 process,增加 clock time
- Hardware Interrupts:處理硬體中斷的時間可能未完整反映在 CPU time
- Time Precision:clock time 與 CPU time 的量測精度不同
I/O Efficiency
下例程式(APUE Figure 3.5)實作了一個簡單的 I/O loop:
- 從
stdin使用read()讀取資料到一個 buffer - 再使用
write()將 buffer 的內容寫到stdout - 重複直到檔案結束
#define BUFFSIZE 4096
int n;
char buf[BUFFSIZE];
while ((n = read(STDIN_FILENO, buf, BUFFSIZE)) > 0)
if (write(STDOUT_FILENO, buf, n) != n)
err_sys("write error");
if (n < 0)
err_sys("read error");測試結果:
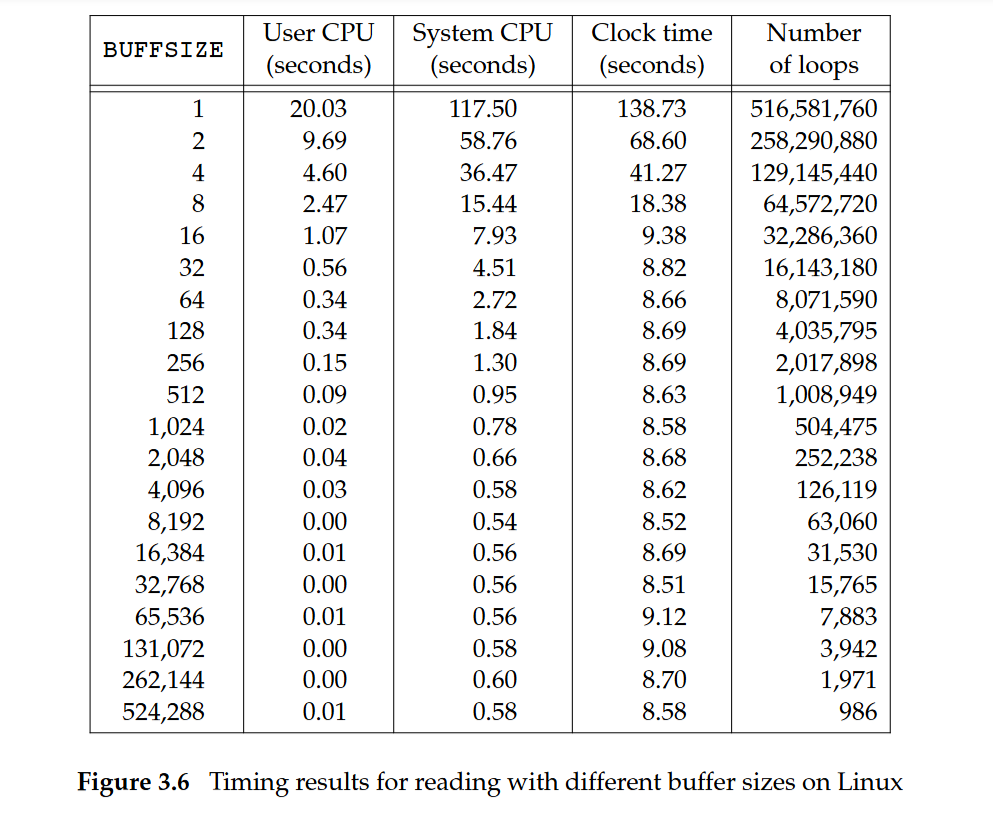
針對一個約 516 MB 的檔案,其使用 20 種不同的 buffer size 測試,觀察 user CPU time、system CPU time、以及 wall clock time
- 當 buffer size 很小(例如 1 byte, 2 bytes),
read()與write()呼叫次數非常多(數億次),system CPU time 非常高(>100 秒),wall clock time 也非常長(>130 秒) - 當 buffer size 增大(例如 4096, 8192, 32768 bytes),系統呼叫次數急劇下降,system CPU time 減少到 <1 秒,wall clock time 也穩定在 ~8.5 秒左右
- 這顯示「I/O 系統呼叫的開銷」遠大於「單純搬移資料的時間」,因此較大的 buffer 能大幅減少系統呼叫數量,提升效能
- 特殊現象:當 buffer size 到達 32 bytes 或更大時,wall clock time 幾乎沒有差異,因為系統呼叫次數已經下降到一個相對合理的數量,再增大 buffer 並不會帶來太大改進
- 小整理:
time呈現的三種時間(real, user, sys)能幫助我們理解程式效能瓶頸:- user 高 → 演算法運算量大
- sys 高 → 系統呼叫過於頻繁(典型的 I/O 瓶頸)
- real 高但 user+sys 小 → 程式在等待 I/O 或被 scheduler 暫停
- 在 I/O 效率實驗中,最關鍵的瓶頸是 buffer size 選擇
- 小 buffer → 太多
read/write系統呼叫 → sys time 過高 - 適當的 buffer(4KB 到數十 KB)→ 效能最佳化,因為呼叫次數與 CPU 負載達到平衡
- 再增大 buffer → 改善有限,因為瓶頸不在系統呼叫,而在 I/O 裝置吞吐量
- 小 buffer → 太多
- 實際應用中,作業系統和標準 I/O 函式庫(例如
fread/fwrite)通常已經提供緩衝機制,避免了使用極小 buffer 的低效率情況 real >= user + sys的原因主要在於等待與調度,而不是 CPU time 的計算錯誤- 適當的 buffer size 對 I/O 效率影響極大。 小 buffer 造成 system CPU time 激增,導致整體效能低下
- 在實務上,理解
time三種時間的關係,可以幫助定位效能問題是出在「演算法計算」還是「I/O 系統呼叫」
Unix Buffer(Page)Cache
- Unix kernel 會維護一個 Buffer Cache(或稱 Page Cache),目的是避免每次存取都直接觸發昂貴的磁碟 I/O
- 核心的兩個優化策略是:
- Read-ahead(預讀):當系統偵測到應用程式在順序讀檔案,會自動一次讀取超過應用程式要求的區塊,把未來可能會需要的資料先放進快取,這樣之後的
read()就能直接從快取中取資料,而不用再向磁碟請求 - Delayed-write(延遲寫入):當應用程式呼叫
write(),資料會先寫入 kernel 的 buffer cache,而不是馬上寫到磁碟。 之後系統會根據策略(例如快取區塊滿了、或定期同步)再把資料真正寫回磁碟。 這樣可以合併多次小的寫入,降低磁碟 I/O 次數
- Read-ahead(預讀):當系統偵測到應用程式在順序讀檔案,會自動一次讀取超過應用程式要求的區塊,把未來可能會需要的資料先放進快取,這樣之後的
Duplicating file descriptors(檔案描述符複製)
#include <unistd.h>
// 成功回傳新的檔案描述符,錯誤回傳 -1
int dup(int fd);
int dup2(int fd, int fd2);- Unix 提供系統呼叫
dup/dup2來複製既有的檔案描述符(類似為某個開啟中的檔案建立別名) - 這可以用來實作 shell 的管線與重新導向,例如
ls -la | morecat file | wcman ksh | grep "history"ls -l | grep "bowman" | wcwho | sort > current_users
|與>怎麼實作:由 shell 進行- 建立 pipe(
pipe)取得一對檔案描述符(讀端、寫端) - 透過
fork產生子行程,分別在各子行程用dup2把標準輸入(fd 0)或標準輸出(fd 1)接到檔案或 pipe 的端點 - 再以
execve執行目標程式,之後程式看到的 fd 0/1 已經對接到檔案或另一個行程
- 建立 pipe(
dup/dup2會建立「同一個開啟檔案」的新檔案描述符- 複製的意義:兩個檔案描述符會「指向同一個 open file table entry」
- 影響:若對其中一個 fd 做
lseek改變偏移量(file offset),另一個 fd 的偏移量也會一併改變 - 行為差異
dup:回傳「目前可用的最小」新 fddup2:把來源fd複製到指定目的fd2,若fd2先前是開啟狀態,kernel 會先關閉它,再重用
範例 1
假設下一個可用的 fd 是 3:
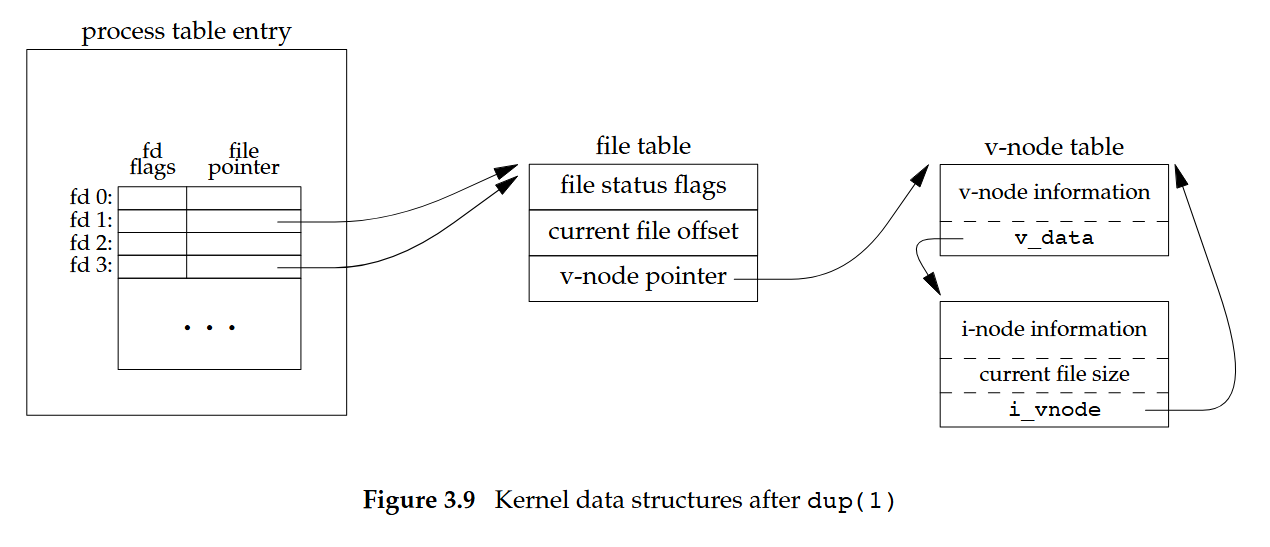
執行 dup(1) 後,fd 1 與 fd 3 會同指向同一個 open file table entry
範例 2
假設 foobar.txt 的內容是 6 個 ASCII 字元 foobar
int main()
{
int fd1, fd2;
char c;
fd1 = open("foobar.txt", O_RDONLY, 0);
fd2 = open("foobar.txt", O_RDONLY, 0);
read(fd1, &c, 1);
read(fd2, &c, 1);
printf("c = %c\n", c);
exit(0);
}fd1與fd2是兩次獨立的open,各自有不同的 open file table entry,偏移量彼此獨立- 第一次
read(fd1, ...)讀到f,fd1偏移量變成 1 - 第二次
read(fd2, ...)仍從檔案開頭讀到f - 輸出:
c = f
範例 3
int main()
{
int fd1, fd2;
char c;
fd1 = open("foobar.txt", O_RDONLY, 0);
fd2 = open("foobar.txt", O_RDONLY, 0);
read(fd2, &c, 1);
dup2(fd2, fd1);
read(fd1, &c, 1);
printf("c = %c\n", c);
exit(0);
}- 先用
read(fd2, ...)讀到f,使fd2的偏移量變 1 dup2(fd2, fd1)之後,fd1與fd2指向同一個 open file table entry(共享偏移量 1)- 接著
read(fd1, ...)會讀到第二個字元o - 輸出:
c = o
範例 4
int main()
{
int fd;
char *s;
fd = open("file", O_WRONLY | O_CREAT | O_TRUNC, 0666);
dup2(fd, 1);
close(fd);
printf("Hello %d\n", fd);
}- 用
dup2把標準輸出(fd = 1)導向檔案file,然後關閉原先的fd - 之後的
printf會寫到檔案而不是終端機 - 寫入內容為
Hello 3\n(假設開啟file時取得的 fd 是 3)
範例 5
執行命令:./a.out file1 file2
int main(int argc, char **argv, char envp)
{
int fd1, fd2;
int dummy;
char *newargv[2];
fd1 = open(argv[1], O_RDONLY);
dup2(fd1, 0);
close(fd1);
fd2 = open(argv[2], O_WRONLY | O_TRUNC | O_CREAT, 0644);
dup2(fd2, 1);
close(fd2);
newargv[0] = "cat";
newargv[1] = (char *)0;
execve("/bin/cat", newargv, envp);
exit(0);
}- 步驟
- 把標準輸入(fd = 0)以
dup2指到file1 - 把標準輸出(fd = 1)以
dup2指到file2 - 以
execve執行/bin/cat,它會從標準輸入讀取、寫到標準輸出
- 把標準輸入(fd = 0)以
- 結果:
file2變成file1的內容拷貝(覆寫建立),終端機沒有輸出
File I/O: fcntl
#include <fcntl.h>
// 成功時回傳值依 cmd 而定,失敗回傳 -1
int fcntl(int fd, int cmd, ... /* int arg */ );fcntl 函式有以下 5 種功能:
- 複製一個已有的描述符(
cmd = F_DUPFD或F_DUPFD_CLOEXEC) - 獲取/設置file descriptor flags(
cmd = F_GETFD或F_SETFD) - 獲取/設置file status flags(
cmd = F_GETFL或F_SETFL) - 獲取/設置異步 I/O 所有者(
cmd = F_GETOWN或F_SETOWN) - 獲取/設置記錄鎖(
cmd = F_GETLK,F_SETLK,F_SETLKW)
file descriptor flags 與 file status flags
descriptor flag 與 status flag 是兩種不同層級:前者綁在「fd 本身」,後者綁在「open file table entry」
底下是 fcntl 的前 8 個 cmd,後 3 個會到後面再講
F_DUPFD
複製給定的 file descriptorfd。 函式會回傳新的 file descriptor。 它會選擇一個「尚未開啟、且編號 ≥ 第三個整數引數」的最小編號作為新fd新的 descriptor 與原本的 fd 共享同一個「open file table entry」(見圖 3.9)。 但新 descriptor 擁有自己的「descriptor flag」,而且其
FD_CLOEXEC(close-on-exec)旗標會被清除,這表示在執行exec之後,該 descriptor 仍會保持開啟F_DUPFD_CLOEXEC
複製 file descriptor,並為新的 descriptor 設定FD_CLOEXEC旗標。 回傳新的 file descriptorF_GETFD
以函式回傳值的方式,取得 fd 的「descriptor flag」。 目前定義的 descriptor flag 只有一個:FD_CLOEXECF_SETFD
為fd設置 descriptor flags。 新 flag 的值由第 3 個整數引數提供注意,有些既有程式在處理 file descriptor 旗標時,並不使用常數
FD_CLOEXEC。 它們改以把該旗標設為 0(不在exec時關閉,亦為預設)或 1(在exec時關閉)的方式來操作F_GETFL
以函式回傳值的方式,取得 fd 的「file status flag」。 我們在介紹 open 函式時曾經說明這些 status 旗標。 它們列於下圖 3.10 中: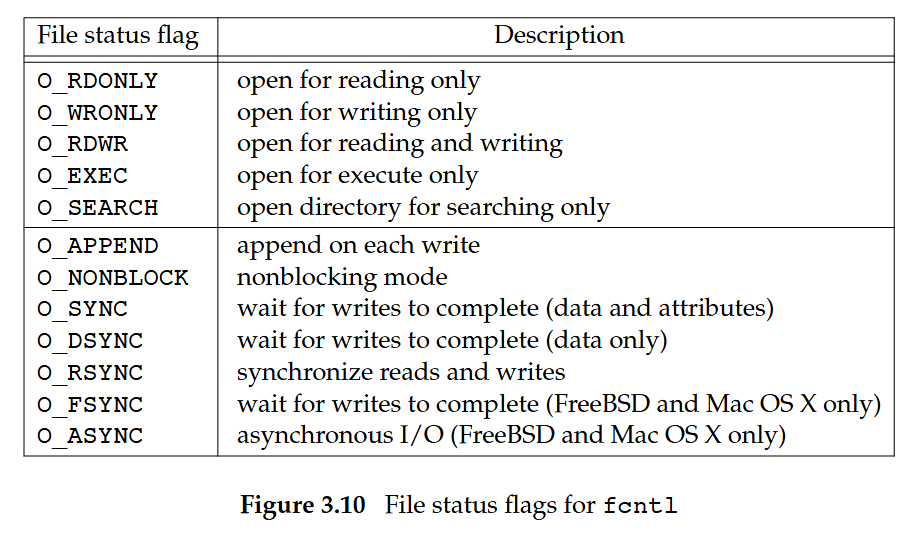
(From APUE 3rd Edition:Figure 3.10) 可惜的是,用於「存取模式」的五個旗標
O_RDONLY、O_WRONLY、O_RDWR、O_EXEC與O_SEARCH並不是可直接測試的獨立位元如前所述,前三者通常因歷史因素而分別取 0、1、2 的值。 此外,這五個值彼此互斥:一個檔案同一時間只能啟用其中之一。 因此,我們必須先使用
O_ACCMODE遮罩取出存取模式的位元,再將結果拿來與這五種值之一比對F_SETFL
把 file status flag 設為第三個整數引數所指定的值。 僅有下列旗標允許被變更:O_APPEND、O_NONBLOCK、O_SYNC、O_DSYNC、O_RSYNC、O_FSYNC與O_ASYNCF_GETOWN
取得目前接收SIGIO與SIGURG訊號的行程 ID 或行程群組 IDF_SETOWN
設定將接收SIGIO與SIGURG訊號的行程 ID 或行程群組 ID。 第三個引數若為正值,表示指定的是行程 ID,若為負值,則表示行程群組 ID,且其值為該引數的絕對值
返回值說明
fcntl 的回傳值取決於所給的 cmd。 所有命令在錯誤時都回傳 −1,成功時則回傳各自定義的值
F_DUPFD:回傳新的文件描述符F_GETFD、F_GETFL:回傳各自的旗標值F_GETOWN:回傳正的行程 ID 或負的行程群組 ID
範例 1:讀取 file status flags
下例的程式接受一個命令列引數,用來指定某個 file descriptor,並印出該 descriptor 的部分檔案旗標說明
int main(int argc, char *argv[])
{
int accmode, val;
if (argc != 2)
err_quit("usage: a.out <descriptor#>");
if ((val = fcntl(atoi(argv[1]), F_GETFL, 0)) < 0)
err_sys("fcntl error for fd %d", atoi(argv[1]));
accmode = val & O_ACCMODE;
if (accmode == O_RDONLY) printf("read only");
else if (accmode == O_WRONLY) printf("write only");
else if (accmode == O_RDWR) printf("read write");
else err_dump("unknown access mode");
if (val & O_APPEND) printf(", append");
if (val & O_NONBLOCK) printf(", nonblocking");
if (val & O_SYNC) printf(", synchronous writes");
putchar('\n');
exit(0);
}說明:
fcntl(fd, F_GETFL, 0):取得fd的 file status flags- 利用
O_ACCMODE遮罩來判斷是RDONLY、WRONLY或RDWR - 其他 flag(如
O_APPEND、O_NONBLOCK)則用位元運算判斷
下面的是在 bash(Bourne-again shell)中呼叫本程式時的操作,實際結果會隨你所用的 shell 不同而有所差異:
$ ./a.out 0 < /dev/tty
read only
$ ./a.out 1 > temp.foo
write only
$ ./a.out 2 2>>temp.foo
write only, append
$ ./a.out 5 5<>temp.foo
read write5<>temp.foo會把temp.foo以讀寫模式開啟到 file descriptor 5- 在 bash 中,
n<>file代表以「讀寫」模式把檔案繫結到fd n - 這不是 C 程式直接呼叫
open(),而是由 shell 在執行你的程式前就替你打開fd 5 - 因為是「讀寫」模式,所以用上例程式去檢查
fd 5,會看到O_RDWR - 這也說明:程式端不一定知道檔名,但能藉由
fd觀察到開啟模式與旗標
範例 2:修改 file status flags
當我們要修改 descriptor flag 或 status flag 時,務必要先取出目前的旗標值,依需求修改後,再把新值設定回去。 不能只單純下 F_SETFD 或 F_SETFL 命令,因為這樣可能會把先前已啟用的旗標位元關掉
下例是一個用來替某個 descriptor 設定一個或多個檔案狀態旗標的範例:
void set_fl(int fd, int flags) {
int val;
if ((val = fcntl(fd, F_GETFL, 0)) < 0)
err_sys("fcntl F_GETFL error");
val |= flags; // 開啟指定的 flag
// val &= ~flags; // 關閉指定的 flag
if (fcntl(fd, F_SETFL, val) < 0)
err_sys("fcntl F_SETFL error");
}F_GETFL:先取出目前的 file status flagsF_SETFL:再設回去,但加入新的 flag(或刪掉 flag)- 例如:可以把一個開啟中的 fd 改成非阻塞模式 (
O_NONBLOCK)
範例 3:F_SETFD vs F_SETFL
程式碼範例:
fd1 = open(pathname, oflags);
fd2 = dup(fd1);
fd3 = open(pathname, oflags);fd1與fd2共用同一個 open file table entry(因為dup)fd3是獨立open,所以有不同的 open file table entry
影響:
F_SETFL(修改 file status flags)會影響整個 open file table entry → 所以fd1和fd2都會受影響F_SETFD(修改 file descriptor flags,如 FD_CLOEXEC)只影響單一fd,因為它存在 process table entry → 所以fd1、fd2不會互相影響
/dev/fd
- 新版 Unix 系統提供
/dev/fd目錄,內有0、1、2… 等項目(以檔案形式對應 fd) - 開啟
/dev/fd/n等同於複製 descriptorn
int fd = open("/dev/fd/0", mode); // 等同於
int fd2 = dup(0);File I/O:ioctl
#include <unistd.h> /* System V */
#include <sys/ioctl.h> /* BSD 與 Linux */
/* 失敗回傳 -1,成功回傳其他值 */
int ioctl(int fd, int request, ...);ioctl是 I/O 操作的萬用介面:凡無法用標準檔案 I/O 函式表達的操作,通常以ioctl提供- 每個裝置驅動可以自訂自己的
ioctl命令集合 - 系統也為不同裝置類別提供通用的
ioctl命令
Error Handling(錯誤處理)
<errno.h>定義整數變數errno,在系統呼叫或部分程式庫函式失敗時設定,以指出錯因- 規範於 POSIX.1 與 C99
- 只有當呼叫的回傳值表示錯誤時(多數系統呼叫回傳
-1,多數函式回傳-1或NULL),errno的值才有意義 - 若沒有錯誤,
errno不會被改變 - 可參考 Linux 的
errno(3)man page
Error Recovery(錯誤復原)
- 致命錯誤:不進行復原(例如
EACCES、EFAULT等) - 非致命錯誤:等待後重試,以避免異常結束、增加健壯性(例:
EAGAIN、ENFILE、ENOSPC、ENOMEM等)
File I/O:Concurrency(並行)
Append 範例(未使用 O_APPEND)
/* 將 fd 的檔案指標移到 EOF,然後寫入 100 bytes */
if (lseek(fd, 0, SEEK_END) < 0)
err_sys("lseek error");
if (write(fd, buf, 100) != 100)
err_sys("write error");
/* 注意:這邊假設 fd 不是以 O_APPEND 開啟的 */- 注意:檔案可能同時被多個行程/執行緒存取
- 想一下如果行程 A、B 同時執行上面兩行、寫入同一個檔案,結果會怎樣?
lseek(fd, SEEK_END)跟write()並不是原子的。 A、B 可能同時lseek到相同 EOF 而互相覆蓋/交錯- 解法:以
O_APPEND開啟(核心會對每個write原子地移動到 EOF 再寫)。 或加檔案鎖。 或以pwrite明確寫固定偏移量(非附檔情境)
Race condition 範例
考慮以下情況:
if ((fd = open(path, O_WRONLY)) < 0) {
if (errno == ENOENT) { // 檔案不存在
if ((fd = creat(path, mode)) < 0) // 就建立
err_sys("creat error");
}
else {
err_sys("open error");
}
}這邊的目標是:
- 若檔案已存在:用唯寫開啟
- 若不存在:建立後開啟
乍看合理,但中間有競態窗與語意不一致兩個大問題
問題:TOCTTOU 競態(Time Of Check To Time Of Use)
open(path, O_WRONLY) 失敗(ENOENT)與後續 creat(path, mode) 之間不是原子動作。 只要在這個空窗期有別的行程動到同一路徑,就可能出事
典型時序(A、B 兩個行程同時執行):
| 時間 | 行程 A | 行程 B | 結果 |
|---|---|---|---|
| t0 | open(path, O_WRONLY) → ENOENT | A 判定「不存在」 | |
| t1 | (被排程暫停) | open(path, O_WRONLY | O_CREAT | O_EXCL, mode) 成功建立 | 檔案現在存在 |
| t2 | A 繼續:creat(path, mode) | creat 等於 open(..., O_CREAT | O_TRUNC),既然檔案此刻已存在 → 被截斷為 0 長度 |
- 為什麼可被截斷?
creat等價於open(path, O_WRONLY | O_CREAT | O_TRUNC, mode),如果目標在呼叫時檔案已存在,O_TRUNC會把它清空
pread / pwrite
#include <unistd.h>
/* 成功回傳讀到的位元組數,遇 EOF 回 0,失敗回 -1 */
ssize_t pread (int fd, void *buf, size_t nbytes, off_t offset);
/* 成功回傳寫入的位元組數,失敗回 -1 */
ssize_t pwrite(int fd, const void *buf, size_t nbytes, off_t offset);- 等價於「
lseek()+read()/write()」但以單一步驟原子地完成 - 在指定
offset處進行讀/寫,不會改變目前檔案偏移 - 回傳值語意與
read/write相同
File/Record Locking
- Unix 提供鎖定機制以避免檔案不一致:
- File locking:針對整個檔案的獨占存取
- Record locking(byte-range locking):只對檔案中指定區段(位元組範圍)做獨占存取
- Unix 系統允許行程對檔案加上獨占鎖,以防止其他行程同時讀/寫同一檔案
- 當索取鎖的時候,如果該行程:
- 成功取得了鎖,則它可讀寫該檔案
- 被拒絕了,則直到鎖被釋放前無法取得鎖
- 當索取鎖的時候,如果該行程:
在 Unix 中使用建議式鎖定(advisory locking)的三種方式
- 檔案鎖:
flock()(鎖整個檔案) - 區段鎖:
fcntl()(對檔案中的任意位元組範圍加鎖)lockf()(基於fcntl()之上的簡化介面)
建議式鎖定(Advisory Locking) vs 強制式鎖定(Mandatory Locking)
建議式(Advisory)
- 介面:
fcntl()、flock()、lockf() - 屬於合作式鎖定:所有參與的行程必須自律地遵守鎖定協定,在存取共享檔案時主動呼叫鎖定函式
- 問題:就算行程沒有取得鎖,它仍可以無視協定以存取共享檔案,這是設計上的行為,並非錯誤
強制式(Mandatory)
- 作業系統核心會檢查並強制每一個對共享檔案的操作,避免違反鎖定
- 參考:man7:
fcntllocking
範例
假設 lock() 為建議式鎖
情境 A(只有 Process 1 用鎖,Process 2 不用鎖)
下例中 Process 2 仍可寫入指定檔案,忽略 Process 1 的建議式鎖
Process 1:
int fd = open(PATH, ..);
// use lock() to acquire a lock
int ret = lock(fd, ...);
if (!ret) {
// Lock acquired. Read the file now
while (count)
int bytes = read(fd, buf, sizeof(buf));
}
ret = unlock(fd, ...);
close(fd);Process 2:
int fd = open(PATH, ..);
// didn't use the lock()
int bytes = write(fd, buf, sizeof(buf));
close(fd);情境 B(兩邊都使用鎖):
下例中 Process 2 只有在成功取得寫入的獨占鎖時,才能寫入該檔案
Process 1:
int fd = open(PATH, ..);
// use lock() to acquire a lock
int ret = lock(fd, ...);
if (!ret) {
// Lock acquired. Read the file now
while (count)
int bytes = read(fd, buf, sizeof(buf));
}
ret = unlock(fd, ...);
close(fd);Process 2:
int fd = open(PATH, ..);
// use lock() to acquire a lock
int ret = lock(fd, ...);
if (!ret) {
int bytes = write(fd, buf, sizeof(buf));
}
ret = unlock(fd, ...);
close(fd);flock
#include <sys/file.h>
// returns: 0 on success, −1 on error
int flock(int fd, int operation);flock()對已開啟的檔案套用或移除鎖operation可為:LOCK_SH:加共享鎖,同一時間可有多個行程持有同一檔案的共享鎖LOCK_EX:加獨占鎖,同一時間只有一個行程可持有該檔案的獨占鎖LOCK_UN:移除本行程持有的既有鎖
Review:File I/O:fcntl
#include <fcntl.h>
// The value returned on a success call depends on cmd; -1 is returned on error
int fcntl(int fd, int cmd, ... /* int arg */ );
/* ... is the ISO C way to specifythat the number and types of the remaining arguments may vary */fcntl()會對「已開啟的 fd」執行由cmd指定的操作fcntl支援 11 個cmd值、對應五類用途(詳見第 3.14 章):- 複製既有 descriptor(就像
dup) - 取得/設定 file descriptor flags(存在每行程的「fd 表項目」)
- 取得/設定 file status flags(存在開啟檔案表項目)
- 取得/設定非同步 I/O 擁有者
- 取得/設定檔案紀錄鎖
- 複製既有 descriptor(就像
- 是否需要第三個引數
arg視cmd而定(可選)
#include <fcntl.h>
// depends on cmd if OK, −1 on error
int fcntl(int fd, int cmd, ..., /* struct flock *flockptr */ );
struct flock {
short l_type; /* F_RDLCK, F_WRLCK, F_UNLCK */
short l_whence; /* SEEK_SET, SEEK_CUR, or SEEK_END, same asthe whence in lseek */
/* (問題:`asthe` 應為 `as the`) */
off_t l_start; /* offset in bytes relative to whence */
off_t l_len; /* length, in bytes, 0 means lock to EOF */
pid_t l_pid; /* filled in by F_GETLK, ignore otherwise */
};fcntl以flockptr指向struct flock,描述鎖的資訊fcntl有三種記錄鎖相關的cmd:F_SETLK、F_SETLKW、F_GETLK
- 其中
l_type可為:F_RDLCK:共享讀鎖F_WRLCK:獨占寫鎖F_UNLCK:解除鎖
讀鎖/寫鎖語意
- 共享讀鎖:任意多個行程可在同一位元組(或區段)上同時持有讀鎖。 但只要有讀鎖存在,該區段就不能有寫鎖
- 獨占寫鎖:同一位元組(或區段)同時只能被一個行程持有寫鎖。 有寫鎖時,該區段不能有任何讀/寫鎖(單一寫者、無讀者)
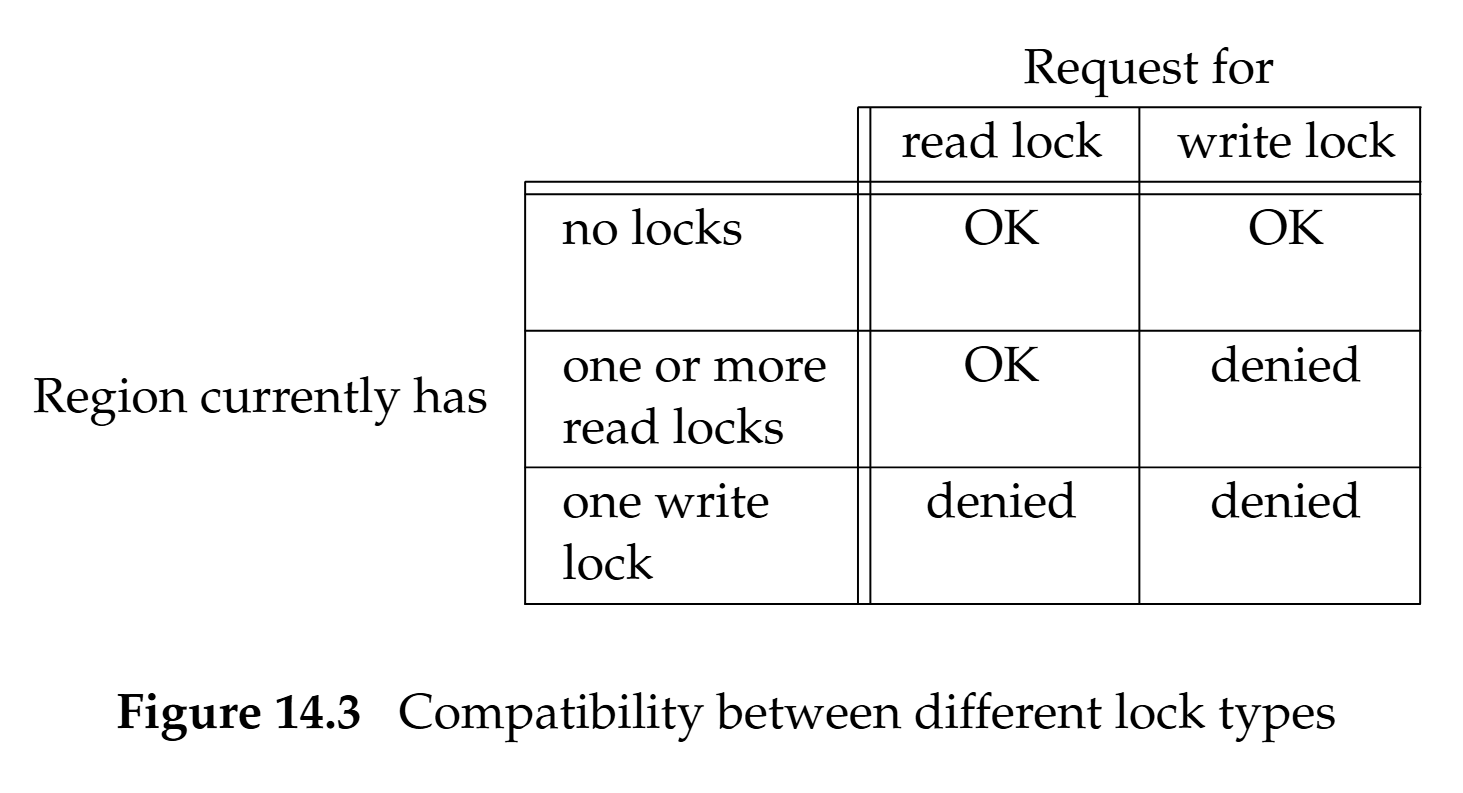
fcntl 支援的鎖定命令
F_GETLK:測試flockptr所描述的鎖是否可加:- 若可,回傳時把
l_type設為F_UNLCK(其他欄位不變) - 若不可(檔案某處已被鎖上),回傳時用阻擋你的其中一把鎖來更新
flockptr的l_type/l_whence/l_start/l_len/l_pid
- 若可,回傳時把
F_SETLK:嘗試依flockptr設鎖。 若失敗(例如被別的行程持鎖),立即回傳-1並設errno(EACCES或EAGAIN)- 加鎖:
l_type設F_RDLCK或F_WRLCK,範圍由l_whence/l_start/l_len指定 - 解鎖:
l_type設F_UNLCK
- 加鎖:
F_SETLKW:同F_SETLK,但若衝突,呼叫端會等待(阻塞)直到鎖釋放
fcntl 記錄鎖:補充
- 設定或解除鎖時,系統會合併/分割相鄰的區段(必要時)
- 例如若已鎖定 100–149、151–199,當再鎖定位元組 150 時,核心會把它們合併成 100–199
- 非原子:先
F_GETLK再F_SETLK/F_SETLKW會做兩次fcntl(),中間可能有其他行程搶先加鎖 - 開啟模式要求:
- 要取得讀鎖,
fd必須以可讀方式開啟 - 要取得寫鎖,
fd必須以可寫方式開啟
- 要取得讀鎖,
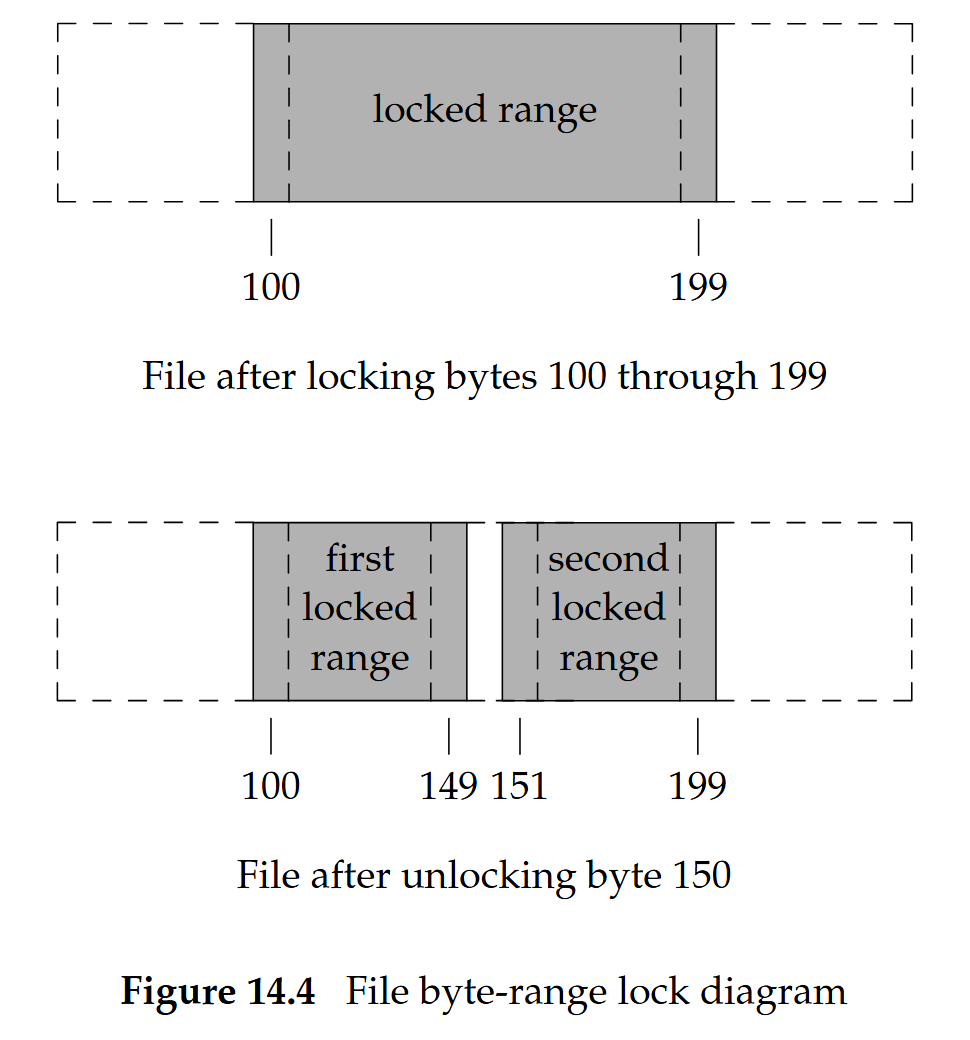
Unix 對記錄鎖的實作
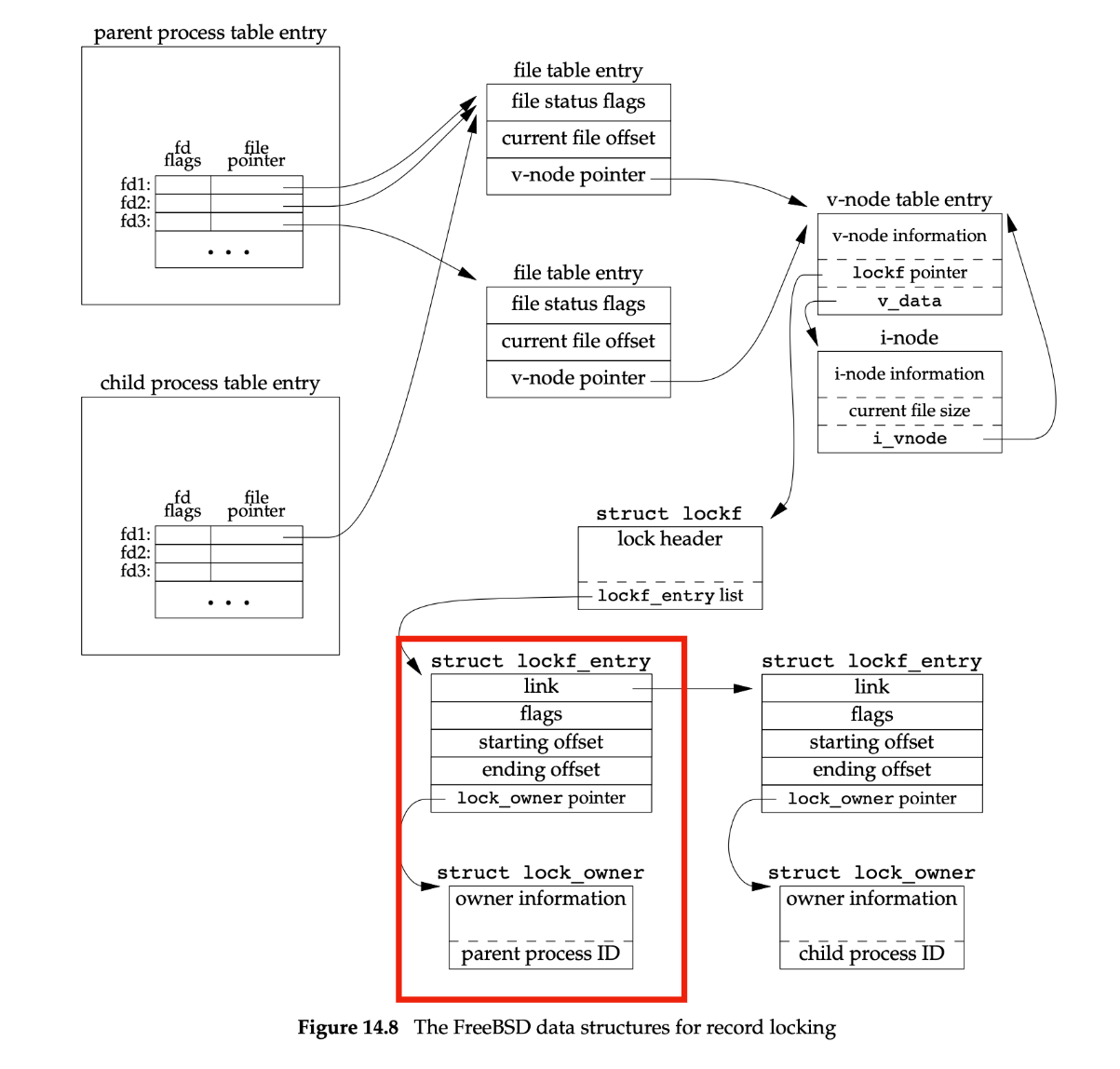
核心不會追蹤「哪個 descriptor 擁有哪把記錄鎖」,而是以 <process:file> 的對映(存在 vnode/inode 結構中)追蹤
鎖的釋放
- 行程結束時,該行程的所有鎖會被自動釋放
- 鎖是以
<process:file>的對映來記錄的:當關閉某個指向該檔案的任何fd時,該行程在那個檔案上的所有鎖都會被釋放
範例
問題:fd1 上的鎖會怎樣?
Process 1:
fd1 = open(pathname, ...);
read_lock(fd1, ...);
fd2 = dup(fd1);
close(fd2);Process 2:
fd1 = open(pathname, ...);
read_lock(fd1, ...);
fd2 = open(pathname, ...);
close(fd2);若某個行程關閉任何一個指向某檔案的 file descriptor,該行程在那個檔案上的所有鎖都會被釋放,無論這些鎖最初是透過哪個 descriptor 取得的。 這表示只要有某個函式因某些原因決定去開啟、讀取並關閉同一個檔案,行程就可能失去自己在該檔案(例如 /etc/passwd 或 /etc/mtab)上的鎖
範例 2
下例是犯了 fcntl 的「建議式(advisory)紀錄鎖」語意,特別是鎖與「行程 × 檔案」綁定,而不是與某個特定的 fd 綁定。 同一行程只要關閉任何一個指向該檔案的 file descriptor,不管鎖是用哪個 fd 加上的,該行程在此檔案上的所有 fcntl 鎖都會被釋放
locker.c(上鎖的一方)
做的事(依序):
- 先確保
path存在,並以O_CREAT|O_RDWR建立/開啟(寫鎖需要可寫開啟,否則會EBADF) - 開兩個
fd指向同一檔案:fd1 = open(path, O_RDWR)fd2 = dup(fd1)
- 透過
fd1對整個檔案加 寫鎖:struct flock lk = {.l_type=F_WRLCK,.l_whence=SEEK_SET,.l_start=0,.l_len=0}; fcntl(fd1, F_SETLK, &lk); // 非阻塞,加不到會立刻失敗l_start=0, l_len=0代表「從檔頭到 EOF」整檔加鎖
- 睡 2 秒後 關閉
fd2(注意:鎖是用fd1加的) - 印出「我關了
fd2,我在這個檔案上的鎖已被釋放」,再睡 3 秒,最後才關fd1
要點:
- 這支程式故意不關
fd1,而是關另一個fd2,用來證明「關閉任何指向同一檔案的fd都會把本行程在該檔的鎖全部釋放」
// locker.c
#define _XOPEN_SOURCE 700
#include <errno.h>
#include <fcntl.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
static int lock_wholefile(int fd, short type)
{
struct flock lk = {.l_type = type, .l_whence = SEEK_SET, .l_start = 0, .l_len = 0};
return fcntl(fd, F_SETLK, &lk);
}
int main(int argc, char **argv)
{
const char *path = (argc > 1) ? argv[1] : "lockdemo.tmp";
// Ensure file exists; use O_RDWR so both sides can lock consistently.
int createfd = open(path, O_CREAT | O_RDWR, 0644);
if (createfd < 0) {
perror("open(create)");
return 1;
}
close(createfd);
int fd1 = open(path, O_RDWR);
if (fd1 < 0) {
perror("open fd1");
return 1;
}
// int fd2 = open(path, O_RDWR);
int fd2 = dup(fd1);
if (fd2 < 0) {
perror("open fd2");
return 1;
}
if (lock_wholefile(fd1, F_WRLCK) == -1) {
perror("locker: F_WRLCK via fd1");
return 1;
}
printf("locker: acquired F_WRLCK via fd1=%d on %s\n", fd1, path);
printf("locker: sleeping 2s, then close(fd2) (NOT the locking fd)\n");
sleep(2);
// POSIX: closing any fd for this file releases all locks held by this process.
close(fd2);
printf("locker: closed fd2; my locks on %s are now released.\n", path);
// Keep fd1 open briefly so you can see waiter proceed while fd1 is still open.
sleep(3);
close(fd1);
puts("locker: done.");
return 0;
}waiter.c(等待鎖的一方)
做的事(依序):
以
O_RDWR開啟同一個檔案對整個檔案加寫鎖,但使用
F_SETLKW(阻塞版):fcntl(fd, F_SETLKW, &lk); // 若被鎖住,會在這裡等一旦上一行解除阻塞(鎖可取得),就印出「拿到鎖!」,並
F_UNLCK解除,再close(fd)
要點:
- 因為
locker先用fd1取得了寫鎖,所以waiter會在F_SETLKW卡住 - 等到
locker關掉fd2的瞬間(雖然鎖並不是經由fd2取得),locker對此檔的所有鎖都被釋放,waiter就能立刻拿到鎖
// waiter.c
#define _XOPEN_SOURCE 700
#include <errno.h>
#include <fcntl.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
int main(int argc, char **argv)
{
const char *path = (argc > 1) ? argv[1] : "lockdemo.tmp";
int fd = open(path, O_RDWR);
if (fd < 0) {
perror("waiter: open");
return 1;
}
struct flock lk = {.l_type = F_WRLCK, .l_whence = SEEK_SET, .l_start = 0, .l_len = 0};
puts("waiter: trying to acquire F_WRLCK (will block until available)...");
if (fcntl(fd, F_SETLKW, &lk) == -1) {
perror("waiter: fcntl(F_SETLKW)");
return 1;
}
puts("waiter: acquired lock!");
// Clean up
lk.l_type = F_UNLCK;
if (fcntl(fd, F_SETLK, &lk) == -1)
perror("waiter: unlock");
close(fd);
return 0;
}Fast & Slow System Calls
- 快速系統呼叫(Fast system calls)
- 在可預期時間內完成、不受外部資源阻塞的呼叫
- 例:從本機磁碟讀取檔案
- (問題:是否「一定不阻塞」取決於實作與狀況,本機 I/O 仍可能因頁快取未命中或裝置壅塞而延遲,這裡屬概念化分類)
- 慢速系統呼叫(Slow system calls)
- 可能無限期等待才完成(甚至永遠阻塞)
- 例:從終端裝置或網路裝置讀取、對 pipe(第 15 章)讀寫、等待網路連線等
Blocking v.s. Nonblocking I/O
- 阻塞式 I/O(Blocking I/O)
- I/O 函式要等到操作完成才返回(典型的慢速系統呼叫)
- 非阻塞式 I/O(Nonblocking I/O)
- 讓我們發出 I/O 操作(如 open/read/write),並在不等待的情況下盡快返回
- 注意:若操作此刻無法完成,呼叫會立刻以錯誤返回
- 例:非阻塞讀取會在不掛起行程的前提下,盡可能讀到可得的位元組數
- 可把某個 file descriptor 設為非阻塞:
- 兩種方式:
open()(帶O_NONBLOCK)或fcntl(F_SETFL)設定O_NONBLOCK
- 兩種方式:
- 讓我們發出 I/O 操作(如 open/read/write),並在不等待的情況下盡快返回
Nonblocking I/O Code Example
下例程式會從 stdin 讀取最多 500,000 位元組,並嘗試把它寫到 stdout(我們會先把 stdout 設為非阻塞的)。 寫出的動作在一個迴圈裡執行,而每次 write 的結果都會印到 stderr 中:
#include <errno.h>
#include <fcntl.h>
char buf[500000];
int main(void)
{
int ntowrite, nwrite;
char *ptr;
ntowrite = read(STDIN_FILENO, buf, sizeof(buf));
fprintf(stderr, "read %d bytes\n", ntowrite);
set_fl(STDOUT_FILENO, O_NONBLOCK); /* set nonblocking */
ptr = buf;
while (ntowrite > 0) {
errno = 0;
nwrite = write(STDOUT_FILENO, ptr, ntowrite);
fprintf(stderr, "nwrite = %d, errno = %d\n", nwrite, errno);
if (nwrite > 0) {
ptr += nwrite;
ntowrite -= nwrite;
}
}
clr_fl(STDOUT_FILENO, O_NONBLOCK); /* clear nonblocking */
exit(0);
}如果 stdout 是一般檔案(regular file),我們預期只會呼叫一次 write:
$ ls -l /etc/services <-- print file size
-rw-r--r-- 1 root 677959 Jun 23 2009 /etc/services
$ ./a.out < /etc/services > temp.file <-- try a regular file first
read 500000 bytes
nwrite = 500000, errno = 0 <-- a single write
$ ls -l temp.file <-- verify size of output file
-rw-rw-r-- 1 sar 500000 Apr 1 13:03 temp.file但如果 stdout 是終端機(terminal),我們預期 write 有時會回傳「只寫入部分位元組數」,有時則回傳錯誤。 結果如下所示:
$ ./a.out < /etc/services 2>stderr.out <-- output to terminal
... <-- lots of output to terminal ...
$ cat stderr.out
read 500000 bytes
nwrite = 999, errno = 0
nwrite = -1, errno = 35
nwrite = -1, errno = 35
nwrite = -1, errno = 35
nwrite = -1, errno = 35
nwrite = 1001, errno = 0
nwrite = -1, errno = 35
nwrite = 1002, errno = 0
nwrite = 1004, errno = 0
nwrite = 1003, errno = 0
nwrite = 1003, errno = 0
nwrite = 1005, errno = 0
nwrite = -1, errno = 35 <-- 61 of these errors
...
nwrite = 1006, errno = 0
nwrite = 1004, errno = 0
nwrite = 1005, errno = 0
nwrite = 1006, errno = 0
nwrite = -1, errno = 35 <-- 108 of these errors
...
nwrite = 1006, errno = 0
nwrite = 1005, errno = 0
nwrite = 1005, errno = 0
nwrite = -1, errno = 35 <-- 681 of these errors
... <-- and so on...
nwrite = 347, errno = 0在這套系統上,errno 的 35 代表 EAGAIN。 終端機驅動程式能接受的資料量會因系統而異,結果也會因你登入系統的方式而不同:如使用系統主控台、實體(硬接線)終端機,或是透過偽終端(pseudo terminal)的網路連線。 如果你的終端機上跑著視窗系統,你同樣是經過一個偽終端裝置
由於 stdout 被設為非阻塞的,且終端的輸出佇列容量有限,write 常常只寫出部分資料(回傳小於要求的位數),或直接以 -1 返回並設 errno=EAGAIN
在這個例子裡,程式發出了超過 9,000 次的 write 呼叫,儘管實際上只需要 500 次就能把資料輸出完畢。 其餘的呼叫都只回傳錯誤。 這種迴圈稱為輪詢(polling),在多使用者系統上是浪費 CPU 時間的
因為是非阻塞的,程式會反覆迴圈嘗試:每次把成功寫出的那一段前移指標、減少剩餘位數,遇到 EAGAIN 則立即返回、下一輪再嘗試
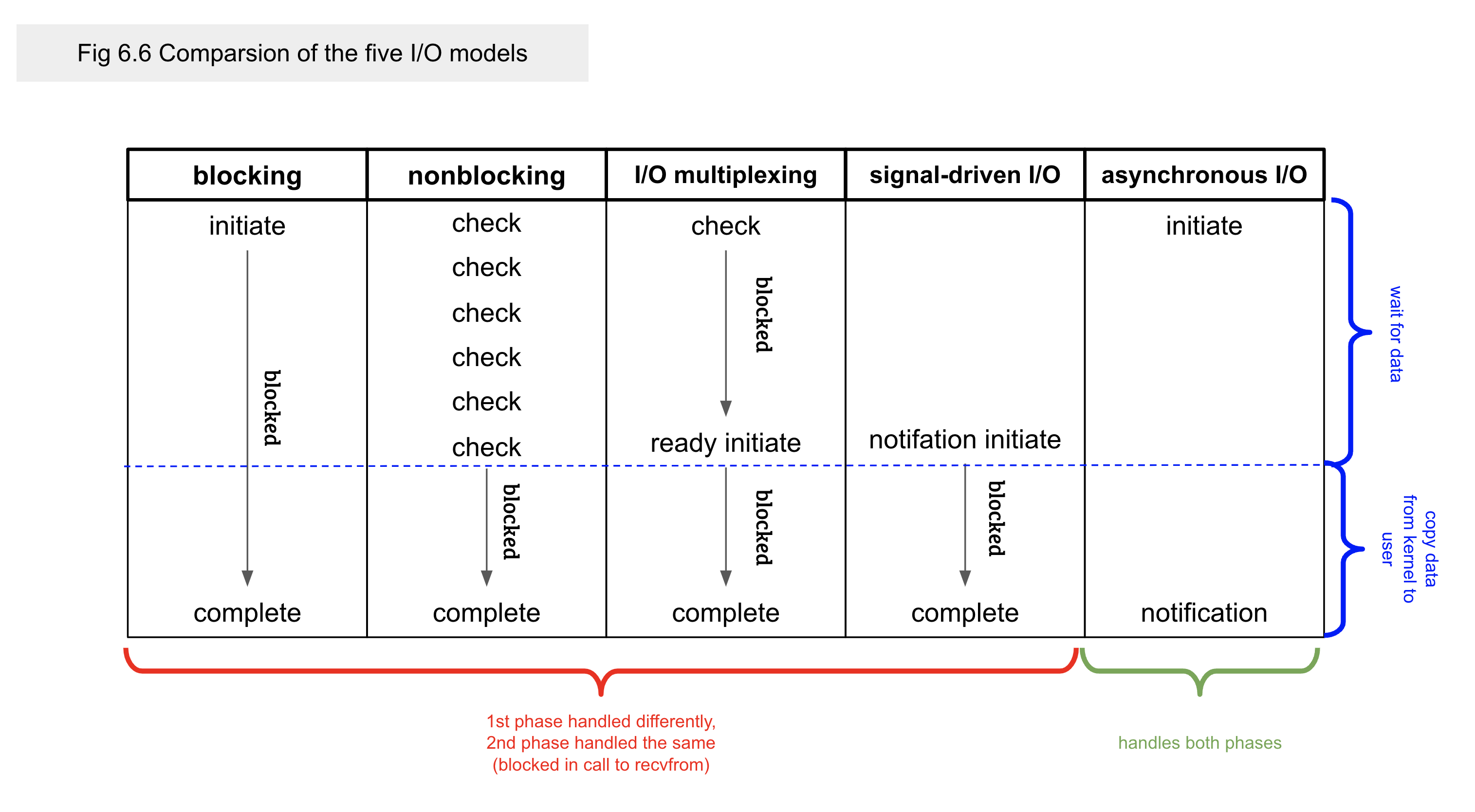
圖下方小表對照了阻塞與非阻塞:
- 阻塞:一次呼叫等到完成
- 非阻塞:多次「檢查/嘗試」,直到完成
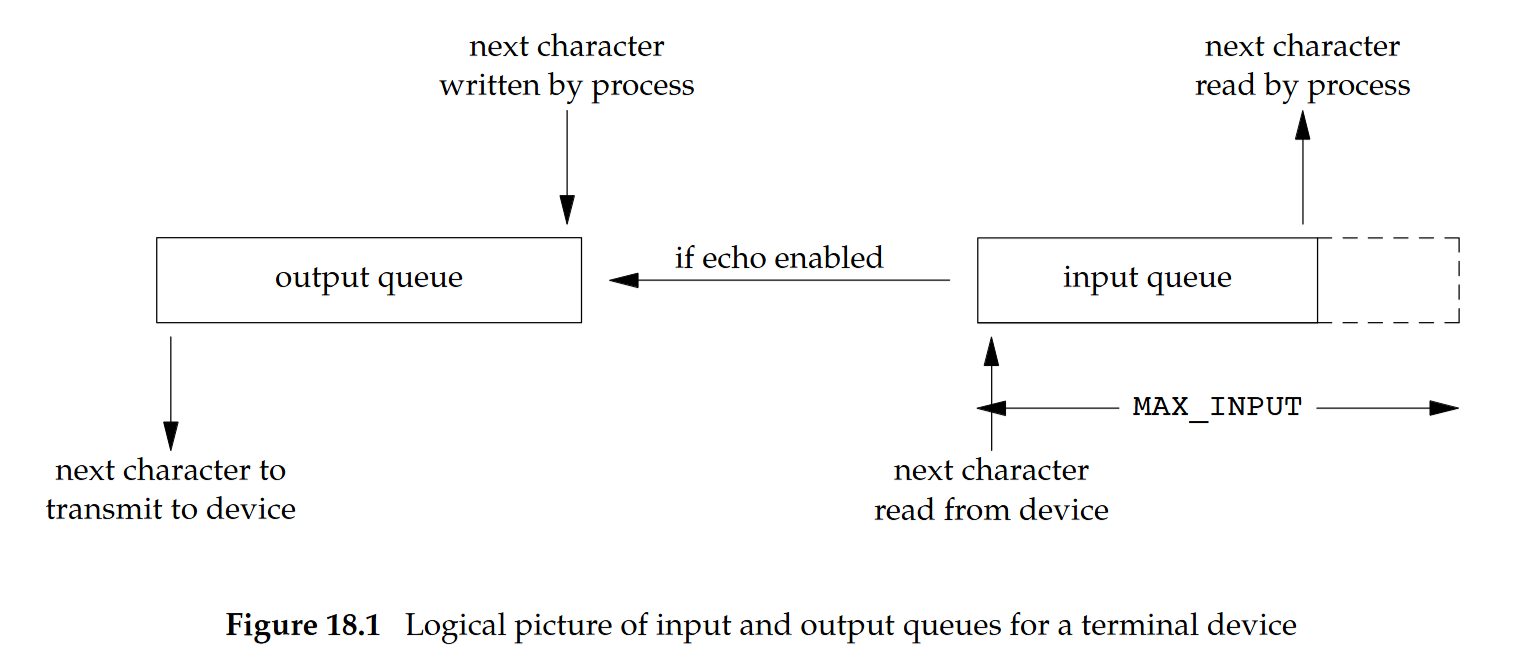
Terminal Device
- 每個終端裝置都有一個輸入佇列與一個輸出佇列
- shell 會把標準輸入重新導向到終端
- 輸入佇列大小受
MAX_INPUT限制 - 當輸出佇列已滿時:
- 阻塞模式:行程會被進入睡眠,直到佇列有空間(行程什麼也不做)
- 非阻塞模式:輪詢(polling),程式在迴圈中反覆檢查是否可以輸出
- 在多使用者系統上常浪費 CPU,因為大多時候佇列仍是滿的、沒有事可做
處理並行 I/O(Handle Concurrent I/Os)
Telnet Process
n = read(STDIN_FILENO, buf, BUFSIZ);
...
n = read(network_fd, netbuf, BUFSIZ);
...Telnet 行程會從 stdin 讀取並寫到網路(到 telnet 伺服器 PTT),Telnet 行程也會從網路讀取並寫到 stdout
問題:使用 blocking I/O 的優缺點是什麼?
假設讀取兩個 file descriptor:stdin 與網路輸入
n = read(STDIN_FILENO, buf, BUFSIZ); /* block */
...
n = read(network_fd, netbuf, BUFSIZ); /* block */
...此處的問題是 blocking I/O 無法同時處理多個 I/O 來源(檔案/Socket 等 descriptor)。 必須等其中一個完成才能處理下一個,對任何一個 descriptor 的 I/O 都可能造成阻塞,效能不佳
想法 1:multi-process
Telnet Process1
n = read(STDIN_FILENO, buf, BUFSIZ); /* block */
...
Telnet Process2
n = read(network_fd, netbuf, BUFSIZ); /* block */
...- 執行兩個行程,讓每個行程各自做一個 blocking 讀取
- 問題:分配行程浪費資源,行程間通訊與狀態同步需要額外負擔
想法 2:nonblocking I/O(輪詢)
- 將兩個要讀取的 I/O descriptor 都設為非阻塞:對某個 file descriptor,如果有資料,就讀取並處理,如果沒有資料,
read會立即返回,對 I/O 做輪詢(polling) - 問題:如果大多數時間都無法進行該操作,會浪費 CPU 資源
/* Telnet Process */
while (1) { /* STDIN 與 network_fd 已設為 NONBLOCK */
n = read(STDIN_FILENO, buf, BUFSIZ);
/* 如果沒有讀到資料,先做別的事,然後再檢查 STDIN */
...
n = read(network_fd, netbuf, BUFSIZ);
/* 如果沒有讀到資料,先做別的事,然後再檢查 network_fd */
...
}想法 3:I/O Multiplexing(多工)
- 使用
select()或poll() - 目標:避免為輪詢而忙迴圈,同時處理多個 I/O 來源
- I/O 多工通常用在:
- 應用程式需要同時處理多個 file descriptor,例如檔案與網路 I/O(socket)descriptor
- 對任何一個 descriptor 的 I/O(例如 read/write)都可能導致阻塞
I/O Multiplexing
以下節錄自 select、poll、epoll 之間的區別總結[整理]:
select、poll、epoll都是 IO 多工的機制。 I/O 工通過一種機制,可以監視多個描述符,一旦某個描述符就緒(一般是讀取就緒或寫入就緒),能夠通知程式進行對應的讀寫操作。 但select、poll、epoll本質上都是同步 I/O,因為他們都需要在讀寫事件就緒後自己負責進行讀寫,也就是說這個讀寫過程是阻塞的,而異步 I/O 則無需自己負責進行讀寫,異步 I/O 的實現會負責把資料從 kernel 複製到 user space
對於同步、非同步,以下節錄自 Study Notes - I/O Models:
阻塞 (Blocking) 與非阻塞 (Non-Blocking) 描述的是「請求」在等待結果時的「狀態」
- 阻塞 (Blocking):調用的程序或者應用程式發起請求,在獲得結果之前,調用方的程序會懸 (Hang) 住不動> 無法回應,直到獲得結果
- 非阻塞 (Non-Blocking):概念與阻塞相同,但是調用方不會因為等待結果,而懸著不動。 後續通常透過輪> 機制 (Polling) 機制取得結果
同步 (Synchronous) 與非同步 (Asynchronous) 描述的是:使用者執行緒與 Kernel 的通訊模式:
- 同步 (Synchronous):使用者執行緒發出 I/O 請求後,要等待、或者輪詢 Kernel I/O 的操作完成後,才> 繼續執行
- 等待 Kernel 回覆:Blocking IO,縮寫成 BIO
- 輪詢類似於 Non-Blocking IO,縮寫成 NIO
- 非同步 (Asynchronous):或稱異步,使用者執行緒發出 I/O 請求後仍然繼續執行下一個操作,當 Kernel> I/O 操作結束後,會通知執行緒,或者呼叫 callback 函數
同步中文的意思很容易誤解為,很多事同時做,實際上是事情有先後關係的概念,也就是「有序性> (oredered)」; 而非同步才是類似於很多事情在同一個時間一起發動,他是「無序性 (non-ordered)」
I/O Multiplexing:select
select 讓程序能夠指示 kernel 等待多個事件中的任何一個發送,並且只在有一個或多個事件發生,或經歷一段指定的時間後才會喚醒該程序。 函數原型如下:
#include <sys/select.h>
// 回傳:就緒的 descriptor 數量,在任何 descriptor 就緒前超時則回傳 0,錯誤回傳 −1
int select(int nfds, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, struct timeval *timeout);select()的參數意義:- 我們關心哪些 descriptor
- 對每個 descriptor 關心哪些條件:從某個 descriptor 讀、往某個 descriptor 寫、或該 descriptor 的異常狀態
- 要等多久:永久等待、等待固定時間,或完全不等待
select()的參數細節:- 我們關心哪些 descriptor:
nfds,設為三個集合中編號最高的 file descriptor + 1。 核心會檢查每個集合中到這個上限為止的 descriptor - 對每個 descriptor 關心哪些條件:
readfds、writefds、exceptfds,指向各條件的 descriptor 集合(bitmap)的指標。 用來指定我們要讓 kernel 測試讀取、寫入和異常條件的描述符,如果對某一個的條件不感興趣,可以把它設為空指標 - 要等多久:
timeout,等待時間
- 我們關心哪些 descriptor:
fd_set 型別代表的是 descriptor 的集合,三個 descriptor 的集合(readfds、writefds、exceptfds)以該型別儲存,一個 descriptor 對應到當中的一個位元
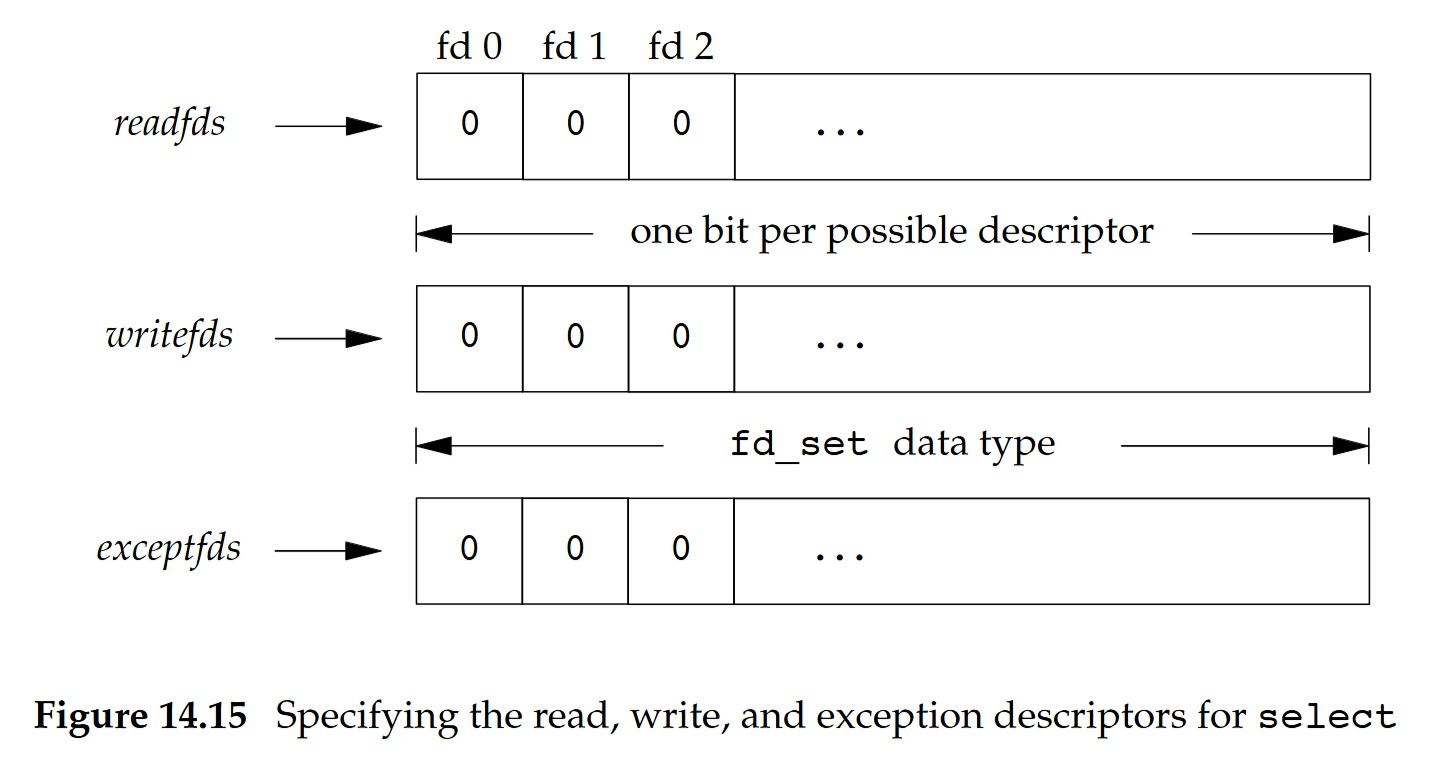
fd_set 內的 descriptor 可以利用以下四個輔助巨集/函式來進行設定:
#include <sys/select.h>
int FD_ISSET(int fd, fd_set *fdset); // 檢查集合中指定的檔案描述符是否可以讀寫
void FD_CLR (int fd, fd_set *fdset); // 將一個給定的檔案描述符從集合中刪除
void FD_SET (int fd, fd_set *fdset); // 將一個給定的檔案描述符加入集合中
void FD_ZERO (fd_set *fdset); // 清空集合
// 回傳值:若 fd 在集合中則非零,否則為 0- 從
select()返回時,作業系統核心會告訴我們:- 就緒的 descriptor 總數(三個集合的總和,亦即
select()的回傳值) - 哪些 descriptor 在對應條件下已就緒(核心會更新
readfds、writefds、exceptfds這三個集合)
- 就緒的 descriptor 總數(三個集合的總和,亦即
- 根據 (2) 我們知道:
- 若某個 descriptor 出現在 read 集合或 write 集合,對它做讀/寫將不會阻塞
- 若某個 descriptor 出現在 exception 集合,代表該 descriptor 有待處理的異常狀態
select 的正回傳值是三個集合中就緒的 descriptor 數量之總和,若同一個 descriptor 同時可讀又可寫,會被計到兩次
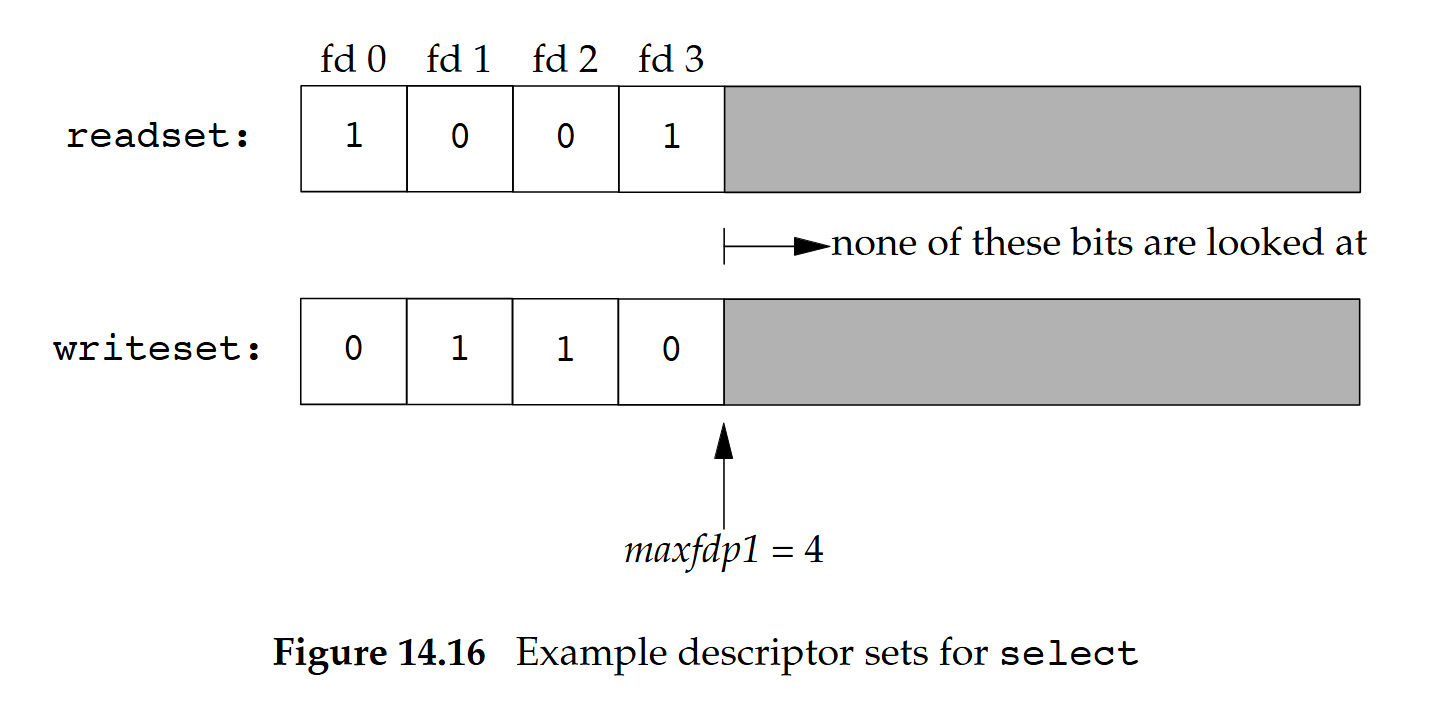
範例
如果我們寫:
fd_set readset, writeset;
FD_ZERO(&readset);
FD_ZERO(&writeset);
FD_SET(0, &readset);
FD_SET(3, &readset);
FD_SET(1, &writeset);
FD_SET(2, &writeset);
select(4, &readset, &writeset, NULL, NULL);則這兩個 descriptor set 看起來會如下圖:
範例 2
看以下程式,考慮為什麼要 memcpy():
int main()
{
int i;
struct timeval timeout;
struct fd_set master_set, working_set;
char buf[1024];
FD_ZERO(&master_set);
FD_SET(0, &master_set);
timeout.tv_sec = 5;
timeout.tv_usec = 0;
i = 0;
while (1)
{
memcpy(&working_set, &master_set, sizeof(master_set));
select(1, &working_set, NULL, NULL, &timeout);
if (FD_ISSET(0, &working_set))
{
fgets(buf, sizeof(buf), stdin);
fputs(buf, stdout);
}
printf("iteration: %d\n", i++);
}
return 0;
}這是因為作業系統會在這兩個地方更新 working_set:
FD_ZERO(&master_set);
FD_SET(0, &master_set);與
if (FD_ISSET(0, &working_set))所以你需要每次都先備份再還原!
其他
- 我們可以把
nfds設為FD_SETSIZE(定義於<sys/select.h>,在 Linux 設為 1024) - 若不關心某一類條件,對應的 descriptor 集合指標可以是
NULL,若三個指標都為NULL,select就會變成一個比sleep更高精度(微秒)的計時器// 下面這個 select 會依照給定的 timeval 休眠 int totalfds = select(0, NULL, NULL, NULL, &timeval);
關於 select 的參數 timeout 的特殊情況:
timeout的參數是 timeval 結構,指定select()應阻塞的時間區間。select()會阻塞直到下列其中之一發生:- 有某個 file descriptor 就緒
- 呼叫被訊號處理器中斷
timeout到期
timeout區間會被向上取整到系統時鐘的粒度,排程延遲也可能使實際阻塞時間略為超過- 若
timeval的兩個欄位皆為 0,select()會立刻返回(可用於 polling) - 若
timeout為NULL,select()會無限期阻塞,直到有 file descriptor 就緒
I/O Multiplexing:poll
#include <poll.h>
// 回傳值:就緒的 descriptor 數量;逾時回傳 0;發生錯誤回傳 -1
int poll(struct pollfd fdarray[], nfds_t nfds, int timeout);struct pollfd {
int fd; // 要檢查的 file descriptor;若 < 0 則忽略此項
short events; // 呼叫端關心的事件(events)
short revents; // 實際發生在該 fd 的事件(由核心填入)
};poll與select類似,但在傳遞引數的程式介面上不同:nfds:指定fdarray陣列中的項目數量- 以
pollfd結構組成的陣列來描述要監看的 descriptor 與關心的條件- 呼叫端在
events欄位設定關心的事件,這是位元遮罩,更多細節可參考下圖(14.17) - 核心在返回時會填寫
revents,指出每個 descriptor 實際發生了哪些事件,這同樣是位元遮罩
- 呼叫端在
timeout:在解除行程等待前要等多久(毫秒)- -1 表示無限期等待,0 表示不等待,大於 0 表示等待對應的毫秒數
- 時間到了之後,無論 I/O 是否準備好,
poll都會回傳
| Name | Input to events? | Result from revents? | Description |
|---|---|---|---|
| POLLIN | ● | ● | 除了高優先權資料以外的資料可在不阻塞的情況下讀取(等同於 POLLRDNORM | POLLRDBAND)。 |
| POLLRDNORM | ● | ● | 一般資料可在不阻塞的情況下讀取。 |
| POLLRDBAND | ● | ● | 優先權資料可在不阻塞的情況下讀取。 |
| POLLPRI | ● | ● | 高優先權資料可在不阻塞的情況下讀取。 |
| POLLOUT | ● | ● | 一般資料可在不阻塞的情況下寫入。 |
| POLLWRNORM | ● | ● | 同 POLLOUT。 |
| POLLWRBAND | ● | ● | 優先權資料可在不阻塞的情況下寫入。 |
| POLLERR | ● | 發生錯誤。 | |
| POLLHUP | ● | 發生掛斷。 | |
| POLLNVAL | ● | 該 descriptor 沒有參照到任何已開啟的檔案。 |
(From APUE 3rd Edition:Figure 14.17)
以下節錄自 IO 多路復用之 poll 總結:
使用
poll()和select()不一樣,你不需要明確地請求異常狀況報告
POLLIN | POLLPRI等價於select()的讀取事件POLLOUT | POLLWRBAND等價於select()的寫事件POLLIN等價於POLLRDNORM | POLLRDBANDPOLLOUT則等價於POLLWRNORM例如,要同時監視一個檔案描述子是否可讀和可寫,我們可以設定
events為POLLIN | POLLOUT。 當poll返回時,我們可以檢查revents中的標誌,對應於文件描述符請求的events結構體。 如果POLLIN事件被設置,則檔案描述子可以被讀取而不阻塞。 如果POLLOUT被設置,則檔案描述符可以寫入而不導致阻塞這些標誌並不是互斥的,它們可能被同時設置,表示這個檔案描述符的讀取和寫入操作都會正常返回而不阻塞。
I/O Multiplexing:select v.s. poll
| select | poll | |
|---|---|---|
| 核心對輸入引數的更新方式 | 更新 fd_set 集合 | 更新 revents 欄位(不是 events) |
| 支援的條件種類 | 讀、寫、錯誤三種類型 | 超過三種類型的事件 |
- 其他替代方案
pselect:提供奈秒等級的逾時設定與同時套用訊號遮罩epoll:在速度與可擴展性上表現良好
Intro to Networking
IP、TCP/UDP 與 port number
- IP:用來指定機器,本身以 IP 位址作為定址方式
- TCP / UDP:建構在 IP 之上,以連接埠(port)進行定址
- TCP:
- 常見於 FTP、Telnet、SMTP
- 特性:
- 以連線為基礎(connection-based)
- 在傳資料前,雙方先用「三向握手」建立一條連線(TCP 連線有狀態:序號、視窗大小等)。 之後資料都走在這條連線上,直到其中一方關閉。
- 可靠(reliable)
- 協定內建確認與重傳機制,保證「不重複、不遺失、按順序」把位元組送到對方,出問題就回報錯誤(例如連線中斷)。 應用程式不必自己做 ACK/重傳。
- 位元組串流(byte stream)
- TCP 看起來像一條連續的位元組管道,沒有「訊息邊界」這個概念。 你
write()了 100 與 50 與 50,不保證對方會用三次read()分別讀到 100/50/50,可能一次讀到 200,也可能多次分段。 所以若你需要訊息邊界,必須自己在資料裡加長度欄位或分隔符號
- TCP 看起來像一條連續的位元組管道,沒有「訊息邊界」這個概念。 你
- 以連線為基礎(connection-based)
- UDP:
- 常見於 NFS、TFTP
- 特性:
- 無連線(connectionless)
- 不需要握手,每次送資料都獨立成一個封包,帶著目的位址與連接埠送出去。 核心幾乎不維持狀態,延遲與開銷都更小。
- 不可靠(unreliable)
- 協定本身不保證送達、不保證順序、也不會自動重傳,封包可能遺失、重複、或顛倒順序。 要可靠就得由應用層自己做(加序號、ACK/重傳等)。
- 資料報(datagram)
- 有「訊息邊界」:你
sendto()一個封包,對方recvfrom()就會拿到「正好那一個封包」(要嘛整個收到、要嘛整個掉了,若接收緩衝太小,會被截斷且殘餘部分丟失)。 不會像 TCP 那樣把多次寫入自動黏在一起。
- 有「訊息邊界」:你
- 無連線(connectionless)
- TCP:
- 連接埠號(port number):16 位元整數,在同一台機器上具唯一性
- Unix 中的連接埠號:小於 1024 的連接埠會保留給 root 使用(用來承載系統服務)
- 在網路上為機器定址時使用的是 IP 位址
- 為行程定址時使用的是連接埠號
- 將「IP 位址」加上「連接埠號」就可以組成所謂的「socket 位址」
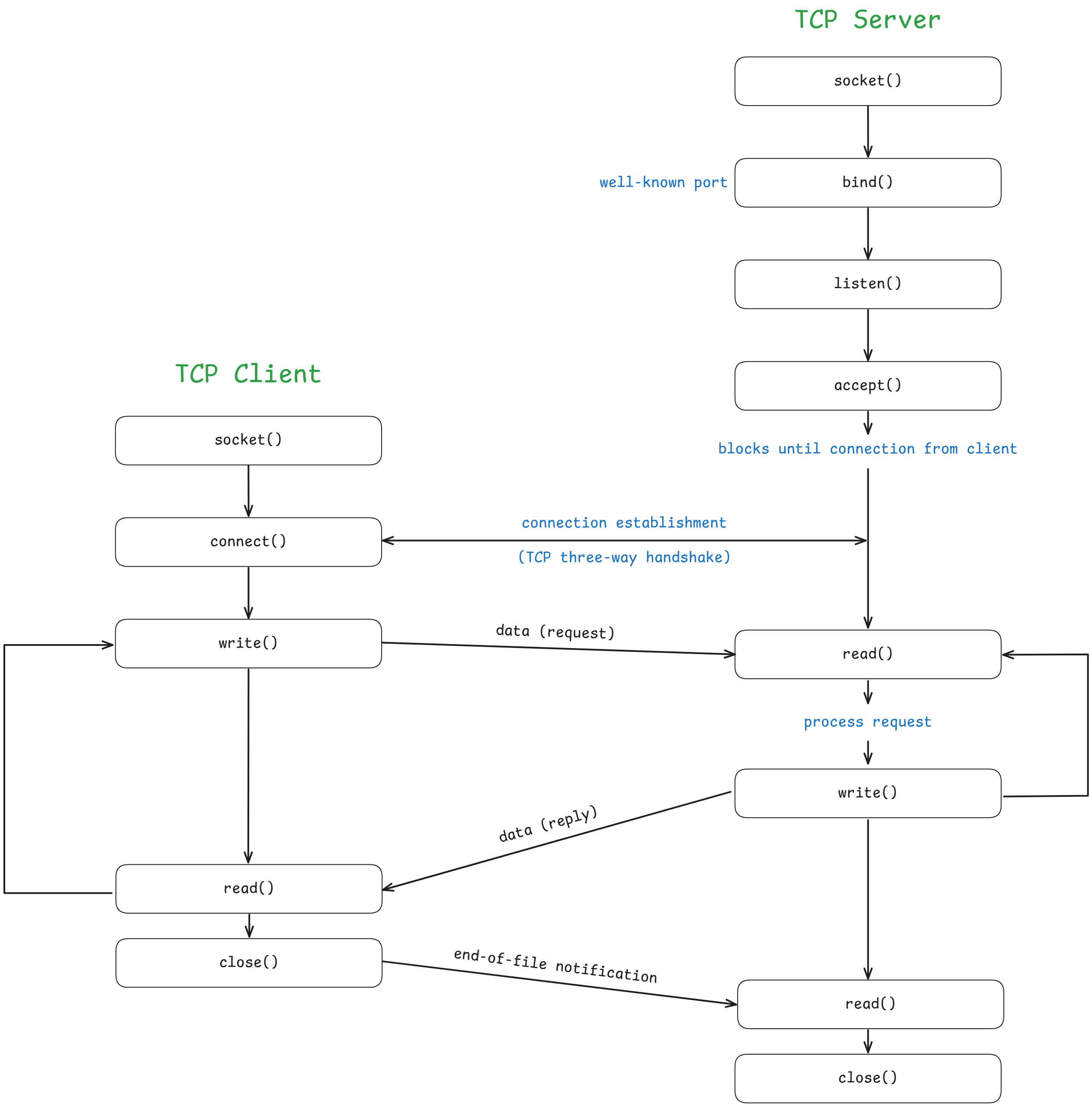
底下是 TCP Client/Server Programming Model 的示意圖:
Sockets
- Socket 讓位在不同電腦(連到同一個網路)的行程端點可以彼此通訊
- POSIX.1 規範了 socket API
- 對作業系統核心來說,socket 就是通訊的端點(endpoint)
- 應用程式透過 socket descriptor 來存取 socket
- Unix 系統把 socket descriptor 實作成 file descriptor
- 讓用戶端與伺服器可以用這些 socket 的 file descriptor 來對網路進行讀寫
- 一般檔案 I/O 與 socket I/O 之間的主要差別,在於應用程式如何「開啟」這些 descriptor 或檔案
Socket Primitives
// 成功時回傳一個 socket descriptor(socketfd),錯誤回傳 -1
int socket(int domain, int type, int protocol);socket():建立一個通訊端點domain設為AF_INET(IPv4 協定)type設為SOCK_DGRAM(UDP) 或SOCK_STREAM(TCP)protocol設為 0(讓核心依型態挑對應的協定號IPPROTO_UDP或IPPROTO_TCP)
// 成功回傳 0,錯誤回傳 -1
int bind(int socketfd, struct sockaddr *addr, int addrlen);bind():把名稱或位址綁定到一個 socketsocketfd:由socket()回傳的 socket descriptoraddr:socket 位址addrlen:sizeof(struct sockaddr)
struct sockaddr_in {
unsigned short sin_family; /* address family (always AF_INET) */
unsigned short sin_port; /* port num in network byte order */
struct in_addr sin_addr; /* IP addr in network byte order */
unsigned char sin_zero[8]; /* pad to sizeof(struct sockaddr) */
};struct sockaddr_in是 IPv4 專用的 socket 位址結構sin_family必須設為AF_INETsin_port與sin_addr需要用「網路位元組序」(大端序),因此常搭配htons()、htonl()等轉換。sin_zero只是填充欄位,讓大小與通用的struct sockaddr對齊
// returns 0 if OK, −1 on error
int listen(int sockfd, int backlog);listen():在一個 socket 上開始監聽連線backlog:我們要允許排隊的待處理連線數量
// returns a new file (socket) descriptor if OK, −1 on error
int accept(int socketfd, struct sockaddr *addr, socklen_t *len);accept():在監聽的 socket 上接受一條連線,從等待佇列取出第一個請求,建立一個新的已連線 socket,並回傳指向它的新 file descriptor。 原本的監聽 socket 不受影響accept()會阻塞呼叫端直到有連線到來addr:系統會在這裡寫入對端的 socket 位址
// returns 0 if OK, −1 on error
int connect(int socketfd, struct sockaddr *addr, int addrlen);connect():把sockfd對應的 socket 連到serv_addr指定的位址(參數形式與bind()類似),用戶端會呼叫它- 可以使用
close()來關閉一個已開啟的socketfd
Reads and Writes on Sockets
- 位元組串流(byte stream)是雙向的
- 用戶端與伺服器都能在同一個 file descriptor 上讀與寫
- 可以只關閉單一方向
- 讀取可能會阻塞
- 從檔案讀取時可能:
- 成功
- 遇到 EOF(檔案結尾,回傳 0)
- 從 socket 讀取會等待直到:
- 收到網路資料(回傳值大於 0)
- 連線被關閉(回傳值等於 0)
- 發生網路錯誤(回傳值小於 0)
- 從檔案讀取時可能:
- 對 socket 寫入可能:
- 把資料送到網路(回傳值大於 0)
- 發現連線已關閉(回傳值等於 0)
- 造成網路錯誤(回傳值小於 0)
- 當緩衝區已滿時,寫入可能會立即返回或被阻塞